Edge-SLAM论文翻译
边缘同步定位:边缘辅助视觉同步定位和建图
Edge-SLAM - Edge-Assisted Visual Simultaneous Localization And Mapping
原本翻译:机翻+人工校对,可能有不准之处。
摘要:
城市环境中的定位正变得越来越重要,并被用于ARCore[11]、ARKit[27]等工具。实现精确的室内定位和空间地图的一种流行机制是使用视觉同步定位和建图(Visual- slam)。然而,视觉slam在内存和处理时间上是资源密集型的。此外,随着时间的推移,一些操作的复杂性会增加,这使得持续在移动设备上运行具有挑战性。边缘计算为移动设备提供额外的计算和内存资源,以允许卸载一些任务,而不会出现卸载到云上时出现的大延迟。在本文中,我们提出了边缘slam,一个利用边缘计算资源来卸载部分视觉slam的系统。我们使用ORB-SLAM2作为一个原型视觉slam系统,并将其修改为edge和移动设备之间的分割架构。我们将跟踪计算保留在移动设备上,将剩余的计算,即局部映射和环路闭合,移动到边缘。我们在此工作中描述设计选择,并在我们的原型中实现它们。我们的结果显示,我们的分割架构可以允许视觉slam系统在有限资源下长期运作,而不影响操作的准确性。它还保持了移动设备上的计算和内存成本不变,这将允许部署其他使用视觉SLAM的终端应用程序。
CCS的概念
计算机系统组织à云计算;客户服务端架构;以人为中心的计算泛在和移动计算;·计算方法机器人视觉
关键词:视觉同步定位和制图,边缘计算,分割架构,移动系统,定位,建图
1.介绍
传感、计算、通信和驱动方面的进步将一套新的移动设备带入我们的日常生活。服务机器人在我们家里工作,为我们打扫房间,在酒店里送调味品。智能手机上的AR应用程序可以让我们在室内环境中导航,在不实际操作的情况下提供空间重构的可视化,或者在现实世界中通过添加虚拟对象来玩游戏。AR眼镜被全球范围内应用。未来还有很多预想中的应用,包括通过混合现实实现更好的无缝连接,以及使用机器人实现网真。(思科网真(一种通过结合高清晰度视频、音频和交互式组件,在网络上创建一种独特的"面对面"体验的新型技术);远端临场;远程呈现)这些应用大多依赖于感知空间环境,特别是在没有gps的室内空间定位和地点识别场景。
空间感知是几十年来的研究课题。根据应用的不同,空间感知有多种形式。例如包括:
1.地点识别是指将一个位置的传感器快照(例如,相机的图像)与先前测量的已知位置相匹配,2. 从起点跟踪或估计移动设备所遵循的路径,例如里程计;3. 定位是指移动设备相对于已知地标的绝对定位。这些类型的感知对于各种应用程序都是有用的,并且在计算复杂度和效用方面有权衡。最近,同步定位和建图(SLAM)已经发展成为一类有助于精确识别空间环境的算法。它是相对于绝对坐标系定位移动设备以及相对于同一坐标系映射已遍历空间的过程。特别是,最近人们对使用视觉传感(摄像机、深度传感器、激光雷达)进行SLAM产生了浓厚的兴趣,从而产生了几种视觉SLAM算法。
典型的视觉SLAM算法执行三个主要任务。首先,当移动设备移动时,算法执行一帧一帧对齐。这是将捕获第k帧(图像)的移动设备的姿态与捕获帧k+1k时的姿态相关联的过程。通常,这是通过检测每一帧中的特征并找到两帧之间的特征对应关系来实现的。第二步是在本地执行地图调整。该步骤包括调整步骤1中执行的帧-帧对齐,并识别步骤3中使用的“关键帧”或重要帧。最后,步骤3是循环闭合,或算法识别移动设备何时回到它之前访问过的位置的能力。这一步要求算法将新帧与之前的所有帧进行比较以识别匹配。这个任务的一个挑战是,随着地图的增长,这个任务的复杂性会不断增加。缓解这个问题的一个典型解决方案是使用步骤2中确定的关键帧进行比较,而不是将新帧与之前的所有帧进行比较。其他算法通过各种方法限制比较帧子集的次数,比如使用短期和长期记忆,或者使用其他感知[22]聚类。然而,这些解决方案中的大多数都是在精度和计算复杂度之间进行权衡,从而导致混合的结果。
最近,在边缘计算架构方面有很多令人兴奋的东西[37,46,47,49]。这样的架构提倡使用边缘计算资源(通常是相对于移动设备的本地资源和一个本地网络上的跳转),以减轻移动设备上的一些计算任务。在这项工作中,我们利用边缘计算资源来改进视觉slam。为此,我们作出了以下贡献:
我们采用ORB-SLAM2[41],一种流行的视觉SLAM系统,并将其适应于edge计算架构。我们的系统被称为Edge-SLAM。
为此,我们将跟踪和局部映射过程解耦,从而在不影响跟踪模块功能的情况下提高了局部映射和闭环效率。
我们使用我们的数据集和基准数据集例TUM[26],在两种不同移动设备上来评估Edge-SLAM。
我们开源了我们的Edge-SLAM的实现,允许其他从业者与我们的系统进行比较。
我们的结果表明,Edge-SLAM架构是一种很好的将视觉slam计算分配到边缘和移动设备之间的方法。除了性能之外,在边缘计算范例中部署Visual-SLAM还有几个额外的好处,比如控制地图复杂性、隐私性、并发性以及动态推理。我们希望在未来的工作中研究这些想法。
2.相关工作
边缘计算领域一直是过去十年的研究主题[37,46,47,49]。它提出了一种范式,将大量计算和存储资源放置在互联网的边缘,更接近产生大量数据的移动和物联网设备。这个想法是利用离传感器更近的计算和存储资源来提高处理延迟,同时不增加资源稀缺设备的负担。
之前已经有一些工作致力于将任务从移动设备转移到边/云(edge/cloud)上。MAUI[10]和CloneCloud[8]在不同粒度上执行云任务卸载。MARVEL[7]、VisualPrint[30]和[36]提供了特定于应用程序的技术,用于将数据卸载到边缘或云上。这些论文致力于在对时间敏感的应用程序中减少卸载延迟或对最终用户屏蔽它。
实时定位和建图(SLAM)已经成为机器人和移动系统几十年的研究课题[5,13,50)。最初的研究集中在深度传感器,如声纳[17]和二维激光雷达[9,12]。其他传感器如Wi-Fi信号强度也被用于SLAM[18,25,39]。
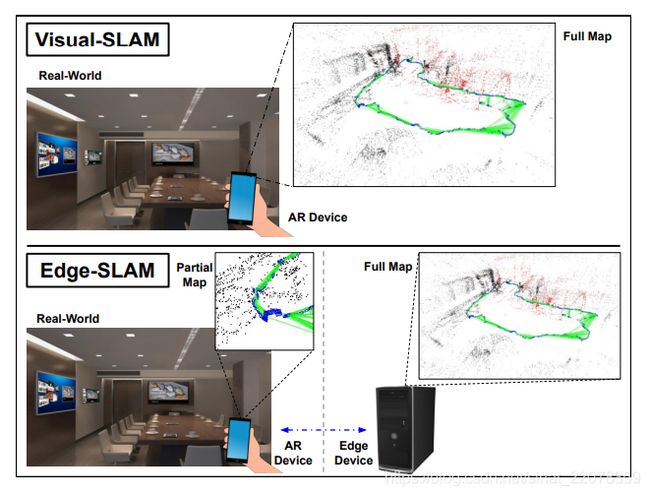
图一:Visual-SLAM与Edge-SLAM。一个运行Visual-SLAM的增强现实设备(上),以及一个与环境中的edge设备协作运行edge - slam的增强现实设备(下)[1-3, 26,41]
