Redis汇总及实战
初识redis
在学习Redis之前,我们需要知道SQL和NoSQL,即关系型数据库和非关系型数据库。
那么它们两者之间有什么联系。
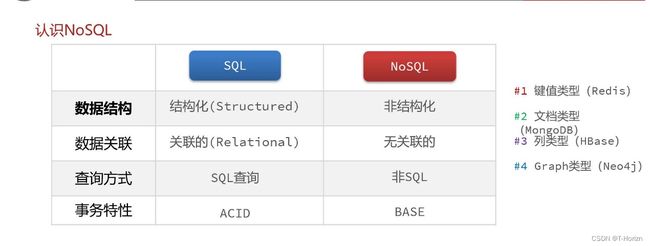
大致了解NOSQL后,我们再来认识Redis。
Redis诞生于2009年全称是Remote Dictionary Server,远程词典服务器,是一个基于内存的键值型NoSQL数据库。
特点与优点 :
- 键值(key-value)型,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性。即它的所有命令串行执行,因此是线程安全的。
在此需要注意:Redis6.0之后的版本在对网络应用请求处理上为多线程,其他目前仍为单线程。
③低延迟,速度快(基于内存,即数据都在内存中,内存的读写速度极高、IO多路复用,大大提高了整个服务的吞吐能力、良好的编码,redis基于c语言编写,)。
④支持数据持久化(会定期将数据从内存持久化到磁盘)
⑤支持主从集群、分片集群(从节点可以备份主节点的数据,可以做读写分离,大大提高效率)
⑥支持多语言客户端(即支持多种语言,例如c++,Java等)。
大致了解了redis是什么以及它的特点之后 ,接下来我们就应该学习去如何使用,但在使用之前我们需要先安装它。
Redis安装就不多赘述 ,网上有许多教程,不过我们仍需要知道Redis的作者并未编写windows版,因此我们一般选择在Linux上安装。在此需要注意,Win11下的VMware版本须在16.0.0以上,否则可能会出现蓝屏等问题。此外,GitHub上也有Windows版本的redis,但是其redis版本较低,在后续使用上可能会有部分功能不能满足需求。
在一系列安装及配置之后,我们还需要安装一个图形化桌面客户端 RESP,来方便使用redis。
完成Redis学习的前置条件后,首先我门来学习redis的数据结构。

这些数据结构只是常用的,除此之外Redis中还有多种数据结构。
接下来了解一下redis的通用命令。

接下来对常用数据结构进行介绍。
- String类型

String的常见命令:

在我们的初步使用之后,会发现Redis没有类似MySQL中的Table的概念,我们该如何区分不同类型的key呢?
比如,需要存储用户、商品信息到redis,有一个用户id是1,有一个商品id恰好也是1。
这就需要讲到Redis key的结构。

- Hash类型


- List类型

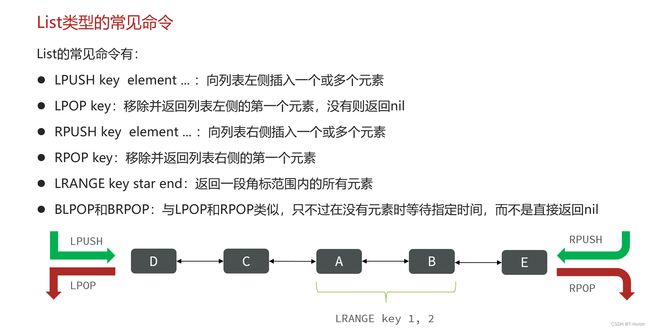
在此需要思考:
如何利用List结构模拟一个栈?
- 入口和出口在同一边
如何利用List结构模拟一个队列?
- 入口和出口在不同边
如何利用List结构模拟一个阻塞队列?
- 入口和出口在不同边
- 出队时采用BLPOP或BRPOP
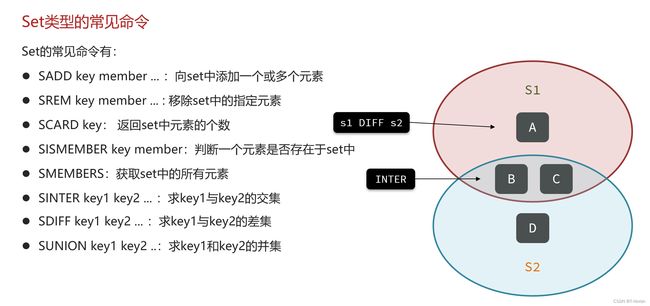
- Set类型

