浅析Linux操作系统工作的基础
环境:lubuntu 13.04 kernel 3.9.7
作者:SA12226265 katao
简介: 本文根据 Linux™ 系统工作基础的分析,对存储程序计算机、堆栈(函数调用堆栈)机制和中断机制进行概述。文中将为您提供操作系统(内核)如何工作的细节,进一步从宏观概述结合关键点进行微观(CS:EIP、EBP/ESP等的变化)分析。
一、存储程序计算机
首先让我们了解一下,什么是存储程序计算机,并对存储程序计算机的整个运行过程及所需的硬件组件进行简单介绍
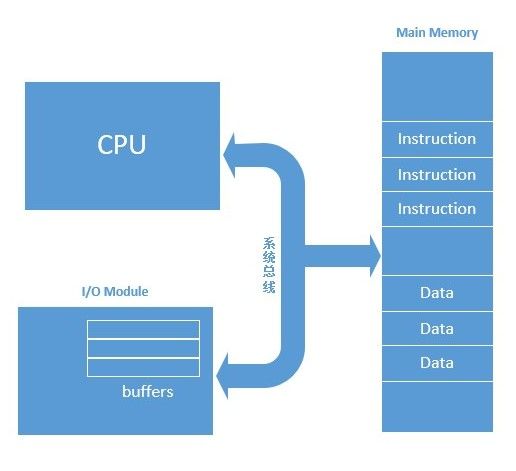
上图是程序存储计算机的物理框架,主要包含CPU(包含各类寄存器,如程序寄存器,指令寄存器等),主存,I/O设备,一个最简单的的程序存储计算机只需要以下部件来完成计算机工作:
– 主存,也就是我们普通PC上内存,用于存储指令和数据
– 处理器, 用于执行算术和逻辑操作
– 控制单元, 解析需要操作的指令集
程序存储在计算机主存当中,并以数据的形式被CPU访问和读写,程序中各条指令都被获取并放到一个EIP寄存器,EIP寄存器中数据控制整个处理单元的运行,取“下一条”指令,继续运行

PC = 程序计数器
IR = 指令寄存器
MAR = 存储器地址寄存器
MBR = 存储器缓冲寄存器
在Linux系统中,一般同时会有几个程序一起运行,运行过程中这些程序的都存储在主存中,而CPU只会在同一时间内运行其中优先级较高的某一个,并根据优先级顺序不断的切换多个进程运行,使得计算机操作者会有多个程序同时运行的错觉。
在存储程序计算机中,最重要的部分就是多个进程的切换,是什么控制着进程间的切换,如何保证进程切换过程中能够使得多个进程运行时不发生混乱,这一切都是由Linux内核控制的,下面我们深入解析Linux内核的在进程切换时的工作机制。
先看调度的方式。
由于调度时机发生时进程在进入了内核态这样,内核必须等待该进程即将结束内核态时才进行切换操作,而进程如果正在用户态时则切换工作会立即执行,所以,一般进程调度发生在当前进程从内核态(包括从系统调用而进入内核态)返回用户态的前夕。至于调度的政策,均按照前面所提到的以优先级为基础的调度。
针对不同的进程有不同的调度政策,主要有SCHED_FIFO,SCHED_RR, SCHED_OTHER(源码集中在kernel\sched 目录下),其中FIFO适用于时间性要求比较高的进程,而RR针对时间片耗尽的进程,由于没有研究过源码这里不做详细描述。
当切换进程已经选好后,就开始用户虚拟空间的处理,然后就是进程的切换switch_to()。所谓进程的切换主要就是堆栈的切换,这是由宏操作switch_to()完成的,定义于\linux-3.9.7\arch\x86\include\asm\switch_to.h中:
1 #define switch_to(prev, next, last) \ 2 do { \ 3 /* \ 4 * Context-switching clobbers all registers, so we clobber \ 5 * them explicitly, via unused output variables. \ 6 * (EAX and EBP is not listed because EBP is saved/restored \ 7 * explicitly for wchan access and EAX is the return value of \ 8 * __switch_to()) \ 9 */ \ 10 unsigned long ebx, ecx, edx, esi, edi; \ 11 \ 12 asm volatile("pushfl\n\t" /* save flags */ \ 13 "pushl %%ebp\n\t" /* save EBP */ \ 14 "movl %%esp,%[prev_sp]\n\t" /* save ESP */ \ 15 "movl %[next_sp],%%esp\n\t" /* restore ESP */ \ 16 "movl $1f,%[prev_ip]\n\t" /* save EIP */ \ 17 "pushl %[next_ip]\n\t" /* restore EIP */ \ 18 __switch_canary \ 19 "jmp __switch_to\n" /* regparm call */ \ 20 "1:\t" \ 21 "popl %%ebp\n\t" /* restore EBP */ \ 22 "popfl\n" /* restore flags */ \ 23 \ 24 /* output parameters */ \ 25 : [prev_sp] "=m" (prev->thread.sp), \ 26 [prev_ip] "=m" (prev->thread.ip), \ 27 "=a" (last), \ 28 \ 29 /* clobbered output registers: */ \ 30 "=b" (ebx), "=c" (ecx), "=d" (edx), \ 