视觉slam在过去十年中发展迅速[16,24]。这包括RGB摄像头、RGB- d摄像头和激光雷达传感器的使用。PTAM[31]、DTAM[43]、LSD-SLAM[14]等系统均采用单目摄像机进行SLAM。最近的一个趋势是使用彩色图像与深度图像。一些更有名的视觉SLAM的例子包括RGBD-SLAM[16]、RTAB-Map[34]和ORB-SLAM[40,41]。他们建立在Kinect Fusion[42]和Kintinuous[51]等系统的基础上,这些系统首次使用RGBD传感器对环境进行3d建模。目前的趋势也通过语义推理来改进基本的视觉SLAM [21,以及在地图[20]中的对象持久性。
最近,人们对使用多个传感器来执行SLAM越来越感兴趣。最近的一些作品将Wi-Fi与视觉感知结合在一起改进了SLAM。在[29]中,他们使用高斯过程建模Wi-Fi信号强度,并使用它来寻找机器人位置的初始种子估计,然后用RGB-D数据精炼。[44]为Wi-Fi建模利用了一个训练阶段,然后应用粒子滤波器来融合不同的传感器。[22]提供了一种将Wi-Fi APs的无线信号强度集成到Visual-SLAM算法的通用方法。[4]使用Wi-Fi地图来合并来自多个代理的多个可视地图。
在最近的研究中,人们通过将边缘/云计算与SLAM系统以不同的方式相结合来探索协同SLAM。[48]在ORBSLAM2[41]上为无人机(uav)建立了一个协作式单眼SLAM。该系统在每个无人机上运行一个较小版本的ORB-SLAM2(跟踪线程和本地映射线程),独立地维护和优化有限的本地地图,并在集中服务器上运行地点识别和地图融合,将无人机本地地图合并和优化为全局地图。这项研究的重点是在多架无人机上实现协同SLAM。而edge - slam通过分割移动设备和边缘设备之间的Visual-SLAM管道,解决了移动设备上的视觉SLAM不断增加的资源使用(计算、存储等)。[19]提出了一个微型空中飞行器(MAVs)的映射框架。它由多个微型空中飞行器和服务器之间的单向通信组成。每个MAV提取特征,估计相对运动,然后发送信息到服务器建立一个单独的地图和检测循环,以及合并MAVs的地图。这个框架不维护MAVs的本地地图,而是在服务器上运行SLAM管道。在edge - slam中,系统通过分割移动设备和边缘设备之间的视觉slam管道来维护本地和全局地图。[45]描述了C2TAM是一个建立在PTAM[31]之上的协作式SLAM框架。该系统将PTAM的跟踪线程保存在客户机上,并将PTAM的映射线程移动到云上。客户端向服务器发送新的关键帧,而服务器在每次优化后向客户端发送完整的映射。这种机制有可能导致客户机耗尽内存,并随着地图大小的增大而产生越来越大的网络流量。Edge-SLAM通过只在客户端维护一个本地地图而不是全局地图来控制内存和网络使用。在[35]中,作者提出了基于orb - slam2[41]的多机器人SLAM系统。CORB-SLAM运行在多个机器人和一个中央服务器上。每个机器人都运行一个ORB-SLAM2实例来构建其环境的地图并将其发送到服务器。服务器将从机器人接收到的地图合并,并将合并后的完整地图反馈给每个机器人。将完整地图发送回客户机可能会导致C2TAM中提到的内存和网络问题。协同SLAM研究可能与我们的工作有一些重叠;然而,方法和目标之间存在差异。大多数协同SLAM的工作集中于从单个机器人构建的较小地图构建一个精确的联合全球地图。他们的架构没有计算卸载;在这些系统中,多个代理独立运行来为一个区域建图。因此,它们在资源使用方面可能无法与Edge-SLAM相提并论。用更小的地图构建全局地图会有Edge-SLAM之外的其他的误差来源。因此,将Edge-SLAM与这些系统进行比较,并不是两种相同的管道功能的比较。
最近的一项研究[52]探讨了如何将视觉SLAM转移到边缘。在本研究中,作者提出了一种边缘辅助单眼SLAM系统建立在ORB-SLAM[40]之上。在较高的层次上,他们的目标与我们的工作相似。然而,仔细检查它就会发现设计和实现上的显著差异。作者通过查看ORB-SLAM模块的内部片段,而不是将每个模块视为一个片段,来做出卸载决定。此外,作者将一种语义分割算法整合到他们的系统中以提高准确性。与我们不同的是,这项研究的重点不是移动设备上的资源限制。相应地,他们的设计并没有解决重新定位问题,他们的研究也没有测量资源(CPU、内存)使用情况或同步边缘和移动设备的开销。此外,整合语义分割使得他们的设计更难在其他视觉slam系统中推广。相反,EdgeSLAM是建立在ORB-SLAM2 [41] (ORB-SLAM的改进版本)之上,并整合了视觉slam的所有方面,包括重新定位以及单目、立体和RGB-D相机的工作能力。我们的设计和实现侧重于移动设备上的资源使用,我们的工作广泛评估了实现的这些方面。

图2:一个典型的Visual-SLAM系统[2]的架构
3.系统设计
3.1一个典型视觉slam系统的概述
第3页的图2是一个典型的基于特征的Visual-SLAM系统的架构图。一些SLAM系统大致遵循这种架构,包括PTAM[31]、LSDSLAM[14]、ORB-SLAM[40]和ORB-SLAM2[41]。一个典型的视觉slam系统的输入是一系列从相机捕捉到的图像(即帧)。虽然我们将这个通用系统描述为一个接受常规图像(RGB)的系统,但许多SLAM系统都能够接受立体图像、深度图像以及颜色和深度图像。大多数视觉slam系统都有以下三个组成部分:
跟踪:跟踪模块检测输入图像(帧)中的特征。典型的特征可以是SIFT、SUR、ORB或角落。跟踪模块然后使用这些特征来找到与前一个参考图像(在许多情况下也称为关键帧)的对应关系。根据两帧之间的特征对应关系,计算参考关键帧与当前帧之间的相对里程(标记帧-帧对齐)。然后,跟踪模块根据一组标准(如特征匹配的数量)确定该帧是否应该作为关键帧添加到地图中。如果它决定添加一个关键帧,它将当前帧传递给局部地图模块。
局部建图:
如果跟踪认为当前帧是新的关键帧,则调用局部映射模块。这个mod ule在新的关键帧和地图中的其他关键帧之间创建对应。然后执行局部束调整;束调整是局部的,因为它限制了对具有共同特征的关键帧的推理。
循环闭合:每隔一段时间(频率取决于特定的算法),SLAM系统从概念上运行Loop Closure过程,这可能需要在每次添加一个新的关键帧时运行。新的关键帧会与地图上的所有其他关键帧进行比较,以检查当前位置(当前图像拍摄的位置)是否与之前访问过的位置相同。如果当前关键帧与之前的关键帧相似,这个模块将对这些关键帧和所有相关的关键帧进行融合。它还可以执行位姿优化,通常作为图形优化[32].
