原文:http://blogs.vmware.com/vfabric/2013/04/how-instagram-feeds-work-celery-and-rabbitmq.html

Instagram is one of the poster children for social media site successes. Founded in 2010, the photo sharing site now supports upwards of 90 million active photo-sharing users. As with every social media site, part of the fun is that photos and comments appear instantly so your friends can engage while the moment is hot. Recently, at PyCon 2013 last month, Instagram engineer Rick Branson shared how Instagram needed to transform how these photos and comments showed up in feeds as they scaled from a few thousand tasks a day to hundreds of millions.
Rick started off his talk demonstrating how traditional database approaches break, calling them the “naïve approach”. In this approach, when working to display a user feed, the application would directly fetch all the photos that the user followed from a single, monolithic data store, sort them by creation time and then only display the latest 10:
SELECT * FROM photos
WHERE author_id IN
(SELECT target_id FROM following
WHERE source_id = %(user_id)d)
ORDER BY creation_time DESC
LIMIT 10;
Instead, Instagram chose to follow a modern distributed data strategy that will allow them to scale nearly linearly.
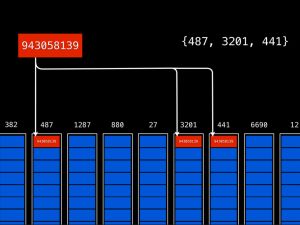 To start, they built a system in Redis that essentially stores a users feed that they would fetch at any given time. Each user is assigned a media ID. In the diagram to the right, this particular users media ID is 943058139. From there, they rely on asynchronous tasks to populate individual feeds as photos are posted. Each time a photo is posted, the system finds out all the users followers (in this case, 3 followers are identified with IDs 487, 3201, and 441), and assigns individual tasks to place the photo into each followers feed. This data strategy is called a Fanout-On-Write approach, and its very well suited for fast reads. Since reads in their system outweigh writes by 100:1, and most of these reads are sourcing from mobile devices, it was imperative to weigh this heavily towards minimizing read costs.
To start, they built a system in Redis that essentially stores a users feed that they would fetch at any given time. Each user is assigned a media ID. In the diagram to the right, this particular users media ID is 943058139. From there, they rely on asynchronous tasks to populate individual feeds as photos are posted. Each time a photo is posted, the system finds out all the users followers (in this case, 3 followers are identified with IDs 487, 3201, and 441), and assigns individual tasks to place the photo into each followers feed. This data strategy is called a Fanout-On-Write approach, and its very well suited for fast reads. Since reads in their system outweigh writes by 100:1, and most of these reads are sourcing from mobile devices, it was imperative to weigh this heavily towards minimizing read costs.
Write costs are essentially equal to the number of followers each user has and is done for each post. To do this reliably for every user on mobile phones over web requests including Justin Bieber, who has over 7 million followers, this process needed to be handled asynchronously and in the background.
The posts are delivered using a task manager and message broker. For the task manager, they chose Celery, an open source distributed task framework that is written in Python and is known to be highly extensible, feature rich and has great tooling.
With the task manager selected, the Instagram team now needed a message broker to buffer the tasks and distribute to the workers. Initially they looked to Redis, as they already had it in house. However, the fact that it relied on polling meant that it would not scale as they needed, and replication would need to be manually built out, adding additional work to implement it. Also, Redis is an in-memory solution, which in events where the queues built up if the machines ran out of memory, there was risk to lose the tasks.
Next they considered Beanstalk, a purpose built task queue which seemed ideal. It was fast, it pushed to consumers, and it spilled to disk in the event of running out of memory. However, it did not support replication in any way, which was a deal breaker.
Finally, the team landed on RabbitMQ. It was reasonably fast, efficient, supported low-maintenance synchronous replication, and is highly compatible with Celery. Additionally, it was multi-purpose which allowed them to use their message broker for other tasks like cross-posting to other networks asynchronously such as Facebook and Twitter. (TIME- AND BATTERY-SAVER TIP: In my personal experience, at big community, sporting or music events when access bandwidth and therefore Facebook can be difficult, it is much faster to post to Instagram and allow it to post to Facebook in the background.)
 The setup is fairly straight-forward. A web request pushes the post to the RabbitMQ broker. Messages are distributed out to workers in a round robin style fashion. If a worker fails, the task is redistributed to the next worker. They use RabbitMQ 3.0 clustered over two mirrored broker nodes in Amazon’s EC2. Typically highly over-provisioned to account for spikes in traffic, they can easily scale out by adding broker clusters.
The setup is fairly straight-forward. A web request pushes the post to the RabbitMQ broker. Messages are distributed out to workers in a round robin style fashion. If a worker fails, the task is redistributed to the next worker. They use RabbitMQ 3.0 clustered over two mirrored broker nodes in Amazon’s EC2. Typically highly over-provisioned to account for spikes in traffic, they can easily scale out by adding broker clusters.
The result is that the Instagram application has about 25,000 application threads pushing about 4000 tasks per second and completes tasks between 5 and 10 milliseconds. The system has no problem with rolling restarts, it spans data centers well and they’ve been able to bring new engineers on the team up to speed really quickly. Most importantly, however, having hit their high of over 10,000 connections of users simultaneously posting pictures, they are confident it could scale even further.
To see Branson’s full presentation, including more detail on how their configurations and details on different types of tasks, check out the video below:http://i.tianqi.com/index.php?c=code&id=1&bdc=%23&icon=2&wind=1&num=1(国内无法访问,可能链接失效或被墙了)