31 "=S" (esi), "=D" (edi) \ 32 \ 33 __switch_canary_oparam \ 34 \ 35 /* input parameters: */ \ 36 : [next_sp] "m" (next->thread.sp), \ 37 [next_ip] "m" (next->thread.ip), \ 38 \ 39 /* regparm parameters for __switch_to(): */ \ 40 [prev] "a" (prev), \ 41 [next] "d" (next) \ 42 \ 43 __switch_canary_iparam \ 44 \ 45 : /* reloaded segment registers */ \ 46 "memory"); \ 47 } while (0)
这里的输出部分有三个参数,表示这段程序执行后有三项数据会有改变。其中[prev_sp]、[prev_ip] 都在内存中分别为prev->thread.sp、prev->thread.ip,而最后一个参数则与寄存器EAX结合,对应于参数中的last。而输入部则有4个参数,其中[next_sp]、[next_ip]在内存中,分别为next->thread.sp 与next->thread.ip,剩余的两个参数则与寄存器EAX,EDX结合,分别对应prev,next。
先看开头有两条push指令和结尾处有两条pop指令,再看14行将当前的esp,也就是当前进程的prev的内核态的堆栈指针存入prev->thread.sp,第15行又将新收到调度要进入运行的进程next的内核态的堆栈之争next->thread.sp置入esp。这样一来,CPU在第15行与第16行这两条指令之间就已经切换了堆栈。假定我们有A,B两个进程,在本次切换中prev指向A,而next指向B。也就是说,在本次切换中A为要“调离”的进程,而B为要“切入”的进程。那么,在这里的第12到15行是在使用A的堆栈,而从第16行开始就是在用B的堆栈了。换言之,从第16行开始,“当前进程”,已经是B而不是A了。在内核代码中当需要访问当前进程的task_struct结构时使用的指针current时实际上是宏定义,它根据当前的堆栈指针的ESP计算出所需的地址。如果第16行处引用current的话,那就是已经指向B的task_struct结构了。所以进程切换其实在第15行指令执行完就已经完成了。但是,构成一个进程的另一个要素是程序的执行,所以还要进行其他步骤。由于12,13行事push进A的堆栈,而在 21行至22行从B的堆栈中POP出来,本质就是恢复新切入的进程在上一次被调离时的push进堆栈的内容。理论上了,进程的切换过程中,多个进程都已经在执行了只是暂时的撤离cpu,所以切换过程就是在堆栈之间进程切换。
那么如何完成程序执行的切换,看一下之后的16行至20行。第16行的[prev_ip]所在位置,实际上就是将第21行的pop指令所在的地址保持在prev->thread.ip中,作为进程A下一次被调度运行而切入时的“返回”地址。然后,又将next->thread.ip压入堆栈。所以,这里的next->thread.ip正是进程B上一次被调离时在第16行中保存的。它也指向这里的[prev_ip],即21行的pop指令。接着,在19行通过jmp命令,而不是call命令,转入了一个函数__switch_to()。暂时不讨论__switch_to(),当CPU执行到哪里的iret指令时,由于是通过jmp指令转过去的,最后进入对战的next->thread.ip就变成了返回地址,而这就是[prev_ip]所在的地址,也就是21行的pop指令所在的地址。由于每个进程在被调离时都要执行这里的第16行,这就决定了每个进程在收到调度恢复运行时都是从这里的第21行开始。
上面都是已有进程的切换。但新创建的进程会是怎么样切换的。新创建的进程并没有在“上一次调离时”执行过这里的第12至16行,所以要将其task_struct结构中的thread.ip事先设置好,并且设置“返回地址”时不一定是[prev_ip]所在的地址,这里取决于内核态堆栈的设置。
那么,我们可以看看前面上一篇文章浅析Linux计算机进程地址空间与内核装载ELF中fork()的介绍,这个地址在copy_thread()中确定,由于未能完整的阅读整个process_32.c中的源码,以下内容只是推测如有错误请博友指正,在新进程被创建时,在父进程执行完fork之后只会返回会从调用系统调用时状态,而子进程的“返回地址”也被设置成这个地址,所以__switch_to()一执行ret指令就直接回到了那里。
最后,在__switch_to()中到底干了些什么呢?看一下Linux3.9.7中/arch/x86/kernel/process_32.c 248行