3.2部署Visual-SLAM系统面临的挑战
3.2.1计算复杂度。
通常,循环闭合,或者识别之前访问过的地方的过程是非常耗时的。这是因为这个任务的复杂性随着地图的大小而增加。其次,根据两个不同位置的本地结构,合并地图数据结构的过程可能是任意复杂的。最后,合并后的细化步骤涉及到解决一个可能也很复杂的优化问题。
从历史上看,SLAM算法被设计为在具有相当强大计算能力的机器人上运行。随着这些技术向移动/可穿戴设备转移,以合理的速度运行视觉slam算法是极具挑战性的。此外,SLAM通常是一种用于识别位置或地点的服务。应用程序使用此服务执行addi。这些任务可能需要额外的计算能力,这使得在移动/可穿戴设备上运行一个完整的SLAM系统变得更具挑战性。
3.2.2模块间耦合紧密。
一个想法是在移动设备上运行SLAM算法中的一些模块,同时在edge/cloud上运行其他模块。然而,这是一个挑战,因为所有的模块都是紧密耦合的。如图3页上的图2所示,他们都对全局地图进行操作,并需要比较、修改和修剪地图。访问这个共享数据结构或模块之间的延迟会导致整个系统功能不正常。因此,在视觉slam系统中,简单地卸载部分计算是一个挑战。更好地可视化解耦Visual-SLAM模块的复杂性。我们在4.1.2节中跟踪了ORB-SLAM2[41]中访问全局地图部分的模块。锁的数量以及从多个位置访问各种数据结构说明了模块的紧密耦合。
3.3 Edge-SLAM设计
3.3.1 Edge-SLAM设计目标
我们设计边缘slam的主要目标是减少移动/可穿戴设备上的计算和内存开销,同时不影响视觉slam系统执行的准确性。如前所述,鉴于模块的紧密耦合特性,这是一个挑战。第二个目标是保持总体资源使用(CPU、内存)不变,以允许应用程序在移动设备上平稳运行。如第10页的图7所示,运行Visual-SLAM管道可能会随着时间的推移潜在地需要大量且不断增加的资源。我们的目标是在长期操作中保持这一水平。
3.3.2 Edge-SLAM架构。
第4页的图3所示是边缘slam架构。我们的目标是把一些计算工作转移到“附近”的边缘设备上。然而,这并非如前所述的那么简单。为了实现这一目标,我们做了两个主要的改变。首先,我们建议在移动设备上运行跟踪模块,将局部地图和闭合回路随着全局地图移动到边缘设备。然而,跟踪模块的任务需要地图。为了解决这个问题,我们引入了一个局部地图——驻留在移动设备上的部分地图。这是我们的第二个修改。我们设计本地地图结构是为了满足我们的主要动机之一,即保持移动设备上的资源开销(CPU、内存)不变。从本地/全局地图结构,接着进行拆分。跟踪模块可以完全使用本地地图和is,因此,或移动设备。局部映射地图和循环闭合模块的一些计算需要全局地图。因此,他们被移到了边缘。然后,我们在跟踪模块和本地映射模块之间提供通信机制。由于局部映射和循环关闭模块经常更新全局映射,我们还需要一种机制来在全局地图发生变化时更新局部地图。这将在下面进一步讨论。
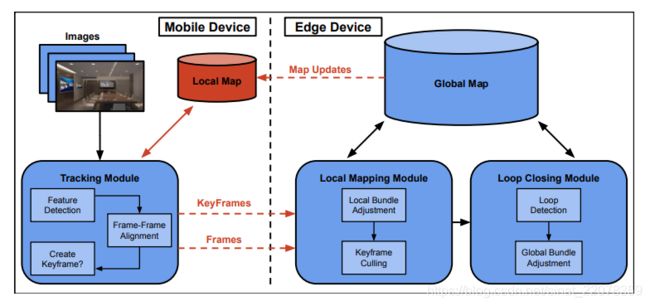
图3:预想的Edge-SLAM系统架构,我们的修改显示在红色[2]中
网络设计:一个关键的设计挑战是移动设备上的跟踪模块和边缘设备上的本地映射/环路闭合模块之间的同步。首先,我们假设在双方之间存在一个合理的连接(例如一个速度类似于本地无线网络的可靠无线连接)。如果不这样做,维持所需的同步量就很有挑战性。如4页的图3所示,我们设计了移动设备和边缘设备之间三个独立的网络连接。这些网络连接中的每一个都独立于另一个运行,因此没有通信的顺序和相应的延迟。
前两个连接用于将跟踪模块的输出传递到边缘设备—它们在第4页图3的下部用红色显示。在重新定位期间,跟踪模块使用一个连接来通信包括特征和局部几何形状的处理帧,并且在第4页的图3中标记为帧。第二个连接用于在跟踪决定创建一个新的关键帧时传递关键帧,在第4页的图3中被标记为关键帧。第三个连接用于更新本地映射。第4页的图3顶部显示了这一点,并标注了Map Updates。这种通信通常是从边缘设备到移动设备。这个连接使本地映射与全局映射保持更新。全局映射跟踪其状态与当前本地映射之间的差异。如果差异被认为很大,它就会创建更新并将更新发送到移动设备。根据当前跟踪的状态,移动设备可以决定是否接受更新。
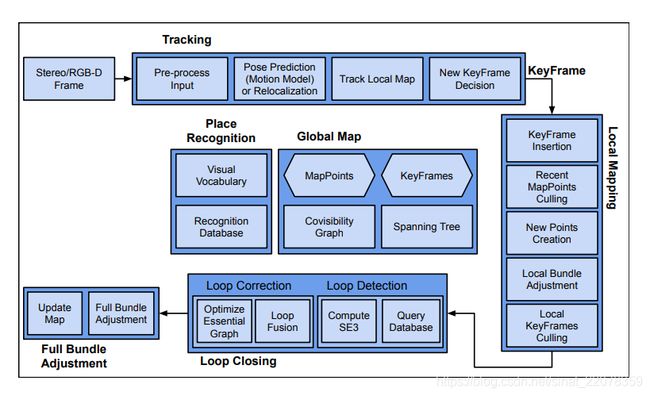
图4:ORB-SLAM2系统架构[41]
更新局部映射:局部映射和循环关闭模块都更新和优化全局映射。他们寻找关键帧之间的局部和全局关系,并不断优化整体地图以保持一致性。然而,由于Edge-SLAM为移动设备创建了一个新的地图结构,为了正确执行跟踪模块,保持它与全局地图同步是很重要的。
每次跟踪模块创建一个新的关键帧时,它都会将它传递给边缘上的本地地图模块。相应地,edge会跟踪移动设备上的本地地图。随着全局地图的变化,它计算地图更新,并将它们发送到移动设备进行更新。然而,在移动设备上更新地图是一个非常耗时的过程,后面将介绍这一点。因此,我们修改跟踪模块,使其具有接受或拒绝地图更新的能力。考虑到这种权衡,我们根据经验确定一种超时机制,以决定本地地图何时失效并需要更新。在原型的实现中讨论了具体的机制。
虽然从概念上讲,这些变化看起来很简单,但要让所有东西都与现实的网络延迟协同工作是一项挑战。为了证明这个架构的可行性,我们在著名的视觉slam系统ORB-SLAM2[41]上建立了我们的原型。我们的工作提供了一个概念设计来卸载视觉slam。为了将其应用到其他视觉slam系统,我们需要将设计的组件映射到特定视觉slam系统的实现,以确定卸载的准确实现。
4. Edge-SLAM在ORB-SLAM2中的实现
