(一)基于知识图谱的医疗问答系统(实例+代码理解)保姆级教程
本篇文章内容来源于刘焕勇老师在Github上的开源项目。https://github.com/liuhuanyong/QASystemOnMedicalKG
如果打不开或者是想要数据集、源码等文件,或者是帮忙调试程序请评论留言~
项目介绍详细方案,架构等问题不再赘诉,相关链接里已经介绍很详细。这里主要着重于运行程序和代码理解(因为代码很详细,包括运行过程、结果,整篇文章可能较长)。
我用的软件相关版本:
pycharm 2021.3
neo4j 4.2.19 (community)
python 3.7
py2neo 2021.2.3
先放部分效果图:左边是图谱的一部分,右边是实体的一些属性,包括疾病原因、科室、治疗时间、治疗药物等。

首先创建一个 MedicalGraph 类,定义一个连接数据库的方法。这里需要注意的是连接 Graph 语法的问题,旧版本是需要 username="xxx", password="xxx"。
def __init__(self):
cur_dir = '/'.join(os.path.abspath(__file__).split('/')[:-1])
self.data_path = os.path.join(cur_dir, 'data/medical2.json')
self.g = Graph("http://localhost:7474", auth=("neo4j", "***"))
self.g.delete_all()数据集的话是之前刘老师已经在网上爬虫好的json文件,长这个样子。

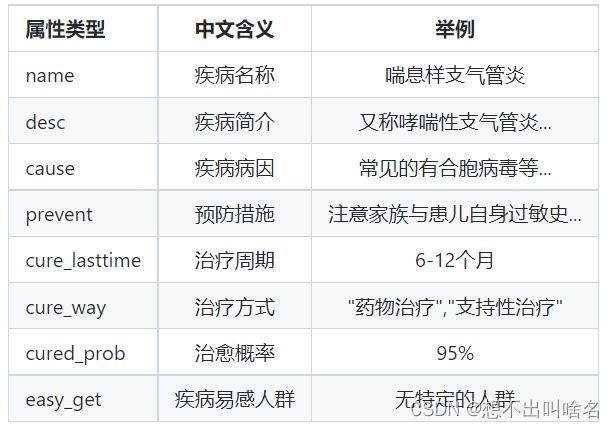
为了看官们舒适体验感和有助于下面代码理解,我还是把实体类型拿过来贴一下,单纯看json文件有些乱。。

实体关系类型:
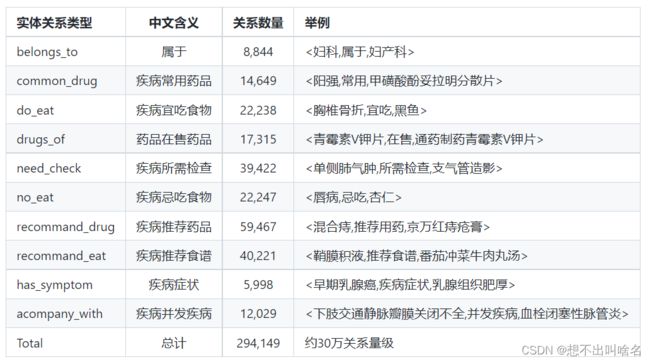
知识图谱属性类型:
好了,我们回到代码,这里有一个主程序,将MedicalGraph()类实例化,然后创建结点和关系,我们点进去看看程序的执行过程。
首先,创建知识图谱实体结点类型,这里定义了如下结点和关系,对应之前的表格很好理解。
Drugs, Foods, Checks, Departments, Producers, Symptoms, Diseases, disease_infos,rels_check, rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug, rels_drug_producer, rels_recommanddrug,rels_symptom, rels_acompany, rels_category
然后我们进去create_diseases_nodes创建一些疾病的信息。
def create_graphnodes(self):
Drugs, Foods, Checks, Departments, Producers, Symptoms, Diseases, disease_infos,rels_check, rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug, rels_drug_producer, rels_recommanddrug,rels_symptom, rels_acompany, rels_category = self.read_nodes()
self.create_diseases_nodes(disease_infos)
self.create_node('Drug', Drugs)
print(len(Drugs))
self.create_node('Food', Foods)
print(len(Foods))
self.create_node('Check', Checks)
print(len(Checks))
self.create_node('Department', Departments)
print(len(Departments))
self.create_node('Producer', Producers)
print(len(Producers))
self.create_node('Symptom', Symptoms)
return我们注意到第一行代码最右边等于 self.read_nodes() ,这其实就是在读取数据。这个时候跳转到我们定义的 read_nodes方法。
注意我们还是在create_graphnodes方法中,只不过跳转到了其他方法之中,这段代码有点长,思路不要乱!