- SortedSet类型
Redis的SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但底层数据结构却差别很大。SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加 hash表。
SortedSet具备下列特性:
可排序
元素不重复
查询速度快
因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能。
SortedSet的常用命令。
SortedSet的常见命令有:
- ZADD key score member:添加一个或多个元素到sorted set ,如果已经存在则更新其score值
- ZREM key member:删除sorted set中的一个指定元素
- ZSCORE key member : 获取sorted set中的指定元素的score值
- ZRANK key member:获取sorted set 中的指定元素的排名
- ZCARD key:获取sorted set中的元素个数
- ZCOUNT key min max:统计score值在给定范围内的所有元素的个数
- ZINCRBY key increment member:让sorted set中的指定元素自增,步长为指定的increment值
- ZRANGE key min max:按照score排序后,获取指定排名范围内的元素
- ZRANGEBYSCORE key min max:按照score排序后,获取指定score范围内的元素
- ZDIFF、ZINTER、ZUNION:求差集、交集、并集
注意:所有的排名默认都是升序,如果要降序则在命令的Z后面添加REV即可
redis的java客户端
在Redis官网中提供了各种语言的客户端,地址:https://redis.io/resources/clients/
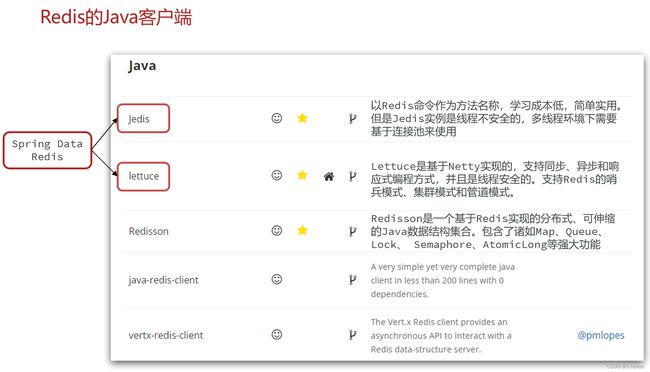
我们先来快速使用Jedis


其中,"192.168.150.101"IP地址,6379为端口号,"123321"为redis密码。
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此推荐大家使用Jedis连接池代替Jedis的直连方式。
public class JedisConnectionFactory {
private static final JedisPool jedisPool;
static {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
// 最大连接
jedisPoolConfig.setMaxTotal(8);
// 最大空闲连接
jedisPoolConfig.setMaxIdle(8);
// 最小空闲连接
jedisPoolConfig.setMinIdle(0);
// 设置最长等待时间, ms
jedisPoolConfig.setMaxWaitMillis(200);
jedisPool = new JedisPool(jedisPoolConfig, "192.168.150.101", 6379,
1000, "123321");
}
// 获取Jedis对象
public static Jedis getJedis(){
return jedisPool.getResource();
}
}
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis,官网地址:Spring Data Redis
- 提供了对不同Redis客户端的整合(Lettuce和Jedis)
- 提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK、JSON、字符串、Spring对象的数据序列化及反序列化
- 支持基于Redis的JDKCollection实现
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中:

SpringDataRedis的快速入门。
SpringDataRedis的使用步骤:
- 引入spring-boot-starter-data-redis依赖
- 在application.yml配置Redis信息
spring:
redis:
host: 127.0.0.1#主机IP地址
port: 6379
password: 123321#没有密码则不写此行
lettuce:
pool:
max-active: 8 # 最大连接
max-idle: 8 # 最大空闲连接
min-idle: 0 # 最小空闲连接
max-wait: 100 # 连接等待时间
- 注入RedisTemplate。
RedisTemplate可以接收任意Object作为值写入Redis,只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化,得到的结果是这样的:

它有一定的缺点:
- 可读性差
- 内存占用较大
我们也可以自定义RedisTemplate的序列化方式。
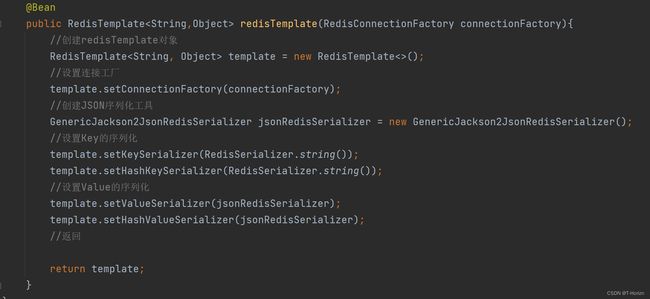
尽管JSON序列化方式可以满足需求,但是我们发现:为了在反序列化时知道对象的类型,JSON序列化器会将类的class类型写入json结果中,存入Redis,会带来额外的内存开销。
为了节省内存空间,我们并不会使用JSON序列化器来处理value,而是统一使用String序列化器,要求只能存储String类型的key和value。当需要存储Java对象时,手动完成对象的序列化和反序列化。
Spring默认提供了一个StringRedisTemplate类,它的key和value的序列化方式默认就是String方式。省去了我们自定义RedisTemplate的过程:
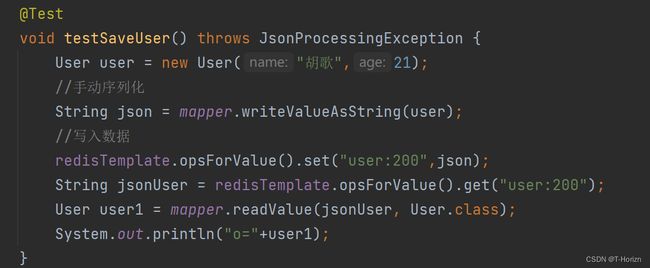
得到结果:

至此,初始Redis就结束了,学习了这个部分,我们可以知道Redis是什么,有什么特点,以及了解它的基本使用。
redis实战
在此完成的项目为黑马点评
该项目的技术栈:ngnix+redis+mysql+springboot+mybatisplus
此外,此项目中还使用Postman进行接口测试,使用了jemeter模拟高并发,进行压力测试。使得项目更贴近真实。
首先我们需要导入项目,该项目地址:https://gitee.com/huyi612/hm-dianping
导入后,修改yml配置,导入依赖等等,此处不再赘述。
- 短信登录
1.基于session实现登录
实现登录主要分为三个模块:发送短信验证码,短信验证码的登录和注册,校验登录状态。