第3节描述了我们在Visual-SLAM中卸载一些任务的总体设计。因为它是开源的,所以我们使用ORB-SLAM2创建了我们的想法原型。现在我们将描述ORB-SLAM2,以及我们的EdgeSLAM原型使用ORBSLAM2实现分割架构。请注意,我们提供了一些细节,包括几个使系统工作清晰的神奇数字。
4.1 ORB-SLAM2
4.1.1概述
ORB-SLAM2[41]是最近最先进的基于图形的视觉slam算法,可以使用单目(RGB)摄像机、立体摄像机或RGB-D摄像机来构建稀疏的3-D地图。地图是一种图形,其中顶点对应于图像帧,边对应于它们之间的3d视觉转换。
ORB-SLAM2由三个线程组成,每个模块一个线程:跟踪、本地映射和循环闭包,如第5页的图4所示. 跟踪线程通过传入的图像帧进行初始姿态估计,并根据第1篇ORB-SLAM论文[40]中引入的前四帧和第二篇论文[41]中引入的第五帧的5种条件决定接受哪一帧作为关键帧。它们是:
(1)如果发生了重新定位,那么应该传递20帧来插入一个新的关键帧。
(2)要么在最后一个插入的关键帧之后有20帧通过,要么本地映射线程不忙。
(3)当前帧正在跟踪至少50个特征。
(4)当前帧相对于参考关键帧(即与当前帧最相似的关键帧)跟踪不到90%的点
(5)如果当前帧跟踪少于100个关闭点,并可以创建超过70个新的关闭点。
正如后面所描述的那样,这个细节对于Edge-SLAM非常重要,因为我们的划分要求我们对移动端和边缘端的某些条件进行推理。
局部地图将被接受的关键帧添加到全局地图,并执行映射点和关键帧优化,以及在被接受的关键帧的局部映射上束调整。接下来,本地映射将接受的关键帧传递给循环闭包线程,后者检查循环,后者检查当前关键帧是否类似于之前存储的任何关键帧。如果它们相似,它会执行循环修正,修正关键帧的姿态并优化全局映射。
orbslam2 -关键帧和地图点的操作有两个中心数据结构。如上所述,关键帧是包含环境的独特片段或视点的图像帧。地图点存储位置、特征描述符和对观察它的所有关键帧的引用。在ORB-SLAM2中,地图点是通过检测图像中的orb特征得到的。因此,特征描述符是orb -descriptor。每个关键帧指向几个地图点。同样,多个关键帧可以指向相同的地图点,如果从多个关键帧看到相同的特征。所有当前构建的关键帧的集合,以及它们所有的观察到的地图点组成了当前的全局地图。这三种数据结构相互依赖,并维护一些额外的信息-详细信息可以在[40,41]中找到。地图的一部分是视觉词汇。ORB-SLAM2将其存储起来,以便于比较帧。每个传入的帧都被标记为这个字典中观察到的单词列表。这可以稍后用于快速查找类似的帧—例如用于循环闭包。
4.1.2复杂性
ORB-SLAM2是一个开源系统,有20个类,约18000行代码,系统依赖于三个主线程同时运行,每个主线程运行一个模块,即跟踪,局部映射,循环关闭。此外,在每次循环关闭后,系统按需启动第四个线程来执行完整的bundle调整。ORB-SLAM2的复杂性在于所有这些线程都在一个共享的全局映射结构上工作。为了演示这些线程之间的耦合级别,第5页的表1列出了ORB-SLAM2代码中使用的锁集、它们控制访问的数据结构,以及在各个模块中调用它们的次数。例如,我们观察表中的地图数据结构mMutexMap收购等跟踪模块执行六个操作Tracking::UpdateLocalMap(),在当地执行六个操作映射模块如LocalMapping:: MapPointCulling()来执行一个操作LoopClosing: :CorrectLoop()循环关闭模块,调整和执行完整的包。在ORB-SLAM2中,所有三个线程都假定在相同的计算设备上执行,并能够访问由系统维护的全局映射。每个线程的操作相互依赖,因为它们依赖于共享的数据结构。
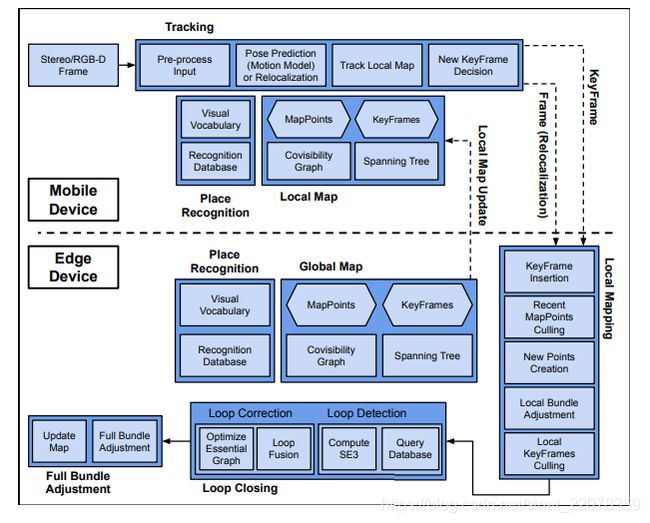
图5: Edge-SLAM系统架构
4.2 Edge-SLAM 实施
第6页的图5将edge - slam分解为运行在移动设备上的组件和edge。如前所述,在edge - slam分割架构中,跟踪线程运行在移动设备上,而本地映射和循环关闭线程运行在边缘上。
全局地图:全局地图创建并存储在边缘。它包含完整的关键帧集、映射点集、共可见性图和生成树。协同可见图基于他们共享的地图点观测连接关键帧。生成树是共可见性图的一个子集,连接每个关键帧与共享最多映射点的关键帧。
本地地图:我们在移动设备上的跟踪线程中创建名为本地地图的新地图结构。它包含一个子集。最新创建的关键帧、地图点、共可见图和全局地图生成树。它使用的视觉词汇和识别数据库与边缘的那个一样。
地图同步:edge定期向移动设备发送最新优化的本地地图更新。另一方面,移动设备会立即将新创建的关键帧连同它的地图点发送到边缘。在接收到更新时,移动设备可以选择是否更新本地地图。edge总是接受来自移动设备的新关键帧。
4.3 Mobile-Edge网络搭建
如第3节所述,模块之间的延迟会极大地影响视觉slam系统的工作。为此,我们在移动设备和边缘之间有三个独立的连接-每个连接在重新定位事件时从移动设备传输帧到边缘,并从边缘传输关键帧,为此,我们有三个独立的移动设备之间的连接和边缘分别从移动设备到边缘传输帧再本地化事件后,将关键帧从移动设备到边缘,和第三将从边缘地图更新发送到移动设备。在优先考虑系统性能的情况下,我们使用快速阻塞并发队列实现3进行线程间通信。我们的结果表明,这样的设置对边缘slam系统的整体工作有较低的开销。
现在我们将描述在手机和边缘上的Edge-SLAM。
4.4移动设备操作