1 __switch_to(struct task_struct *prev_p, struct task_struct *next_p) 2 { 3 struct thread_struct *prev = &prev_p->thread, 4 *next = &next_p->thread; 5 int cpu = smp_processor_id(); 6 struct tss_struct *tss = &per_cpu(init_tss, cpu); 7 fpu_switch_t fpu; 8 9 /* never put a printk in __switch_to... printk() calls wake_up*() indirectly */ 10 11 fpu = switch_fpu_prepare(prev_p, next_p, cpu); 12 13 /* 14 * Reload esp0. 15 */ 16 load_sp0(tss, next); 17 18 /* 19 * Save away %gs. No need to save %fs, as it was saved on the 20 * stack on entry. No need to save %es and %ds, as those are 21 * always kernel segments while inside the kernel. Doing this 22 * before setting the new TLS descriptors avoids the situation 23 * where we temporarily have non-reloadable segments in %fs 24 * and %gs. This could be an issue if the NMI handler ever 25 * used %fs or %gs (it does not today), or if the kernel is 26 * running inside of a hypervisor layer. 27 */ 28 lazy_save_gs(prev->gs); 29 30 /* 31 * Load the per-thread Thread-Local Storage descriptor. 32 */ 33 load_TLS(next, cpu); 34 35 /* 36 * Restore IOPL if needed. In normal use, the flags restore 37 * in the switch assembly will handle this. But if the kernel 38 * is running virtualized at a non-zero CPL, the popf will 39 * not restore flags, so it must be done in a separate step. 40 */ 41 if (get_kernel_rpl() && unlikely(prev->iopl != next->iopl)) 42 set_iopl_mask(next->iopl); 43 44 /* 45 * Now maybe handle debug registers and/or IO bitmaps 46 */ 47 if (unlikely(task_thread_info(prev_p)->flags & _TIF_WORK_CTXSW_PREV || 48 task_thread_info(next_p)->flags & _TIF_WORK_CTXSW_NEXT)) 49 __switch_to_xtra(prev_p, next_p, tss); 50 51 /* 52 * Leave lazy mode, flushing any hypercalls made here. 53 * This must be done before restoring TLS segments so 54 * the GDT and LDT are properly updated, and must be 55 * done before math_state_restore, so the TS bit is up 56 * to date. 57 */ 58 arch_end_context_switch(next_p); 59 60 /* 61 * Restore %gs if needed (which is common) 62 */ 63 if (prev->gs | next->gs) 64 lazy_load_gs(next->gs); 65 66 switch_fpu_finish(next_p, fpu); 67 68 this_cpu_write(current_task, next_p); 69 70 return prev_p; 71 }
这里主要处理的是TSS,核心在16行,把next_p->thread.esp0装入对应于本地cpu的tss的esp0字段;任何由sysenter汇编指令产生的从用户态到内核态的特权级转换将把这个地址拷贝到esp寄存器中。其次段寄存器gs中的内容也做了相应的切换。然后把next进程使用的县城局部存储(TLS)段装入本地CPU的全局描述符表;三个段选择符保存在进程描述符内的tls_array数组中。
