数据增强系列(3)Albumentation 初窥
在这篇文章中,我将通过示例全面介绍 使用最广泛的图像增强库之一Albumentation。您应该能够从这篇文章中建立对Albumentation的基本了解,并最终在您自己的工作中进行尝试。
1.什么是Albumentation?
在您了解 Albumentation 有什么帮助之前,了解图像增强在计算机视觉中的含义至关重要。
深度神经网络,尤其是卷积神经网络 (CNN),更擅长图像分类任务。最先进的 CNN 甚至已被证明在图像识别方面的表现超过了人类 。图像增强是获取训练数据集中已有的图像并对其进行操作以创建同一图像的许多更改版本的过程。这既提供了更多的图像来训练,也可以帮助我们的分类器暴露于更广泛的照明和着色情况,从而使我们的分类器更健壮。
Albumentation 是一种工具,可以在将图像送入模型之前对图像进行 [弹性、网格、运动模糊、移位、缩放、旋转、转置、对比度、亮度等]操作。
官方 Albumentation 网站将自己描述为:
Albumentations 是一个 Python 库,用于快速灵活的图像增强。Albumentations 有效地实现了丰富多样的图像变换操作,这些操作针对性能进行了优化,同时为不同的计算机视觉任务提供了简洁而强大的图像增强界面,包括对象分类、分割和检测。
2.为什么要使用 Albumentation?
Albumentation 与其他图像增强相关软件包的区别在于,
2.1 它很快
该软件包已通过多个基于 OpenCV 的库(包括 NumPy、OpenCV、imgaug)进行了优化。
我的深度学习 Python 框架是 Pytorch,所以我最初接触到TorchVision 原生 提供的 torchvision.transforms 的使用。Torchvision.transforms 已经提供了非常可靠的自定义增强方法和文档,所以我一直坚持使用它的产品。
在寻找更好的增强开源库时,我发现了这个 Albumentation 包。而且我发现它非常快,高度可定制,最重要的是,只需 <5 分钟即可将 Torchvision 代码重构为 Albumentation。
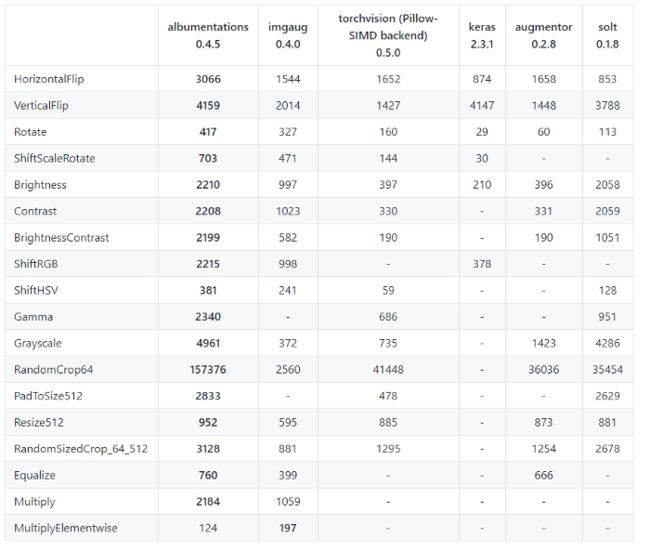
上图是使用 Intel Xeon Platinum 8168 CPU 在 ImageNet 中通过 2000 个验证集图像的测试结果。每个单元格中的值表示在单个核心中处理的图像数量。您可以看到 Albumentation 在许多转换方面比所有其他库至少高出 2 倍。
2.2 教程
对于项目范围,我将介绍 Albumentation 中的关键组件和用法。该代码集主要基于 Albumentations 团队的教程笔记本。我参考了以下笔记本:migrating_from_torchvision_to_albumentations.ipynb
2.2在 Google Colab 中挂载 Google Drive
我一直使用 Google Colab 来制作简单/可共享的笔记本原型。他们的 Jupyter 是免费的,您可以使用免费的 GPU!