在我们的设计中(第6页的图5),移动设备运行跟踪线程。为了解耦移动设备操作,我们允许跟踪线程维护本地地图,创建新的关键帧,创建新的地图点,并接受来自边缘的地图更新。如ORB-SLAM2。Edge-SLAM中的跟踪线程不断地处理来自相机的输入feed/帧,跟踪本地地图,估计当前帧的初始位置,并决定哪个帧是关键帧。然而,在边缘slam中,边缘上的本地地图并不接受移动设备上的跟踪所创建的所有关键帧。这是因为我们将4.1节中描述的关键帧创建条件拆分为移动设备和边缘之间,这取决于每个条件的验证位置。我们将条件1和2移动到边缘的局部贴图中,并保持条件3和4。5在移动设备上。如果要创建一个新的关键帧,它会在本地映射中创建一个新的关键帧,并发送一个副本到边缘,以便考虑添加到全局映射中。当移动设备接收到本地地图更新时,它首先检查它是否多余。一个地图更新被认为是冗余的,如果没有新的关键帧创建自最后应用的地图更新秒,移动设备检查是否应用本地地图更新将显著增加失去跟踪的机会,因为它的延迟。我们应用一个从300毫秒开始的时间限制,这个时间限制随着本地映射中关键帧数量的增加而减少。这样的时间限制将限制移动设备上本地地图的大小。当关键帧创建率很高时,它也会阻止本地地图更新被应用。通常情况下,当场景中出现表明设备快速移动的较大变化时,会创建更多的关键帧。在这种情况下,中断map更新将导致丢失跟踪,这是不可取的,因此,只有在距离上次创建的关键帧超过时间限制时,本地地图更新才被接受。我们使用以下公式来计算时间约束:
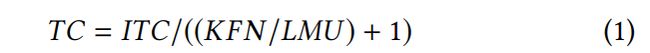
其中TC为时间约束,ITC为初始时间约束(设置为300ms), KFN为当前本地地图中的关键帧数,LMU为本地地图更新大小(设置为6个关键帧)。我们将在4.7节中讨论选择这些数字的原因。
当本地映射更新被接受时,跟踪线程将暂时停止操作,不处理任何新的帧。移动设备通过完全清除当前地图来更新本地地图,然后使用接收到的更新构建一个新的地图。因为关键帧在创建时被发送到边缘,所以当清除当前本地映射时不会丢失任何信息。这是一个耗时的过程,我们将在第5节中展示所涉及的延迟。
4.5边缘侧操作
如前所述,edge运行两个线程:本地映射和循环关闭。本地映射线程在创建关键帧时从移动设备接收关键帧,并定期向移动设备发送本地映射更新。另一方面,循环关闭线程与本地映射线程交互以接收新的关键帧,在它们被处理并添加到全局映射后,然后它继续处理ORB-SLAM2。当边缘设备上的本地映射线程收到一个新的关键帧时,它检查剩余的关键帧插入条件,即条件1和条件2描述。
在Edge-SLAM中,移动设备维护本地地图以保持系统运行。这张地图不打算长期使用。因为本地映射和环路闭合运行在边缘,跟踪本地映射(在移动设备上)没有得到优化,如果它没有定期接收到更新,可能会漂移并影响系统精度。因此,我们的目标是最大化更新的数量,以最小化跟踪线程中的漂移。然而,最大化更新次数也意味着更多的网络使用以及增加跟踪线程的map重构开销。在Edge-SLAM中,我们在本地映射线程中实现了一个基于定时器的更新模块,在短时间间隔内以尽可能少的关键帧数量定期发送本地映射更新。这样的更新将纠正移动设备本地地图的任何偏差和不一致。在我们的更新模块中,每5秒发送一次本地地图更新,由插入全局地图及其所有地图点的6个最近的关键帧组成。通过短时间间隔发送小地图更新,我们实现了最小化漂移、最小化地图重建开销和限制网络使用的目标。我们将在第5节中量化所有这些。在4.7节中,我们将更详细地讨论为什么局部地图更新包含6个关键帧。
4.6实现权衡
4.6.1本地地图更新策略。
有两种典型的方法可以在移动设备上更新本地地图。第一种方法是将边缘更改应用到移动设备的当前本地地图。第二种方法是清除移动设备当前的本地地图,并将其替换为从边缘接收到的新的本地地图更新。运行几个实验后,我们识别了使得第一个方法不是有效的和不安全的的以下问题,这:如果我们继续重用当前移动设备上的本地地图应用更改,然后我们将积累大量的未经加工的和非关键帧和映射点在本地的地图。这样的关键帧和地图点也将有助于创建新的不准确的关键帧和地图点,并增加漂移的机会和较低的精度在全球地图的边缘。对当前本地地图应用更改需要花费大量的时间搜索更新中的每个关键帧和地图点,以查找它们在本地地图结构中的所有引用。这将显著增加应用更新的时间复杂性,并降低移动设备的性能。
由于OBR-SLAM2的复杂结构,在数据结构中存在大量的循环引用。因此,对当前本地映射应用更改会增加内存问题(如内存泄漏)的可能性。移动设备上的本地映射结构在不同的线程之间共享。这需要一些机制来避免映射上的并发操作,以实现正确的功能。因此,各个线程使用锁等同步机制来简化它们的访问。隔离这样的数据结构进行更新将耗费大量的时间,并可能导致整个系统的错误操作。因此,无论我们是立即接收更新还是定期接收更新,应用更新的过程都会迅速增加丢失跟踪的机会,并降低移动设备的性能。相比之下,第二种方法更安全、更有效,对移动设备的副作用也更少。在这种方法中,本地地图更新完全取代现有的移动设备本地地图,由于更新的规模较小,对移动设备性能的开销可能最小。
4.7工程Edge-SLAM模块高效运行
4.7.1跟踪线程。
Edge-SLAM有4个参数:局部地图更新大小(在4.7.2节中讨论),局部地图更新频率(在4.5节中讨论),重新定位帧频率(在4.7.4节中讨论),以及接受局部地图更新的时间约束(在本节中讨论)。此外,Edge-SLAM对ORBSLAM2参数很敏感。因此,不正确设置这些参数会影响系统性能正如我们在第4.4节中讨论的,跟踪线程计算一个时间约束值,该值用于决定是否接受本地地图更新。我们最初将其设置为300毫秒。我们选择初始时间约束值的目的是控制跟踪局部地图在更新之前能得到多大,特别是在高关键帧创建率的情况下。同时,我们想让移动设备在短时间内独立工作,而不考虑与边缘的连接。经过几次实验,我们发现在高关键帧创建阶段,300ms的初始时间约束值最有可能导致跟踪线程在本地地图大小超过50个关键帧之前接受本地地图更新。