def read_nodes(self):
# 共7类节点
drugs = [] # 药品
foods = [] # 食物
checks = [] # 检查
departments = [] #科室
producers = [] #药品大类
diseases = [] #疾病
symptoms = []#症状
disease_infos = []#疾病信息
# 构建节点实体关系
rels_department = [] # 科室-科室关系
rels_noteat = [] # 疾病-忌吃食物关系
rels_doeat = [] # 疾病-宜吃食物关系
rels_recommandeat = [] # 疾病-推荐吃食物关系
rels_commonddrug = [] # 疾病-通用药品关系
rels_recommanddrug = [] # 疾病-热门药品关系
rels_check = [] # 疾病-检查关系
rels_drug_producer = [] # 厂商-药物关系
rels_symptom = [] #疾病症状关系
rels_acompany = [] # 疾病并发关系
rels_category = [] # 疾病与科室之间的关系
count = 0
for data in open(self.data_path):
disease_dict = {}
count += 1
print(count)
data_json = json.loads(data)
disease = data_json['name']
disease_dict['name'] = disease
diseases.append(disease)
disease_dict['desc'] = ''
disease_dict['prevent'] = ''
disease_dict['cause'] = ''
disease_dict['easy_get'] = ''
disease_dict['cure_department'] = ''
disease_dict['cure_way'] = ''
disease_dict['cure_lasttime'] = ''
disease_dict['symptom'] = ''
disease_dict['cured_prob'] = ''
if 'symptom' in data_json:
symptoms += data_json['symptom']
for symptom in data_json['symptom']:
rels_symptom.append([disease, symptom])
if 'acompany' in data_json:
for acompany in data_json['acompany']:
rels_acompany.append([disease, acompany])
if 'desc' in data_json:
disease_dict['desc'] = data_json['desc']
if 'prevent' in data_json:
disease_dict['prevent'] = data_json['prevent']
if 'cause' in data_json:
disease_dict['cause'] = data_json['cause']
if 'get_prob' in data_json:
disease_dict['get_prob'] = data_json['get_prob']
if 'easy_get' in data_json:
disease_dict['easy_get'] = data_json['easy_get']
if 'cure_department' in data_json:
cure_department = data_json['cure_department']
if len(cure_department) == 1:
rels_category.append([disease, cure_department[0]])
if len(cure_department) == 2:
big = cure_department[0]
small = cure_department[1]
rels_department.append([small, big])
rels_category.append([disease, small])
disease_dict['cure_department'] = cure_department
departments += cure_department
if 'cure_way' in data_json:
disease_dict['cure_way'] = data_json['cure_way']
if 'cure_lasttime' in data_json:
disease_dict['cure_lasttime'] = data_json['cure_lasttime']
if 'cured_prob' in data_json:
disease_dict['cured_prob'] = data_json['cured_prob']
if 'common_drug' in data_json:
common_drug = data_json['common_drug']
for drug in common_drug:
rels_commonddrug.append([disease, drug])
drugs += common_drug
if 'recommand_drug' in data_json:
recommand_drug = data_json['recommand_drug']
drugs += recommand_drug
for drug in recommand_drug:
rels_recommanddrug.append([disease, drug])
if 'not_eat' in data_json:
not_eat = data_json['not_eat']
for _not in not_eat:
rels_noteat.append([disease, _not])
foods += not_eat
do_eat = data_json['do_eat']
for _do in do_eat:
rels_doeat.append([disease, _do])
foods += do_eat
recommand_eat = data_json['recommand_eat']
for _recommand in recommand_eat:
rels_recommandeat.append([disease, _recommand])
foods += recommand_eat
if 'check' in data_json:
check = data_json['check']
for _check in check:
rels_check.append([disease, _check])
checks += check
if 'drug_detail' in data_json:
drug_detail = data_json['drug_detail']
producer = [i.split('(')[0] for i in drug_detail]
rels_drug_producer += [[i.split('(')[0], i.split('(')[-1].replace(')', '')] for i in drug_detail]
producers += producer
disease_infos.append(disease_dict)
return set(drugs), set(foods), set(checks), set(departments), set(producers), set(symptoms), set(diseases), disease_infos,\
rels_check, rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug, rels_drug_producer, rels_recommanddrug,\
rels_symptom, rels_acompany, rels_category进行读取文件操作(debug一下,看看代码每一步都在做些什么)
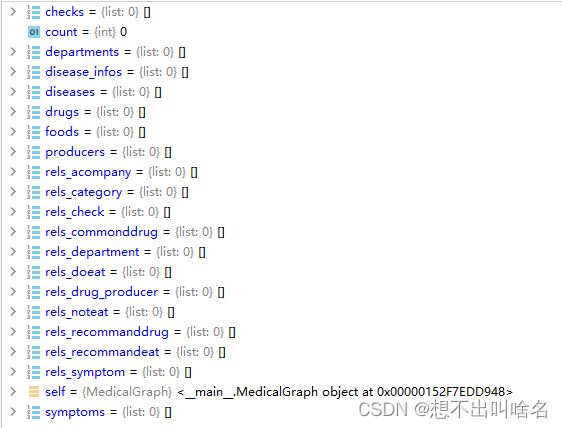
我们能够看到我们创建这些 list 成功,现在里面并没有值,下一步应该执行取数据操作,在我们的data里取第一行数据,第一行数据病症的name是肺泡蛋白质沉积症。
![]()
结合代码,我们看到已经读取数据的时候已经把每一个对应的信息放到了list里。如果 sympton 在 data_json中(data_json就是当前行数据),然后开始循环这个列表取数据。比如说,当前是“肺泡蛋白质沉积症”,它的症状有五个分别是['紫绀','胸痛','呼吸困难','乏力','毓卓'],我们进入for循环取数据,添加到关系之中。程序继续向下运行,同样的道理,判断并发症是否在data_json中,以及病症描述、预防、原因等等。

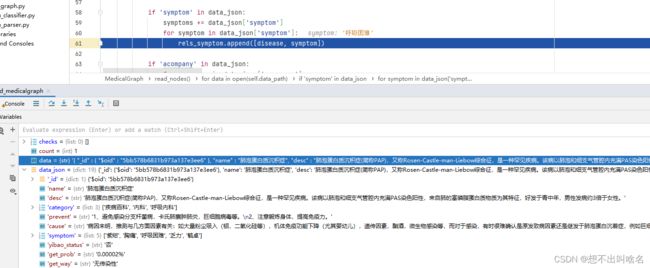
如果 sympton 在 data_json中(data_json就是当前行数据),然后开始循环这个列表取数据。比如说,当前是“肺泡蛋白质沉积症”,它的症状有五个分别是['紫绀','胸痛','呼吸困难','乏力','毓卓'],(这里数据不太好,可能因为数据是爬取的,症状中还出现了人名)我们进入for循环取数据,添加到关系之中。程序继续向下运行,同样的道理,判断并发症是否在data_json中,以及病症描述、预防、原因等等。
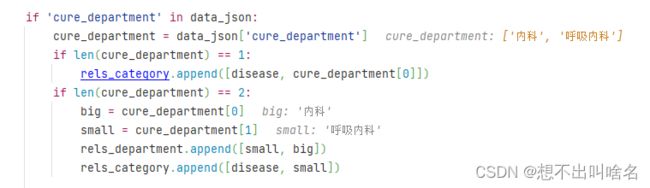
需要注意的是,我们的科室之间也存在关系,比如 ['内科','呼吸内科'],这时候我们取数据要判断列表的长度,如果长度为1说明只有一个数据,如果长度为2,就要分大小科室。还有drug_details的形式和其他的有所不同,包括了药品名和生产厂商,所以需要注意一下提取方式。然后继续for循环,取第2条数据,直到所有数据都取完。
所有的数据读取完之后,第一条命令执行完毕,我们再回到最初的create_graphnodes方法,执行第二条语句。
执行 create_diseases_nodes方法。该方法是创建知识图谱中心疾病的结点,给结点创建一些它的信息,如右边的信息:
def create_diseases_nodes(self, disease_infos):
count = 0
for disease_dict in disease_infos:
node = Node("Disease", name=disease_dict['name'], desc=disease_dict['desc'],
prevent=disease_dict['prevent'] ,cause=disease_dict['cause'],
easy_get=disease_dict['easy_get'],cure_lasttime=disease_dict['cure_lasttime'],