您可以使用以下代码将照片上传到 Google Drive 并将 Google Drive 挂载到 Colab。
from google.colab import drive
drive.mount("/content/gdrive")
此单元格将返回 URL 。单击 URL 后,您可以检索授权码。复制粘贴此代码并按 Enter,您就可以开始了!
此外,我还将导入本教程所需的所有其他Python库
from PIL import Image
import time
import torch
import torchvision
from torch.utils.data import Dataset
from torchvision import transforms
import albumentations
import albumentations.pytorch
from matplotlib import pyplot as plt
import cv2
import numpy as np
为了演示,我用了意大利美丽的威尼斯街头照片。

2.3 原始的TorchVision数据管道
我通常创建一个 Dataloader 来使用 PyTorch 和 Torchvision 处理图像数据管道。
- 创建一个简单的Pytorch Dataset类
- 调用图像并进行转换
- 用100个循环测量整个处理时间
首先,从torch.util.datas获取Dataset抽象类,并创建一个TorchVision Dataset类。然后我传入图像并使用__getitem__方法进行转换。另外,我使用total_time = (time.time() - start_t来度量它所花费的时间。
class TorchvisionDataset(Dataset):
def __init__(self, file_paths, labels, transform=None):
self.file_paths = file_paths
self.labels = labels
self.transform = transform
def __len__(self):
return len(self.file_paths)
def __getitem__(self, idx):
label = self.labels[idx]
file_path = self.file_paths[idx]
# Read an image with PIL
image = Image.open(file_path)
start_t = time.time()
if self.transform:
image = self.transform(image)
total_time = (time.time() - start_t)
return image, label, total_time
然后我们调整图像的大小为256x256(高度*宽度),并随机裁剪为224x224的大小。然后应用水平翻转50%的概率,并将其转换为张量。输入文件的路径应该是你的图像所在的谷歌驱动器的路径。
torchvision_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
])
torchvision_dataset = TorchvisionDataset(
file_paths=["/content/gdrive/MyDrive/5.jpeg"],
labels=[1],
transform=torchvision_transform,
)
然后我们计算从torchvision_dataset提取样本图像并转换它所花费的时间,然后运行100次循环来检查它所花费的平均毫秒。
total_time = 0
for i in range(100):
sample, _, transform_time = torchvision_dataset[0]
total_time += transform_time
print("torchvision time/sample: {} ms".format(total_time*10))
plt.figure(figsize=(10, 10))
plt.imshow(transforms.ToPILImage()(sample))
plt.show()

在我的 Colab 环境中,一百个 Resize + RandomCrop + RandomHorizontalFlip 循环花费了大约 12 毫秒,而最后一张图像的大小为 224x224,如您所见。您还可以看到第 100 张图像发生了翻转!
2.4 Albumentation数据管道
现在我将重构从TorchVision到albuitation的数据管道.与TorchVision类似,我们创建了一个Albumentations Dataset类。
class AlbumentationsDataset(Dataset):
"""__init__ and __len__ functions are the same as in TorchvisionDataset"""
def __init__(self, file_paths, labels, transform=None):
self.file_paths = file_paths
self.labels = labels
self.transform = transform
def __len__(self):
return len(self.file_paths)
def __getitem__(self, idx):
label = self.labels[idx]
file_path = self.file_paths[idx]
# Read an image with OpenCV
image = cv2.imread(file_path)