4.7.2本地映射线程。
如前面4.5节所述,当局部建图线程准备一个局部地图更新发送到移动设备时,它将更新的大小设置为6个关键帧。当我们设置本地地图更新的大小时,我们的主要目标是减少网络使用量,并减少移动设备上的地图重建开销。因此,在研究了跟踪线程的初始化过程,我们发现如果系统丢失了跟踪且在地图中少于6个关键帧,跟踪线程将重置整个系统。它将假定系统在初始化后立即丢失了跟踪。基于这个条件,局部地图可以在不重新设置系统的情况下继续工作的最小关键帧数是6,这是我们选择的局部地图更新大小。
4.7.3复位功能。系统和用户都可以调用重置函数。初始化失败后,系统调用reset函数。每当调用reset函数时,系统将清除所有数据结构并重新启动映射进程。在Edge-SLAM中,我们没有添加任何新的数据结构来执行完整的(mobile-edge)系统重置。相反,跟踪线程使用相同的关键帧连接,在将关键帧的reset标志设置为true后重新发送最近的关键帧。这样,在收到来自系统或用户的请求时,双方都将立即重置。
4.7.4 Relocalization函数。当跟踪线程试图使用全局地图重新计算相机姿态时,它会失去跟踪,这时就会调用Relocalization函数。当跟踪线程在之前访问和映射过的位置失去跟踪时,重新定位特别有用。在Edge-SLAM中,我们希望重新定位能像ORB-SLAM2一样强大。为此,当我们的系统失去跟踪时,它不仅尝试使用当前本地地图重新定位,而且还向边缘发送重新定位请求以寻求帮助。这就是为什么我们将移动设备和边缘之间的一个连接用于帧的传输,以帮助重新定位。当移动设备上的跟踪线程失去跟踪时,它每半秒向边缘发送一帧。我们选择每半秒发送一帧,以允许场景中发生一些变化,这样我们就不会发送冗余的帧。边缘的局部映射使用接收到的帧从全局映射中检测候选关键帧进行重新定位。然后它发送一个重新定位地图更新到移动设备,以便移动设备可以尝试从地图估计相机姿势。重新定位地图更新除了连接到每一个关键帧之外,还包括候选关键帧。当Edge-SLAM试图重新本地化时,它将取消所有强加于本地地图更新的时间和大小限制。这是因为在此期间,成功的重新本地化比性能更重要。我们在5.5节比较Edge-SLAM和ORB-SLAM2的重新定位统计数据。
5.评估
5.1实验设置
为了评估edge - slam系统,我们使用两个不同的移动设备和一个edge设备进行了实验。第一款移动设备是NVIDIA JETSON tx2 -64位NVIDIA Denver和ARM Cortex-A57 cpu。NVIDIA Pascal GPU, 256个cuda内核,8gb内存,连接802.11ac wlan -运行Ubuntu 18.04LTS。这是一个典型的计算平台,可以与Magic Leap One AR眼镜[28]的处理能力相媲美。第二款移动设备是戴尔Latitude笔记本电脑——英特尔酷睿i5-520M (2.4GHz, 3M高速缓存)(双核),英特尔具有动态频率的高清显卡,8gb内存运行Ubuntu 18.04LTS。这个计算平台与微软HoloLens[38]上的资源大致相当。edge设备是戴尔XPS台式机-英特尔酷睿i7 9700K(8核/8线程,12MB缓存,所有内核超频高达4.6GH2), NVIDIA GeForce GTX 1080, 32gb内存-运行Ubuntu 18.04LTS。
我们使用预先收集的校园建筑楼层之一的RGB-D数据集作为长期运行实验的输入源。我们的数据集是使用配备Kinect 360 RGB-D传感器的机器人以及Velodyne VLP-16激光雷达来收集真实值的。数据集包含52,427帧,运行总时间为1,774秒(=30分钟)。我们在每个平台上重复我们的实验,重复播放这些帧,就好像它们是当时收集的一样。这允许我们提供跨不同平台的准确性能比较,并且是跨SLAM系统[6]比较性能的标准机制。Kinect的典型帧率是30fps,这是我们回放数据集的速度。然而,在八个位置,当机器人转弯时,我们观察到ORB-SLAM2系统无法找到对应。经过反复实验,我们发现当机器人转动时,将走廊尽头的帧率降低到每秒15帧,系统就可以保持通信并继续构建地图。请注意,这是ORB-SLAM2的一个缺点,修复这个缺点超出了本工作的范围。因此,在每次实验中,我们都会在靠近回合的地方将帧率降低到15帧每秒,然后在其他位置以30帧每秒的速度重放。这种重放模式与下面所有结果中的ORB-SLAM2和Edge-SLAM的评估是相同的。
我们还使用来自慕尼黑技术大学的一个流行的公共数据集,称为TUM 26 RGB-D数据集,用于短期实验,并以30fps的速度运行它们。帧从存储中读取并作为ROS主题发布,供ORB-SLAM2或Edge-SLAM使用。移动设备连接到不同的校园Wi-Fi网络,edge通过模拟实际部署的有线连接连接到校园网络。请注意,我们在一天中的所有时间都进行了实验,由于多个用户使用相同的访问点,我们的结果本质上捕获了网络动态。
使用这个设置,我们比较四种配置的结果:
在JETSON TX2上运行ORB-SLAM2。实验结果参考ORB-SLAM2 JTX2。
在戴尔Latitude笔记本电脑上运行ORB-SLAM2。我们用ORB-SLAM2 L表示实验结果。
