Entropy-based Active Learning for Object Detection with Progressive Diversity Constraint(CVPR2022)
原文链接
根据overview来阐述过程
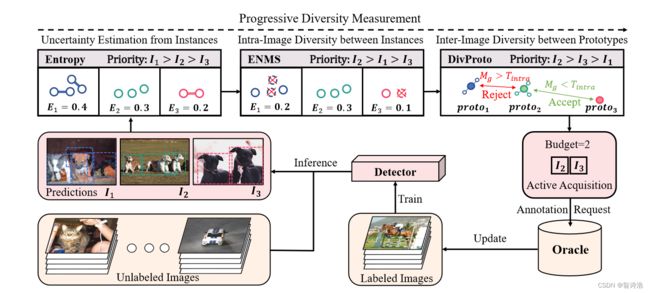 主要分为三步:
主要分为三步:
- Instance uncertainty is first computed based on the entropy.
- ENMS then performs on each image to remove redundant instances.
- DivProto aggregates the instances of each image to prototypes and rejects the images close to the selected ones.
Problem Statement
args
Candidate images: { I i } i ∈ [ n ] \{I_i\}_{i\in[n]} {Ii}i∈[n]
Selected images: S = { I s ( j ) ∣ s ( j ) ∈ [ n ] } j ∈ [ m ] \mathcal{S}=\{I_{s(j)}|s(j)\in[n]\}_{j\in[m]} S={Is(j)∣s(j)∈[n]}j∈[m]1
Budget: b b b
Detect model: D S D_\mathcal{S} DS
each cycle:
Acquire a image subset: Δ S \Delta \mathcal{S} ΔS from S \mathcal{S} S ensure ∣ Δ S ∣ = b |\Delta \mathcal{S}|=b ∣ΔS∣=b.
Then: update S : = S ∪ Δ S \mathcal{S}:=\mathcal{S}\cup\Delta \mathcal{S} S:=S∪ΔS
Then: oracle provide labels: Y = { y s ( j ) } j ∈ [ m ] \mathcal{Y}=\{y_{s(j)}\}_{j\in[m]} Y={ys(j)}j∈[m]
Then: train D S D_\mathcal{S} DS by S \mathcal{S} S and Y \mathcal{Y} Y
Target and meathods
Target
AL 被定义为最小化一个Core-set loss: ∑ i ∈ [ n ] l ( I i , y i ; D S ) \sum_{i\in[n]}l(I_{i},y_i;D_\mathcal{S}) ∑i∈[n]l(Ii,yi;DS)2
作者将detestor D S D_\mathcal{S} DS拆分为两个步骤:
D S = P S + A S D_\mathcal{S}=P_\mathcal{S}+A_\mathcal{S} DS=PS+AS
P S P_\mathcal{S} PS是encoder
A S A_\mathcal{S} AS是predictor
encoder: { p o s k } k ∈ [ t ] ⇒ f e a t u r e \{pos_k\}_{k\in[t]}\Rightarrow feature {posk}k∈[t]⇒feature3
A S ( P S ( I i ) ) = { y ~ i , k , c i , k , p i , k } k ∈ [ t ] A_\mathcal{S}(P_\mathcal{S}(I_i))=\{\tilde{y}_{i,k},c_{i,k},p_{i,k}\}_{k\in[t]} AS(PS(Ii))={y~i,k,ci,k,pi,k}k∈[t]4
那么core-set loss可以拆分为每个实例loss的和,但是作者认为这样不好,因为Lipschitz continuous的问题
Step.1
作者采用instance-level的熵公式:
H ( I i , k ) = − p i , k log p i , k − ( 1 − p i , k ) log ( 1 − p i , k ) \mathbb{H}\left(I_i, k\right)=-p_{i, k} \log p_{i, k}-\left(1-p_{i, k}\right) \log \left(1-p_{i, k}\right) H(Ii,k)=−pi,klogpi,k−(1−pi,k)log(1−pi,k)
那么image-level就是instance熵的和,作者基于这个和对图片进行排序,选择top- K K K个作为acquisition set Δ S \Delta \mathcal{S} ΔS
也就是第一步:Instance uncertainty is first computed based on the entropy
Step.2 ENMS
然后作者说As visually similar bounding boxes contain redundant information which are not preferred when training robust detectors
所以要select the most informative ones and abandon the rest
作者说这种冗余不仅存在于instance-level也存在于image-level中,但是目前没有什么方法能去除,所以作者提出了一个hybrid approach达到了considers the instance-level evaluation and achieves the image-level acquisition in the mean time的效果。
重新阐述一下overview中的三个步骤就是:
- uncertainty estimation using the basic detection entropy
- Entropy-based Non-Maximum Suppression (ENMS)
- the diverse prototype (DivProto) strategy.
上面介绍的熵排序就是第一步从数量上measure the image-level uncertainty from object instances.
随后提出了基于熵的ENMS去除冗余信息的方法,从而加强了图像中的实例级多样性。
最后DivProto通过将实例级的多样性转换为类间和类内的多样性,进一步确保了跨图像的实例级多样性。
层次结构:
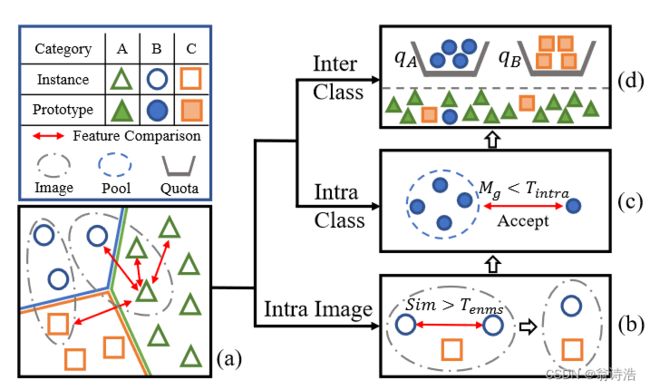 The overall instance-level diversity (a) is divided into the intra-image diversity (b) via ENMS and the inter-image diversity is accomplished by DivProto, which is then decomposed into the inter-class and intra-class ones as shown in © and (d), respectively.