cure_department=disease_dict['cure_department']
,cure_way=disease_dict['cure_way'] , cured_prob=disease_dict['cured_prob'])
self.g.create(node)
count += 1
print(count)
return这里的disease_infos 是我们之前就定义好的list, 在读取数据操作的时候已经执行了disease_infos.append(disease_dict) 将数据存放进去。所以我们遍历创建结点就可以了。
然后依次创建其他结点,也就是药品的结点、食物的结点、检查、科室等等其他相关信息的结点。
def create_node(self, label, nodes):
count = 0
for node_name in nodes:
node = Node(label, name=node_name)
self.g.create(node)
count += 1
print(count, len(nodes))
return所有结点建立完成之后,到这里我们的创建知识图谱实体结点方法结束,也就是handler.create_graphnodes()执行结束,开始执行 handler.create_graphrels()。
def create_graphrels(self):
Drugs, Foods, Checks, Departments, Producers, Symptoms, Diseases, disease_infos, rels_check, rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug, rels_drug_producer, rels_recommanddrug,rels_symptom, rels_acompany, rels_category = self.read_nodes()
self.create_relationship('Disease', 'Food', rels_recommandeat, 'recommand_eat', '推荐食谱')
self.create_relationship('Disease', 'Food', rels_noteat, 'no_eat', '忌吃')
self.create_relationship('Disease', 'Food', rels_doeat, 'do_eat', '宜吃')
self.create_relationship('Department', 'Department', rels_department, 'belongs_to', '属于')
self.create_relationship('Disease', 'Drug', rels_commonddrug, 'common_drug', '常用药品')
self.create_relationship('Producer', 'Drug', rels_drug_producer, 'drugs_of', '生产药品')
self.create_relationship('Disease', 'Drug', rels_recommanddrug, 'recommand_drug', '好评药品')
self.create_relationship('Disease', 'Check', rels_check, 'need_check', '诊断检查')
self.create_relationship('Disease', 'Symptom', rels_symptom, 'has_symptom', '症状')
self.create_relationship('Disease', 'Disease', rels_acompany, 'acompany_with', '并发症')
self.create_relationship('Disease', 'Department', rels_category, 'belongs_to', '所属科室')同样的,我们还需要读一遍数据取其中结点之间的关系,从第二条命令开始执行create_relationship方法,创建实体关系边。
create_relationship代码如下:
def create_relationship(self, start_node, end_node, edges, rel_type, rel_name):
count = 0
# 去重处理
set_edges = []
for edge in edges:
set_edges.append('###'.join(edge))
all = len(set(set_edges))
for edge in set(set_edges):
edge = edge.split('###')
p = edge[0]
q = edge[1]
query = "match(p:%s),(q:%s) where p.name='%s'and q.name='%s' create (p)-[rel:%s{name:'%s'}]->(q)" % (
start_node, end_node, p, q, rel_type, rel_name)
try:
self.g.run(query)
count += 1
print(rel_type, count, all)
except Exception as e:
print(e)
return依次建立每一个实体的关系边,到这我们的图谱就建立起来了!

以上内容是我自己的见解,难免存在错误和不足,欢迎探讨!!再次感谢刘老师的开源项目。