发送验证码:
@Override
public Result sendCode(String phone, HttpSession session) {
// 1.校验手机号
if (RegexUtils.isPhoneInvalid(phone)) {
// 2.如果不符合,返回错误信息
return Result.fail("手机号格式错误!");
}
// 3.符合,生成验证码
String code = RandomUtil.randomNumbers(6);
// 4.保存验证码到 session
session.setAttribute("code",code);
// 5.发送验证码
log.debug("发送短信验证码成功,验证码:{}", code);
// 返回ok
return Result.ok();
}
登录:
@Override
public Result login(LoginFormDTO loginForm, HttpSession session) {
// 1.校验手机号
String phone = loginForm.getPhone();
if (RegexUtils.isPhoneInvalid(phone)) {
// 2.如果不符合,返回错误信息
return Result.fail("手机号格式错误!");
}
// 3.校验验证码
Object cacheCode = session.getAttribute("code");
String code = loginForm.getCode();
if(cacheCode == null || !cacheCode.toString().equals(code)){
//3.不一致,报错
return Result.fail("验证码错误");
}
//一致,根据手机号查询用户
User user = query().eq("phone", phone).one();
//5.判断用户是否存在
if(user == null){
//不存在,则创建
user = createUserWithPhone(phone);
}
//7.保存用户信息到session中
session.setAttribute("user",user);
return Result.ok();
}
此处我们还需要实现一个拦截功能,来对一些敏感信息进行拦截。
由于篇幅问题,代码就不再一一展示,大家可以自行去项目源码地址自取:
https://gitee.com/huyi612/hm-dianping
2.集群的session的共享问题。
每个tomcat中都有一份属于自己的session,假设用户第一次访问第一台tomcat,并且把自己的信息存放到第一台服务器的session中,但是第二次这个用户访问到了第二台tomcat,那么在第二台服务器上,肯定没有第一台服务器存放的session,所以此时 整个登录拦截功能就会出现问题,我们能如何解决这个问题呢?早期的方案是session拷贝,就是说虽然每个tomcat上都有不同的session,但是每当任意一台服务器的session修改时,都会同步给其他的Tomcat服务器的session,这样的话,就可以实现session的共享了。
但是这样存在一些问题,每台服务器中都存在完整的一份session数据,随着积累服务器压力也会加大;以及session拷贝数据时,可能会出现延迟。
因此,我们此时可以使用Redis来代替session,Redis数据本身是共享的,因此就可以避免session共享的问题了。
3.基于redis实现共享session登录
因为Redis是一个key-value的数据库,因此我们很容易就能想到以用户的账号为key,value来存储用户的其他信息。
由于存储的数据比较简单,因此我们可以考虑使用String或者Hash结构,如果对内存并不是特别在意且数据量不是很大,此案例中我们使用String即可满足需求。
接下来我们要对key进行处理,因为redis是共享的,因此我们要保证每个key是独一无二的,以避免key的相互覆盖。
此处,大家肯定想到,手机号不就是独一无二的,用手机号作为key不就可以了吗,是的,但不完全是,手机号属于敏感数据,直接存储到Redis中并不合适,因此我们可以在后台生成一个随机串token来代替手机号。
当注册完成后,用户去登录会去校验用户提交的手机号和验证码,是否一致,如果一致,则根据手机号查询用户信息,不存在则新建,最后将用户数据保存到redis,并且生成token作为redis的key,当我们校验用户是否登录时,会去携带着token进行访问,从redis中取出token对应的value,判断是否存在这个数据,如果没有则拦截,如果存在则将其保存到threadLocal中,并且放行。
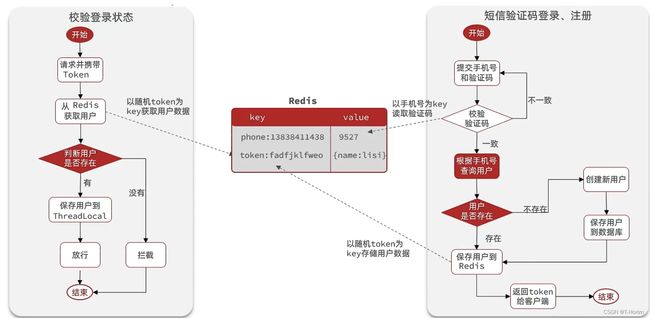
在这个方案中,我们确实可以完成基于redis实现登录的功能。
但是之前的拦截器无法对不需要拦截的路径生效,那么我们可以添加一个拦截器,在第一个拦截器中拦截所有的路径,把第二个拦截器做的事情放入到第一个拦截器中,同时刷新令牌,因为第一个拦截器有了threadLocal的数据,所以此时第二个拦截器只需要判断拦截器中的user对象是否存在即可,完成整体刷新功能。
同样,项目代码不再展示,详情可以去项目代码地址:https://gitee.com/huyi612/hm-dianping
二.商户查询缓存
首先我们要知道什么是缓存。缓存(Cache),就是数据交换的缓冲区,俗称的缓存就是缓冲区内的数据,一般从数据库中获取,存储于本地代码。
缓存的优点:缓存数据存储于代码,而代码运行在内存中,因此它的读写性能极高,可以大大降低用户访问并发量带来的服务器读写压力。
但是缓存也会增加代码复杂度和运营的成本。
在实际开发中,我们会构筑多级缓存来使系统的运行速度进一步提升,例如本地缓存与redis中的缓存并发使用。