The overall instance-level diversity (a) is divided into the intra-image diversity (b) via ENMS and the inter-image diversity is accomplished by DivProto, which is then decomposed into the inter-class and intra-class ones as shown in © and (d), respectively.
下面介绍ENMS
作者说object detectors often generate a large amount of proposal bounding boxes with heavy overlaps,那么目前的解决方案就是NMS在此基础上,将属于同一实例的边界框合并为统一的边界框。但是NMS无法处理instance-level的冗余,这里要注意的是NMS处理的是一个实例的冗余,而ENMS处理的是实例之间的冗余。
这里的E就是Entropy-based
ENMS作为NMS的successive step
ENMS首先计算两两instance的余弦距离:
Sim ( f i , k , f i , j ) = f i , k T ⋅ f i , j ∥ f i , k ∥ ∥ f i , j ∥ \operatorname{Sim}\left(\boldsymbol{f}_{i, k}, \boldsymbol{f}_{i, j}\right)=\frac{\boldsymbol{f}_{i, k}^T \cdot \boldsymbol{f}_{i, j}}{\left\|\boldsymbol{f}_{i, k}\right\|\left\|\boldsymbol{f}_{i, j}\right\|} Sim(fi,k,fi,j)=∥fi,k∥∥fi,j∥fi,kT⋅fi,j
f i , j \boldsymbol{f}_{i, j} fi,j就是image I i I_i Ii 的instance k k k通过encoder P S P_\mathcal{S} PS得到的特征。
然后ENMS就工作在index集合 S i n s S_{ins} Sins上:

ENMS得到的是一个值 E i E_i Ei它是属于image-level的一个熵,它相当于是优化了Step1中作者定义的 H \mathbb{H} H
Step.3 DivProto
ENMS增强了图像内和图像间的多样性,也就是说,图像之间的冗余仍然存在
作者定义了一个prototype量:
p r o t o i , c = ∑ k ∈ [ t ] 1 ( c , c i , k ) ⋅ H ( I i , k ) ⋅ f i , k ∑ k ∈ [ t ] 1 ( c , c i , k ) ⋅ H ( I i , k ) \boldsymbol{proto_{i,c}}=\frac{\sum_{k\in[t]} \mathbb{1}(c,c_{i,k})\cdot\mathbb{H}(I_i,k)\cdot\boldsymbol{f_{i,k}}}{\sum_{k\in[t]}\mathbb{1}(c,c_{i,k})\cdot\mathbb{H}(I_i,k)} protoi,c=∑k∈[t]1(c,ci,k)⋅H(Ii,k)∑k∈[t]1(c,ci,k)⋅H(Ii,k)⋅fi,k5
下面介绍DivProto
分为两步
首先是Intra-class Diversity
首先按照 E i {E_i} Ei进行排序(降序),给定一个candidata image I i I_i Ii和acquired set Δ S \Delta \mathcal{S} ΔS的prototype值,那么 I i I_i Ii的intra-class diversity量可以定义为:
M g ( I i , [ C ] ) = min c ∈ [ C ] max j ∈ ∣ Δ S ∣ S i m ( p r o t o j , c , p r o t o i , c ) M_g(I_i,[C])=\min\limits_{c\in[C]}\max\limits_{j\in|\Delta\mathcal{S}|}Sim(\boldsymbol{proto_{j,c}},\boldsymbol{proto_{i,c}}) Mg(Ii,[C])=c∈[C]minj∈∣ΔS∣maxSim(protoj,c,protoi,c)
意思就是对于 I i I_i Ii的所有instance的每个类求一个值,这个值是max的prototype余弦角度的最大值,也就是在 Δ S \Delta\mathcal{S} ΔS中找一个与此类最大的相似度,然后取所有类相似度的下限值(min)表示整张图片与 Δ S \Delta\mathcal{S} ΔS的相似度
当 M g ( I i , [ C ] ) M_g(I_i,[C]) Mg(Ii,[C])大于一个阈值的时候就可以把它reject掉,因为这与 Δ S \Delta\mathcal{S} ΔS相似很大了,放进去没价值
然后是inter-class Diversity
上一步有一个缺陷,就是favor certain classes,即可能会导致偏向于一个类,导致类别不平均,这一步就是解决这个问题。
作者的解决思路是adaptively providing more budgets for the minority classes than the majority ones.这里不做详细介绍
T h e E n d . The\ End. The End.
i , j i,j i,j为index, n , m n,m n,m为Candidate set和Selected set的图片数量, [ n ] = { 1 , ⋯ , n } [n]=\{1,\cdots,n\} [n]={1,⋯,n}and [ m ] = { 1 , ⋯ , m } [m]=\{1,\cdots,m\} [m]={1,⋯,m} ↩︎
y i y_i yi 是 I i I_i Ii的潜在label。 ↩︎
k k k即一个图片中的实例index, t t t就是实例个数 ↩︎
y ~ i , k , c i , k , p i , k \tilde{y}_{i,k},c_{i,k},p_{i,k} y~i,k,ci,k,pi,k分表表示boundingbox,class,confidence ↩︎
1 ( c , c i , k ) \mathbb{1}(c,c_{i,k}) 1(c,ci,k)=1 iff c = c i , k c=c_{i,k} c=ci,k ↩︎