在JETSON TX2和edge Dell上运行Edge-SLAM XPS桌面。我们用Edge-SLAM JTX2-D来表示这个实验的结果。
在戴尔Latitude笔记本电脑和戴尔XPS台式机上运行edge - slam。实验结果用EdgeSLAM L-D表示。
5.2 Edge-SLAM性能
提醒一下,Edge-SLAM的两个目标是减少移动设备上的计算负载,并保持负载不变。我们的第一组结果显示了完全在移动设备上运行Visual-SLAM (ORB-SLAM2)和卸载运行Visual-SLAM (Edge-SLAM)的计算复杂度。如果没有指定,它们都是数据集上的平均结果。第10页(左)的图6显示了在四种配置中每一种配置中运行单个模块(跟踪、本地映射和循环关闭)所花费的平均时间(以毫秒为单位)。从第10页(右)的图6中可以看出,跟踪线程平均用时不到80ms。原来的ORB-SLAM2跟踪模块和Edge-SLAM的跟踪模块在执行延迟方面也没有太大的差异。这是期望的两个模块与Edge-SLAM中与本地map交互的跟踪模块相似,但没有任何显著的性能影响。但是,局部映射和循环闭包模块的执行时间有很大的不同。我们想就这些结果发表一些看法:
这些模块运行在ORB-SLAM2的JETSON-TX2/笔记本电脑上,而edge - slam则运行在edge(桌面电脑)上,后者拥有更强大的CPU,相应地可以更快地执行模块。然而,这种比较是合理的,因为这是卸载吸引人的主要原因。
当跟踪模块被持续地执行来处理传入的帧时,本地映射和循环闭合模块不会被执行。只有当跟踪模块认为一个帧需要注册为关键帧时,本地映射模块才会执行。Loop closure模块为每个创建的关键帧运行部分以检查循环,如果检测到循环则运行全部。我们的数据集总共有~52,400帧,我们的系统要处理~39,500帧。它创建了大约1200个关键帧。因此,局部映射和循环闭包(部分运行)模块被调用1.200次。
最后,在我们的数据集中出现了两个循环闭包,分别发生在中间和末尾。从第10页的图7(两个子图)可以看出,ORB-SLAM2在移动设备上运行时的执行时间分别为~60%和~95%。虽然循环闭合在我们的数据集中只发生了两次,但我们可以根据用户遵循的轨迹设想在其他场景中发生更多的情况。
对于视觉slam中每个模块的平均处理延迟的结果,我们想做两个观察。首先,边缘slam通过将本地映射和循环关闭模块卸载到边缘来减少延迟。它极大地减少了循环闭合模块的延迟,允许更快的映射更新。我们的第二个观察结果是,通过卸载密集型任务。我们减少了移动设备上性能的可变性,并允许移动设备运行终端用户应用程序,这是首先运行Visual-SLAM的主要原因。这实现了我们的第一个目标,即减少移动设备上的总体计算负载。下一个重要的性能结果显示在第10页的图7中。第10页(左)的图7显示了在移动设备上执行时的瞬时CPU使用情况。平均而言,ORB-SLAM2在使用JETSON TX2时的CPU使用率为~30%,在使用笔记本时为-40%。相比之下,使用Edge-SLAM的JETSON TX2的CPU使用率为~15%,使用笔记本电脑的CPU使用率为~25%。总的来说,使用Edge-SLAM可以减少35-50%的CPU使用。第10页(右)的图7显示了ORB-SLAM2和Edge-SLAM在移动设备上的内存使用情况。如第3节所述,随着map大小的增加,存储它所需的总体内存也会增加。如果全局地图存储在移动设备上(如ORB-SLAM2),这将导致内存使用量的增长,这是非常不可取的。还要注意,当执行循环闭合时,内存使用量会增加(大约60%和95%执行时间)。这也是不可取的。因为Edge-SLAM在移动设备上存储一个固定大小的本地地图,所以Edge-SLAM的内存使用是恒定的。即使在循环闭合期间,它也保持不变。这实现了我们的第二个目标,即保持移动设备上的资源使用不变。

图6:ORB-SLAM2和Edge-SLAM的总体延迟。每个模块的平均延迟(左图)显示了Edge-SLAM减轻了两个cpu密集型任务的负载。随时间移动设备上的跟踪模块延迟(右)更好地显示了每个配置中该模块的延迟
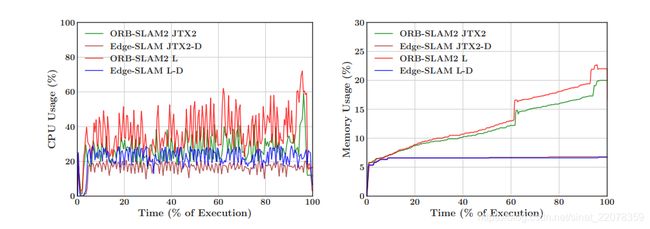
图7:ORB-SLAM2和Edge-SLAM在移动设备上的资源使用CPU(左)和内存(右)。60%的时间和95%的时间(正确)内存使用的跳跃是由于ORB-SLAM2中的循环闭包
5.3网络性能
如第5.1节所述。我们使用常规的校园无线网络将移动设备与edge连接起来。我们还在正常的工作时间进行实验,当接入点被许多用户使用时。我们这样做是为了了解在普通城市设置中施加的网络延迟,以及它对边缘slam系统的影响。在第4页的图3中,我们展示了移动设备和边缘设备之间的三个链接。我们描述了我们所实验的两种边缘slam构型的延迟。最大的延迟来源是地图从全局地图的边缘到移动设备上的本地地图的更新。这个延迟如第10页的表2所示。总的来说,这个延迟有三个部分。首先是在边缘上构造地图更新的延迟。第二,将更新发送到移动设备。最后,一旦接收到更新,移动设备需要重建地图。第10页上的表2显示了这个延迟的第一部分和第三部分。构建更新是在边缘上完成的,耗时58毫秒。然而,重建需要285到411ms,这是很长的时间。还需要注意的是,在移动设备上重建本地地图时,无法执行跟踪模块。每个地图更新由最新创建的六个关键帧组成。第11页的表4显示了通过无线networkÐboth专用和公共传输关键帧时的网络延迟。鉴于校内公共网络的带宽高于专用网络;与私有网络networkÐ142ms相比,公共网络上的关键帧传输速度更快,平均为162ms。然而,就像我们在下一小节中所展示的那样,边击系统在两种情况下都可以工作,在映射时几乎没有额外的错误。