接下来我们进行缓存的实战,商户查询缓存。
在我们查询商户信息时,我们是直接操作从数据库中去进行查询的,大致逻辑是这样,直接查询数据库那肯定慢,所以我们需要增加缓存。
标准的操作方式就是查询数据库之前先查询缓存,如果缓存数据存在,则直接从缓存中返回,如果缓存数据不存在,再查询数据库,然后将数据存入redis。

缓存更新策略
缓存更新是redis为了节约内存而设计出来的一个东西,主要是因为内存数据宝贵,当我们向redis插入太多数据,此时就可能会导致缓存中的数据过多,所以redis会对部分数据进行更新,或者把他叫为淘汰更合适。
缓存更新有以下三种策略:
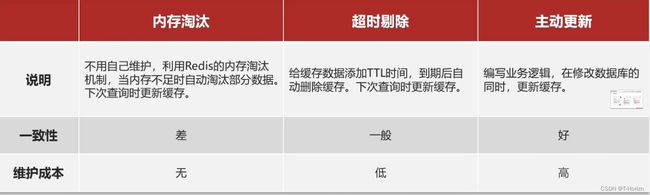

由于我们缓存的数据来源于数据库,而数据库的数据是会发生变化的,因此当数据库的数据发生变化,而缓存中没有同步,此时就会有一致性问题存在,其后果就是用户使用缓存中的过时数据,就会产生类似多线程数据安全问题,从而影响业务。
在此,我们有三种处理方案:

经过综合考虑,本项目中使用方案01.
使用方案一,那么我们又有三个问题。
- 删除缓存还是更新缓存?
更新缓存:每次更新数据库都更新缓存,无效写操作较多
删除缓存:更新数据库时让缓存失效,查询时再更新缓存
- 如何保证缓存与数据库的操作的同时成功或失败?
在单体系统下,我们可以将缓存与数据库操作放在一个事务
在分布式系统下,利用TCC等分布式事务方案。
- 先操作缓存还是先操作数据库?
在我们确定之前可以先看一个图:
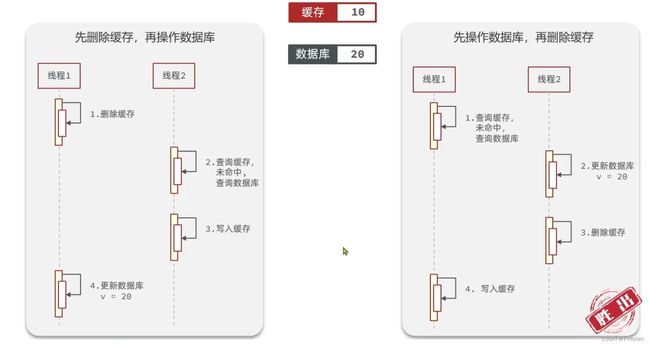
显而易见,我们应当先操作数据库,再删除缓存。
当我们实现商铺和缓存与数据库数据一致时,总体思路为:根据id查询店铺,如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间;根据id修改店铺,先修改数据库,再更新缓存 。
接下来我们来讲讲缓存使用时可能出现的三大问题。
缓存穿透:缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。这样会导致数据库压力激增,甚至导致数据库奔溃。
