Python | 用相关系数进行Kmeans聚类,利用利润率、打折率、销售额、毛利润得到商品价格弹性标签,建立价格折扣力度模型
1、计算每一类的相关系数:
原数据

计算出超市商品类内部利润率、打折率、销售额、毛利润数据的相关系数。
- 1级24个商品分类标签
这里是计算1级24个商品分类table[‘居家日用’, ‘休闲食品’, ‘纺织用品’, ‘家居家装’, ‘水果/蔬菜’, ‘家用电器’, ‘美食’, ‘水产’, ‘营养保健’, ‘运动户外’, ‘日配/冷藏’, ‘烘焙’, ‘粮油副食’, ‘情趣用品’, ‘肉品’, ‘母婴’, ‘服装服饰’, ‘办公用品’, ‘宠物生活’, ‘日化用品’, ‘进口商品’, ‘医疗器械’, ‘个洗清洁’, ‘酒水饮料’]内利润率、打折率、销售额、毛利润数据的相关系数
for j in range(len(ID_list)):
dat=liushui[liushui['table']==ID_list[j]]
da['商品类'][j]=ID_list[j]
da['打折率&利润率'][j]=dat[['打折率','利润率','单品销售额','毛利润']].corr()['打折率']['利润率']
da['打折率&单品销售额'][j]=dat[['打折率','利润率','单品销售额','毛利润']].corr()['打折率']['单品销售额']
da['利润率&单品销售额'][j]=dat[['打折率','利润率','单品销售额','毛利润']].corr()['利润率']['单品销售额']
da['打折率&毛利润'][j]=dat[['打折率','利润率','单品销售额','毛利润']].corr()['打折率']['毛利润']
da['单品销售额&毛利润'][j]=dat[['打折率','利润率','单品销售额','毛利润']].corr()['毛利润']['单品销售额']
da['利润率&毛利润'][j]=dat[['打折率','利润率','单品销售额','毛利润']].corr()['利润率']['毛利润']
da
得到这个相关系数表:

2. 用相关系数进行Kmeans聚类
基于每类产品的相关系数值,使用无监督学习的kmeans聚类方法聚类:
x1=da1[['打折率&利润率','打折率&单品销售额','利润率&单品销售额','打折率&毛利润','单品销售额&毛利润','利润率&毛利润']].values#基于相关系数的聚类
x1
from sklearn.cluster import KMeans#导入聚类模型
model1=KMeans(n_clusters=2).fit(x1)#聚成3类传入自变量
model1.labels_.size
da1['label']=model1.labels_
成功得到聚类标签,然后是将kmeans聚类结果进行可视化:
plt.figure(dpi=200)
g={0:'单一弹性商品',1:'富有弹性商品',2:'缺乏弹性商品'}
for i in range(3):
plt.scatter(da[da['label']==i]['利润率&单品销售额'],da[da['label']==i]['打折率&单品销售额'],label=g[i])#商品各大类相关系数的聚类效果
# plt.scatter(da['利润率&单品销售额'],da['打折率&单品销售额'])#商品各大类相关系数的聚类效果
plt.legend(frameon=False,fontsize=14)
plt.xlabel('单品销售额与利润率的相关系数')
plt.ylabel('单品销售额与打折率的相关系数')
将kmeans聚类标签进行进行可视化得到下图:
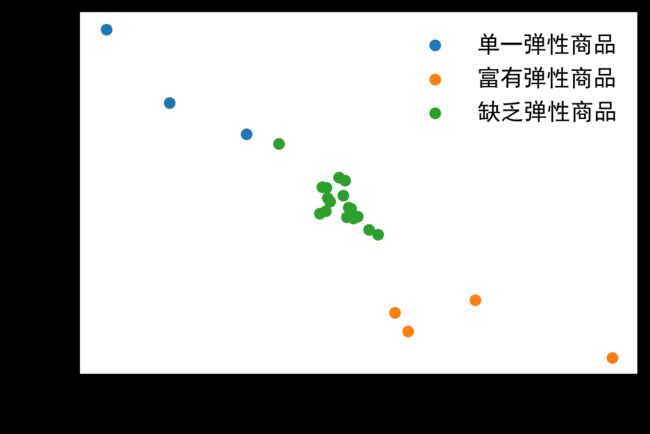
该图x轴为利润率和单品销售额的相关系数,y轴打折率和单品销售额的相关系数,,橙色商品类单品销售额与利润率的相关系数很高,单品销售额与打折率的相关系数很低,可见存在一定的薄利多销现象,可以将其称为富有弹性的商品类。中间绿色一类,单品销售额和利润率、打折率的相关系数都接近于零,可以判断绿色类商品为缺乏弹性商品。
聚类标签到实际商品弹性标签:

学了一点经济学,营养保健类确实是富有弹性的商品。
根据该聚类结果的商品需求弹性标签,成功将24个大商品类划分为如粮油副食类的缺乏弹性商品、如家具家装类的单一弹性商品、如营养保健类的富有弹性商品。
3.细化分类,得到更具体的价格弹性标签
*2级85个商品分类标签:
f=['打折率&利润率','打折率&单品销售额','利润率&单品销售额','打折率&毛利润','单品销售额&毛利润','利润率&毛利润']
o=0
plt.figure(figsize=(17,17),dpi=200)
for j in range(len(f)):
for k in range(len(f)):
if k>j:
o=o+1
plt.subplot(4,4,o)
for i in range(4):
plt.scatter(da1[da1['label']==i][f[j]],da1[da1['label']==i][f[k]])#商品各大类相关系数的聚类效果
plt.xlabel(f[j])
plt.ylabel(f[k])
if o>11:
break
- 聚3类效果图
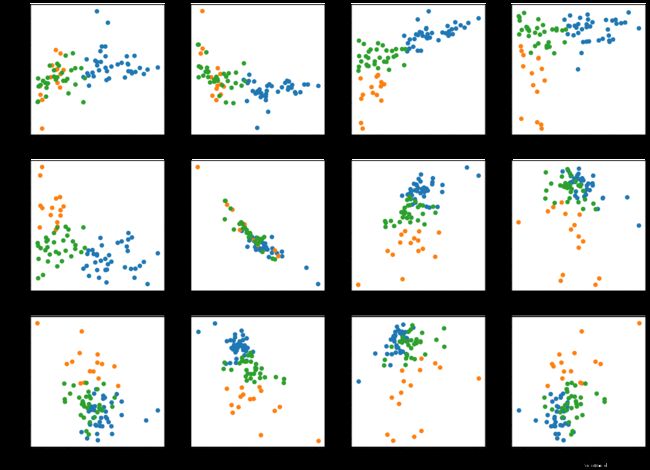
聚类效果出奇的好,但分类效果不太好: - 还是聚2类吧

低价格弹性商品:
[‘水’, ‘蔬菜’, ‘蛋品’, ‘厨房清洁品’, ‘硬糖’, ‘果冻’, ‘茶饮料’, ‘国产水果’, ‘进口水果’, ‘方便面’, ‘米’, ‘卫生护理’, ‘口腔护理’, ‘巧克力’, ‘冲调粉’, ‘挂面/米粉’, ‘调味品’, ‘膨化食品’, ‘坚果’, ‘茶叶’, ‘汤圆’, ‘纸品湿巾’, ‘面部保养品’, ‘固体咖啡’, ‘冲饮粉’, ‘口香糖’, ‘低温奶制品’, ‘冰品类’, ‘米面制品’, ‘卫浴清洁剂’, ‘沐浴’, ‘冷藏面点’, ‘洗发护发’, ‘禽类’, ‘饼干’, ‘食用油’, ‘常温奶制品’, ‘进口个人洗护’, ‘水饺/馄饨’, ‘成人奶粉’, ‘猪肉’, ‘进口乳制品’, ‘糕点’, ‘中式糕点’, ‘碳酸饮料’]
高价格弹性商品:
[‘南北干货’, ‘进口酒水饮料’, ‘进口休闲食品’, ‘罐头’, ‘衣物清洁/护理剂’, ‘婴儿用品’, ‘进口粮油副食’, ‘方便食品’, ‘肉干’, ‘面粉’, ‘牙膏’, ‘调鲜品’, ‘干奶乳制品’, ‘西式糕点’, ‘咖啡伴侣’, ‘蜜饯’, ‘冰鲜类’, ‘果味饮料/果汁’, ‘西式熟食’, ‘一次性用品’, ‘机能饮料’, ‘盐’, ‘主食面包’, ‘杂粮类’, ‘猫用品’, ‘狗用品’, ‘酱油’, ‘软糖’, ‘低温熟食’, ‘冷冻副食’, ‘牛肉’, ‘洁肤’, ‘火腿肠’, ‘啤酒’, ‘冰冻水产’, ‘豆制品’, ‘葡萄酒’, ‘家居清洁品’, ‘白酒’, ‘酱菜/榨菜’]
效果见仁见智,我觉得还不错,高价格弹性的商品进口明显多一些,毕竟数据分析只是一种参考。
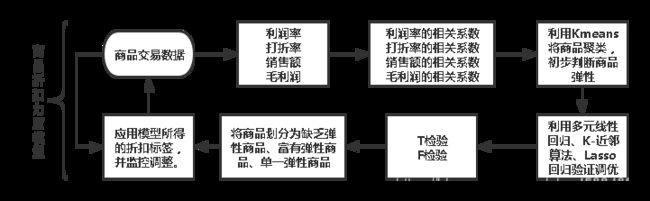
3. 价格折扣力度模型
这个是我设计的一个价格折扣力度模型比较重要的一部分,价格折扣力度模型具体如下。
- 模型学习笔记系列3_END