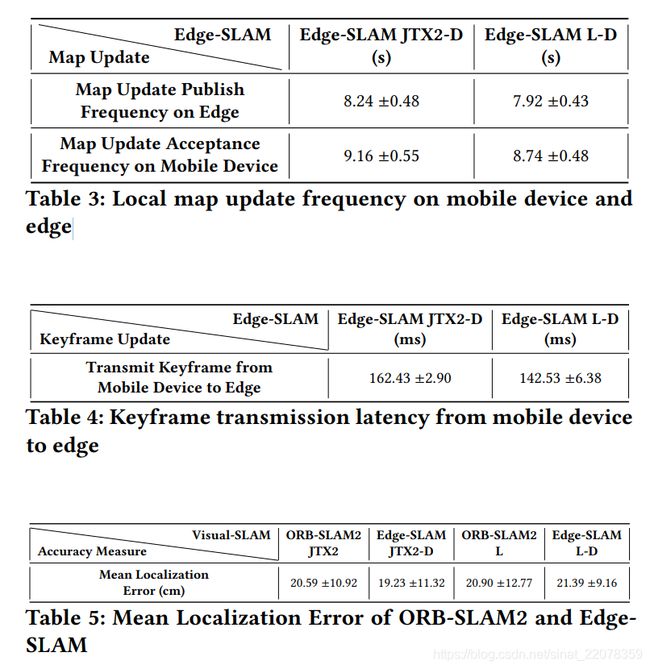
最后,第11页的表3显示了我们实验中地图更新的频率。请注意,移动设备可能会选择不接受由edge传输的地图更新。我们展示了传输的地图更新的平均频率以及接受的地图更新频率。我们的结果表明,移动设备很少拒绝地图更新,至少在我们的数据集上是这样。约每9秒就接受地图更新。
5.4地图精度
我们的主要目标是提高Visual-SLAM在移动设备上运行时的执行性能。这一目标的隐含意义是保持重新设计的视觉slam系统所实现的定位和绘图的准确性。在这一小节中,我们将比较Edge-SLAM和ORB-SLAM2的性能。用ORB-SLAM2和Edge-SLAM构建的移动设备追踪路径的二维轨迹如图12页图8所示。在映射轨迹和地面真实轨迹之间的最小差异表明Edge-SLAM系统在精度上可与ORB-SLAM2相媲美。为了进行更详细的检查,我们在第11页的表5中显示了两个平台上以厘米为单位的球体撞击和边缘撞击的平均定位误差。每个系统在一个平台上表现更好,在每个情况下,在=150m长度的轨迹上平均相差=1cm。对于大多数应用程序来说,在移动设备上长期部署精确的定位/地图是可以接受的。
另外,ORB-SLAM2的绘图精度也很好。从第11页表5的结果可以看出,它在移动了150m后只移动了-20cm,这是比较小的。固有的延迟,以及使用较小的地图(本地地图),往往会增加边缘slam中的潜在漂移/错误。然而,我们的研究结果表明,运行边slam在移动=150m后的漂移与ORB-SLAM2相似,即20cm。这是因为ORB-SLAM2在每次循环闭合后都会执行完整的束调整。这个过程优化全局映射以减少漂移。在我们的实验中,我们的数据集有两个循环,其中ORB-SLAM2必须运行完整的bundle调整。然而,edge - slam不得不运行三次完整的bundle调整,因为循环关闭模块运行在边缘,具有更强的计算能力和更低的延迟,这使一个循环能够检测并运行额外的完整bundle调整
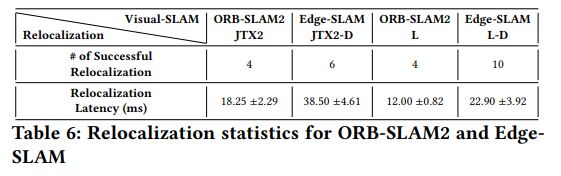
5.5 Relocalization延迟
在本小节中,我们将说明拆分架构对重新定位性能的影响最小。我们使用一个公共数据集[26]RGB-D数据集进行了四个实验,数据集运行速度为30fps。在运行此数据集时,两个系统,即ORB-SLAM2和Edge-SLAM,都失去了跟踪,并多次成功地重新定位。这是因为该数据集中的相机在运动时会抖动多次。第11页的表6显示,我们的系统成功地重新本地化了很多次,比ORB-SLAM2还要多几次。这是因为Edge-SLAM中的跟踪模块使用了local-map,因此它比ORB-SLAM2有更少的特征,因为它比全局地图有更少的关键帧。这就是额外重新本地化的原因。第11页的表6也显示了EdgeSLAM的拆分架构对重新定位延迟的影响最小。当我们的系统失去跟踪时,它不仅向边缘发送重新定位请求,同时还试图使用现有的本地地图进行重新定位。因此,两个系统的重新定位延迟平均都小于40毫秒。球击2的平均时间在12到18毫秒之间,边缘击的平均时间在22和38毫秒之间。EdgeSLAM的额外开销来自于每半秒序列化一帧以将其发送到边缘。否则,EdgeSLAM和ORB-SLAM2拥有几乎相同的延迟。
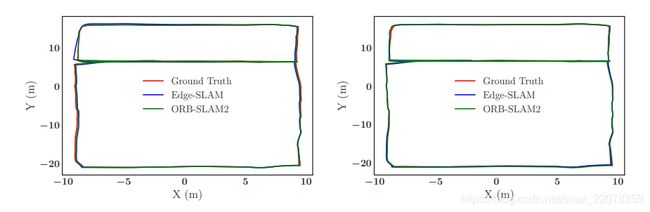
图8:在《JETSON TX2》(左)和笔记本电脑(右)上运行的ORB-SLAM2和Edge-SLAM轨迹与地面情况的比较。Ede-SLAM在IETSON TX2上连接校内私网,在笔记本电脑上连接校内公网
6结论
许多移动应用包括增强现实应用(以及ARCore等库)。ARKit和HoloLens API)需要空间定位。实现这一点的一个流行机制是使用视觉SLAM。然而,大多数视觉slam系统都是计算密集型的。在这项工作中,我们将Visual-SLAM适应于一个称为edge - slam的分裂架构,在移动设备和edge设备之间分配计算负载。我们通过使用ORB-SLAM2(一种流行的视觉slam系统)构建边缘slam架构原型来演示我们的提议。特别是我们将跟踪模块移动到移动设备上,将局部映射以及闭环模块移动到边缘。我们通过在移动设备上创建一个名为local map的新地图结构来实现这个分割,以供跟踪模块使用。此本地映射只包含全局映射的本地视图,并在需要时由边缘定期更新。在Edge-SLAM中,我们克服了ORB-SLAM2的两个挑战,我们通过增加地图大小来限制内存使用量的增长,并保持移动设备内存使用量不变。我们还将突发计算任务(本地映射和循环关闭)移动到边缘设备,允许移动设备更有效地运行,并允许运行其他应用程序。总的来说,我们在最终地图和轨迹上的准确性损失最小。我们使用自己的数据集和公开可用的数据集演示了这一点。我们已经在其他多个数据集上内部测试了我们的系统,结果是相似的。我们开源了我们的Edge-SLAM实现,并让其他研究人员可以使用Edge-SLAM来评估他们的解决方案在未来,我们希望在一个长期的设置中部署边击,并观察在几天内执行边击的挑战。我们感兴趣的是大型城市空间的众包地图,以及跨设备定位的推理。
致谢
我们要感谢Yash Narendra Saraf在网络实施方面的协助。我们感谢Steve Ko和Sofiva Semenova对这项工作的早期讨论。作者受到国家科学基金(nsf# 1846320)和国家科学基金(nsf# 1514395)资助。我们要感谢我们的牧者Nicholas Lane和匿名评论者对改进这项工作的反馈。