所以,除了刚创建新进程外,所有进程在受到调度时的切入点都在宏定义switch_to()中的标号[prev_ip],一直运行到在下一次进入switch_to()以后在__switch_to()中执行ret为止。或者也可以认为,切入点在switch_to()中的21行,一直运行到在下一次进入switch_to()后的19行。总之,这新、旧当前进程的交接点就在switch_to这段代码中。
二、堆栈(函数调用堆栈)机制
接下来,我们分析一下在Linux系统中的函数调用堆栈的机制,之前在浅析Linux计算机工作机制中全面的分析了函数在堆栈调用过程中堆栈中变量及寄存器的数值的变化。
1 pushl %ebp 2 .cfi_def_cfa_offset 8 3 .cfi_offset 5, -8 4 movl %esp, %ebp
即,在程序执行到一个函数的真正函数体时,已经有以下数据顺序入栈:参数,返回地址,EBP。由此得到类似如下的栈结构(参数入栈顺序跟调用方式有关):
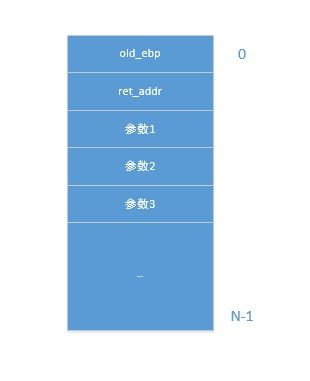
如此形成递归,直至到达栈底。这就是函数调用栈。
三、中断机制
中断是CPU提供的一种功能,不属于linux内核,而对应的中断处理程序则属于内核控制,在执行新指令前,控制单元会检查在执行前一条指令的过程中是否有中断发生,如果有控制大院就会抛下指令,进入下面流程:
1.确定与中断关联的向量i(0<=i<=255) 2.寻找向量对于的处理程序 3.保存当前的“工作现场”,执行中断处理程序 4.处理程序执行完毕后,把控制权交还给控制单元 5.控制单元恢复现场,返回继续执行原程序
所以整个中断的处理过程中,对于CPU,处理过程是一样的,中断现行程序,转到中断服务程序处执行,回到被中断的程序继续执行。CPU总共可以处理256种中断。
那什么是中断处理程序,在介绍中断处理程序之前,让我们先了解一下什么是软中断、tasklet和工作队列:
软中断:软中断是利用硬件中断的概念,用软件方式进行模拟,实现宏观上的异步执行效果。很多情况下,软中断和"信号"有些类似,同时,软中断又是和硬中断相对应的,"硬中断是外部设备对CPU的中断","软中断通常是硬中断服务程序对内核的中断","信号则是由内核(或其他进程)对某个进程的中断"(《Linux内核源代码情景分析》第三章)。
tasklet:tasklet是由软中断引出的, 内核定义了两个软中断掩码HI_SOFTIRQ和TASKLET_SOFTIRQ(两者优先级不同), 这两个掩码对应的软中断处理函数作为入口, 进入tasklet处理过程.
工作队列:定义一个work结构(包含了处理函数), 然后在中断处理过程中调用schedule_work函数, work便被添加到workqueue中, 等待处理.工作队列有着自己的处理线程, 这些work被推迟到这些线程中去处理.内核默认启动了一个工作队列, 对应一组工作线程events/n(n代表处理器编号, 这样的线程有n个). 驱动程序可以直接向这个工作队列添加任务. 某些驱动程序还可能会创建并使用属于自己的工作队列.
那么,让我们看看目前最主要引起中断的原因:IO中断,时钟中断,系统调用。所谓的中断处理程序就是在响应一个特定中断的时候,内核会执行一个函数,该函数就是中断处理程序。下图为中断处理程序的处理流程:
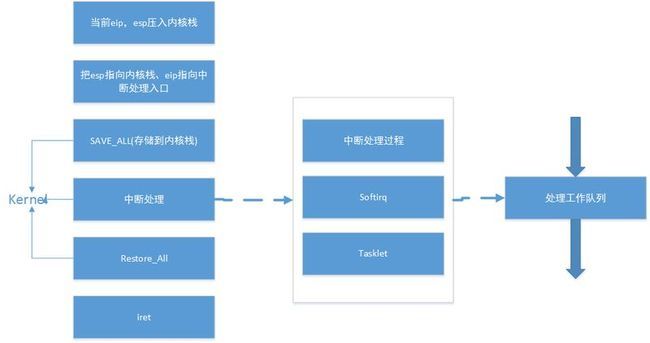
从上图可以看出,每个中断处理都要经历保存、处理与恢复过程,我们可以总结出以下步骤:1.保存现场。2.执行具体的中断处理程序。3.从中断处理返回。4.恢复现场。
那么为什么会有软中断,tasklet,和工作队列呢??由于中断处理程序一般都是在中断请求关闭的条件下执行的,以避免嵌套而使中断控制复杂化。但是,中断是一个随机事件,它随时会到来,如果关中断的时间太长,CPU就不能及时响应其他的中断请求,从而造成中断的丢失。因此,Linux内核的目标就是尽可能快的处理完中断请求,尽其所能把更多的处理向后推迟。因此,内核把中断处理分为两部分:上半部(tophalf)和下半部(bottomhalf),上半部(就是中断处理程序)内核立即执行,而下半部(就是一些内核函数)留着稍后处理。对应于上下半部的处理,才有了以上这些概念。
那么,什么情况下使用工作队列,什么情况下使用tasklet。如果推后执行的任务需要睡眠,那么就选择工作队列。如果推后执行的任务不需要睡眠,那么就选择tasklet。另外,如果需要用一个可以重新调度的实体来执行你的下半部处理,也应该使用工作队列。它是唯一能在进程上下文运行的下半部实现的机制,也只有它才可以睡眠。这意味着在需要获得大量的内存时、在需要获取信号量时,在需要执行阻塞式的I/O操作时,它都会非常有用。如果不需要用一个内核线程来推后执行工作,那么就考虑使用tasklet。
参数资料
【1】http://www.longene.org/forum/viewtopic.php?f=21&t=4646
【2】http://wenku.baidu.com/view/79fe36c10c22590103029d04
【3】 深入理解Linux内核
本文综述部分系个人理解,如有错误请指正,转载请声明