这是比较正式的说法,如果大家刚接触,可能会觉得比较晦涩,举个例子,我们都有在一些网站中查询数据的经历,如果有一些别有用心的人,它故意查询那些数据库中不存在的数据,那么这些数据会直接打在数据库中,使得数据库压力巨大。
常见的解决方案有两种:
- 缓存空对象
- 优点:实现简单,维护方便
- 缺点:
- 额外的内存消耗
- 可能造成短期的不一致
- 布隆过滤
- 优点:内存占用较少,没有多余key
- 缺点:
- 实现复杂
- 存在误判可能
缓存空对象:当客户端访问不存在的数据,即使这个数据在数据库中也不存在,我们也把它存入redis,这样下次这个数据来访问不存在的数据就会在redis中找到数据,不用访问数据库,从而减轻数据库压力。需要注意的是,我们可以个给这些不存在的数据设置一个TTL,来减少reids的内存占用。
布隆过滤:布隆过滤器其实采用的是哈希思想来解决这个问题,通过一个庞大的二进制数组,走哈希思想去判断当前这个要查询的这个数据是否存在,如果布隆过滤器判断存在,则放行,这个请求会去访问redis,哪怕此时redis中的数据过期了,但是数据库中一定存在这个数据,在数据库中查询出来这个数据后,再将其放入到redis中,
假设布隆过滤器判断这个数据不存在,则直接返回
这种方式优点在于节约内存空间,存在误判,误判原因在于:布隆过滤器走的是哈希思想,只要哈希思想,就可能存在哈希冲突。
解决缓存穿透,总的来说还是有不少方法:
缓存null值;布隆过滤;增强id的复杂度,避免被猜测id规律;做好数据的基础格式校验;加强用户权限校验;做好热点参数的限流。
根据不同场景使用合适的方法才是最佳选择。
缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
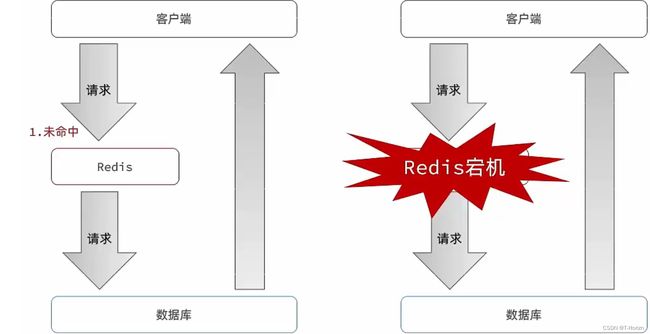
它的解决方案大致有以下几种:
给不同的Key的TTL添加随机值;利用Redis集群提高服务的可用性;给缓存业务添加降级限流策略;给业务添加多级缓存。
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
常见的解决方案有两种:
互斥锁:

逻辑过期:
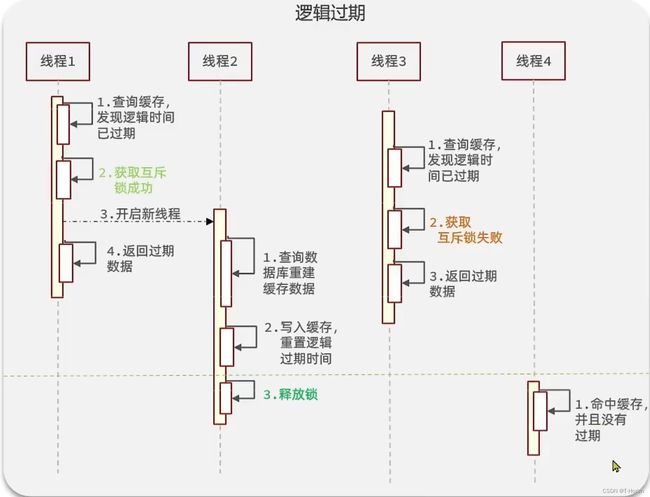
那么这两种方案谁更好用,我们来看一组比较。

以上看来,这两种方案都有各自的优点与缺点,那就要看场景再来决定使用哪个。
互斥锁:在该项目中,先查询商户的id,如果从缓存没有查询到数据,则进行互斥锁的获取,获取互斥锁后,判断是否获得到了锁,如果没有获得到,则休眠,过一会再进行尝试,直到获取到锁为止,才能进行查询
如果获取到了锁的线程,再去进行查询,查询后将数据写入redis,再释放锁,返回数据,利用互斥锁就能保证只有一个线程去执行操作数据库的逻辑,防止缓存击穿。
逻辑过期:当用户开始查询redis时,判断是否命中,如果没有命中则直接返回空数据,不查询数据库,而一旦命中后,将value取出,判断value中的过期时间是否满足,如果没有过期,则直接返回redis中的数据,如果过期,则在开启独立线程后直接返回之前的数据,独立线程去重构数据,重构完成后释放互斥锁。
优惠券秒杀问题
- 全局唯一ID
当用户抢购时,会生成订单并保存到相应的表中,而订单表如果使用数据库自增ID就存在一些问题:
id的规律太明显:如果我们的id具有太明显的规则,用户或者说商业对手很容易猜测出来我们的一些敏感信息,比如商城在一天时间内,卖出了多少单,这明显不合适。
受表单数据量的限制:随着我们商城规模越来越大,mysql的单表的容量不宜超过500W,数据量过大之后,我们要进行拆库拆表,但拆分表了之后,他们从逻辑上讲他们是同一张表,所以他们的id是不能一样的,于是乎我们需要保证id的唯一性。
为了增加ID的安全性,我们可以不直接使用Redis自增的数值,而是拼接一些其它信息:

- 添加优惠券
添加普通优惠券的话,比较容易,此处不再赘述。
添加秒杀优惠券,就得限制数量,秒杀卷除了具有优惠卷的基本信息以外,还具有库存,抢购时间,结束时间等等字段。将秒杀信息保存之后,我们最后也需要保存到redis中。
超卖问题
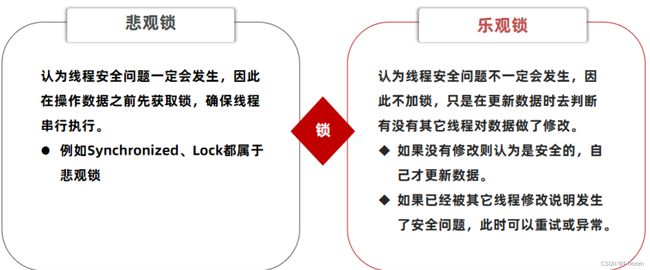
假设线程1过来查询库存,判断出来库存大于1,正准备去扣减库存,但是还没有来得及去扣减,此时线程2过来,线程2也去查询库存,发现这个数量一定也大于1,那么这两个线程都会去扣减库存,最终多个线程相当于一起去扣减库存,此时就会出现库存的超卖问题。

这里,我们就需要使用乐观锁和悲观锁来解决。
一人一单
优惠卷是为了引流,但是目前的情况是,一个人可以无限制的抢这个优惠卷,所以我们应当增加一层逻辑,让一个用户只能下一个单,而不是让一个用户下多个单。
它的实现逻辑:启用spring的事务管理,查询订单是否存在过,如果存在,扣减失败,如果不存在,扣减库存,然后创建订单,最后返回订单id。
在单机情况下,这样确实可以实现一人一旦,但是在集群环境下,不同tomcat中的锁对象并不是同一个,因此这种情况下会导致syn锁失效,此时我们就需要使用分布式锁来解决。
分布式锁
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁。
分布式锁的核心思想就是让大家都使用同一把锁,只要大家使用的是同一把锁,那么我们就能锁住线程,不让线程进行,让程序串行执行,这就是分布式锁的核心思路。

那么分布式锁他应该满足一些什么样的条件呢?
可见性:多个线程都能看到相同的结果,注意:这个地方说的可见性并不是并发编程中指的内存可见性,只是说多个进程之间都能感知到变化的意思
互斥:互斥是分布式锁的最基本的条件,使得程序串行执行
高可用:程序不易崩溃,时时刻刻都保证较高的可用性
高性能:由于加锁本身就让性能降低,所有对于分布式锁本身需要他就较高的加锁性能和释放锁性能
安全性:安全也是程序中必不可少的一环
常见的分布式锁有三种:

在使用Redisson实现分布式锁的时候,会遇到一个问题,就是拿锁,比锁,删除锁这一系列动作并不是原子性的,因此,我们就需要使用lua脚本来操作redis,保证其原子性。
此处对于Redisson分布式锁的介绍较少,以后再做补充。
Redis消息队列实现异步秒杀
首先我们要知道何为消息对列:

使用队列的好处在于 解耦:所谓解耦,举一个生活中的例子就是:快递员(生产者)把快递放到快递柜里边(Message Queue)去,我们(消费者)从快递柜里边去拿东西,这就是一个异步,如果耦合,那么这个快递员相当于直接把快递交给你,这事固然好,但是万一你不在家,那么快递员就会一直等你,这就浪费了快递员的时间,所以这种思想在我们日常开发中,是非常有必要的。
这种场景在我们秒杀中就变成了:我们下单之后,利用redis去进行校验下单条件,再通过队列把消息发送出去,然后再启动一个线程去消费这个消息,完成解耦,同时也加快我们的响应速度。
这里我们可以使用一些现成的mq,比如kafka,rabbitmq等等,但是呢,如果没有安装mq,我们也可以直接使用redis提供的mq方案,降低我们的部署和学习成本。
Redis提供了三种消息队列:基于list实现消息队列,基于PubSub的消息队列,基于Stream的消息队列。
 因此一般来说,我们使用基于Stream的消息对列。具体如何实现,可以去项目源码地址访问:https://gitee.com/huyi612/hm-dianping
因此一般来说,我们使用基于Stream的消息对列。具体如何实现,可以去项目源码地址访问:https://gitee.com/huyi612/hm-dianping
4.发布笔记
发布笔记就像我们发朋友圈,可以上传文字,图片等。
首先需要写一个上传文件的接口,需要注意的是我们需要修改其中自己图片所在的位置,在实践中图片一般放在ngnix或云存储中。
然后再写具体的业务。
5.附近商户
这里需要提及GEO,它就是地理坐标,我们在平常用到定位,例如美团外卖的附近商家。
而Redis在3.2版本中也加入了GEO,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。
我们在实现该功能的时候,需要注意:SpringDataRedis的2.3.9版本并不支持Redis 6.2提供的GEOSEARCH命令,因此我们需要提示其版本。
然后我们先判断是否需要坐标查询,如果不需要则按数据库查询,其中比较重要的是查询redis,并按照距离排序,分页。然后解析出id,;然后判断是否有下一页,没有,则结束;有,则截取end-from部分,然后获取店铺,距离,再根据id查询店铺,最后返回查询到的商户。
@Override
public Result queryShopByType(Integer typeId, Integer current, Double x, Double y) {
// 1.判断是否需要根据坐标查询
if (x == null || y == null) {
// 不需要坐标查询,按数据库查询
Page
.eq("type_id", typeId)
.page(new Page<>(current, SystemConstants.DEFAULT_PAGE_SIZE));
// 返回数据
return Result.ok(page.getRecords());
}
// 2.计算分页参数
int from = (current - 1) * SystemConstants.DEFAULT_PAGE_SIZE;
int end = current * SystemConstants.DEFAULT_PAGE_SIZE;
// 3.查询redis、按照距离排序、分页。结果:shopId、distance
String key = SHOP_GEO_KEY + typeId;
GeoResults
.search(
key,
GeoReference.fromCoordinate(x, y),
new Distance(5000),
RedisGeoCommands.GeoSearchCommandArgs.newGeoSearchArgs().includeDistance().limit(end)
);
// 4.解析出id
if (results == null) {
return Result.ok(Collections.emptyList());
}
List
if (list.size() <= from) {
// 没有下一页了,结束
return Result.ok(Collections.emptyList());
}
// 4.1.截取 from ~ end的部分
List
Map
list.stream().skip(from).forEach(result -> {
// 4.2.获取店铺id
String shopIdStr = result.getContent().getName();
ids.add(Long.valueOf(shopIdStr));
// 4.3.获取距离
Distance distance = result.getDistance();
distanceMap.put(shopIdStr, distance);
});
// 5.根据id查询Shop
String idStr = StrUtil.join(",", ids);
List
for (Shop shop : shops) {
shop.setDistance(distanceMap.get(shop.getId().toString()).getValue());
}
// 6.返回
return Result.ok(shops);
}
本篇涵盖了redis的基本使用以及一般使用,其实还是有一些东西没有写上,后续再有用到会陆续补上。