# By default OpenCV uses BGR color space for color images,
# so we need to convert the image to RGB color space.
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
start_t = time.time()
if self.transform:
augmented = self.transform(image=image)
image = augmented['image']
total_time = (time.time() - start_t)
return image, label, total_time
现在在Albumentation中创建一个变换。在这个例子中,你可以发现一个小小的语法差异,即Torchvision的RandomHorizontalFlip()在Albumentation中产生了与HorizontalFlip()相同的结果。
"""
torchvision_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
])
"""
# Same transform with torchvision_transform
albumentations_transform = albumentations.Compose([
albumentations.Resize(256, 256),
albumentations.RandomCrop(224, 224),
albumentations.HorizontalFlip(), # Same with transforms.RandomHorizontalFlip()
albumentations.pytorch.transforms.ToTensor()
])
执行相同的图像变换,得到平均时间,并可视化结果。
# Same dataset with torchvision_dataset
albumentations_dataset = AlbumentationsDataset(
file_paths=["/content/gdrive/MyDrive/5.jpeg"],
labels=[1],
transform=albumentations_transform,
)
total_time = 0
for i in range(100):
sample, _, transform_time = albumentations_dataset[0]
total_time += transform_time
print("albumentations time/sample: {} ms".format(total_time*10))
plt.figure(figsize=(10, 10))
plt.imshow(transforms.ToPILImage()(sample))
plt.show()
令人惊讶的是,它只花了2.1ms,比Torchvision快了大约6倍!它甚至比我们从官方基准文档中看到的有更大的计算差距,而且裁剪区域似乎也有细微的差别。

3.Albumentations的应用
如您所见,它非常快,而且速度很重要。
- 在代码竞赛中,如果能减少图像处理中的计算瓶颈,其他部分(模型拟合、超参数调优等)可以使用更多的资源。
- 在实际行业中,生产数据库中可能会涌入大量新图像(即每秒 1000 个图像)。想象一下开发一个实时深度学习模型。快速处理图像的方法在模型中至关重要,这可能会影响用户体验并最终影响收入/利润。
- 为了您的学习目的,掌握最新和表现最佳的技术技能是有帮助的,这在构建您自己的项目和求职(即简历)时可能会很有用。
4.更复杂的例子
最后,我将展示如何使用OneOf函数进行增强,我个人觉得这个函数最复杂但在 Albumentation 中很有用:
albumentations_transform_oneof = albumentations.Compose([
albumentations.Resize(256, 256),
albumentations.RandomCrop(224, 224),
albumentations.OneOf([
albumentations.HorizontalFlip(p=1),
albumentations.RandomRotate90(p=1),
albumentations.VerticalFlip(p=1)
], p=1),
albumentations.OneOf([
albumentations.MotionBlur(p=1),
albumentations.OpticalDistortion(p=1),
albumentations.GaussNoise(p=1)
], p=1),
albumentations.pytorch.ToTensor()
])
它的 Resize 和 Random Crop 与之前代码集中具有相同的代码。OneOf随机采用括号内列出的变换之一。我们甚至可以将发生的概率放在函数本身中。例如,如果 ([…], p=0.5) ,它会以 50% 的机会跳过整个变换,并以 1/6 的机会随机选择三个变换之一。
我让它从水平翻转、旋转、垂直翻转中随机选择,并再次让它从模糊、失真、噪声中随机选择。所以在这种情况下,我们允许 3x3 = 9 种组合。
albumentations_dataset = AlbumentationsDataset(
file_paths=["/content/gdrive/My Drive/img5.png"],
labels=[1],
transform=albumentations_transform_oneof,
)
num_samples = 5
fig, ax = plt.subplots(1, num_samples, figsize=(25, 5))
for i in range(num_samples):
ax[i].imshow(transforms.ToPILImage()(albumentations_dataset[0][0]))
ax[i].axis('off')
结果如下:

结论
总而言之,我介绍了图像增强技术,Python 中的 Albumentation 库,并在教程中提供了示例代码。为了该项目,该实验仅使用单个图像进行,但可以发现速度有很大提高。Albumentation 提供了多种转换,因此我强烈建议我的读者从今天开始使用它。
参考目录
https://towardsdatascience.com/getting-started-with-albumentation-winning-deep-learning-image-augmentation-technique-in-pytorch-47aaba0ee3f8