深度学习/联邦学习笔记(五)多层全连接神经网络实现MNIST手写数字分类+Pytorch代码
深度学习/联邦学习笔记(五)
多层全连接神经网络实现MNIST手写数字分类+Pytorch代码
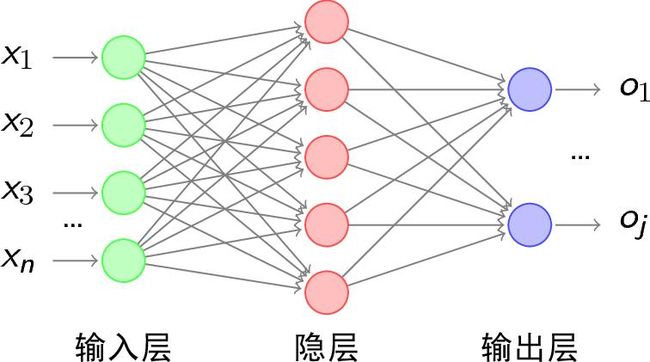
神经网络是一个有神经元构成的无环图,神经网络一般以层来组织,最常见的是全连接神经网络,其中两个相邻层中每一个层的所有神经元和另外一个层的所有神经元相连,每个层内部的神经元不相连,如下图(隐藏层可以有多层):
先在一个net.py文件中,定义一些相关的神经网络和激活函数等等
import torch
from torch import nn, le
from torch.autograd import Variable
#简单的三层全连接神经网络
class simpleNet(nn.Module):
# 对于这个三层网络,需要传入的参数有:输入的维度,第一层网络的神经元个数,第二次网络神经元的个数、第三层网络(输出层)神经元的个数
def __init__(self,in_dim,n_hidden_1,n_hidden_2,out_dim):
super(simpleNet, self).__init__()
self.layer1 = nn.Linear(in_dim,n_hidden_1)
self.layer2 = nn.Linear(n_hidden_1,n_hidden_2)
self.layer3 = nn.Linear(n_hidden_2,out_dim)
def forward(self,x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
#添加激活函数,增加网络的非线性
class Activation_Net(nn.Module):
def __init__(self,in_dim,n_hidden_1,n_hidden_2,out_dim):
#只需要在每层网络的输出部分添加激活函数即可,此处用的是ReLU激活函数
super(Activation_Net, self).__init__()
self.layer1 = nn.Sequential( #nn.Sequential()是将网络的层组合在一起,如下面将nn.Linear()和nn.ReLU()组合到一起作为self.layer1
nn.Linear(in_dim,n_hidden_1),nn.ReLU(True))
self.layer2 = nn.Sequential(
nn.Linear(n_hidden_1,n_hidden_2),nn.ReLU(True) )
self.layer3 = nn.Sequential(nn.Linear(n_hidden_2,out_dim) ) #最后一层输出层不能添加激活函数
def forward(self,x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
#最后添加一个加快收敛的方法——批标准化
class Batch_Net (nn.Module) :
def init__ (self,in_dim,n_hidden_1,n_hidden_2,out_dim):
super(Batch_Net, self).__init__()
#同样使用nn.Sequential()将 nn .BatchNormld()组合到网络层中,注意批标准化一般放在全连接层的后面、非线性层(激活函数)的前面
self.layerl = nn.Sequential(
nn.Linear(in_dim,n_hidden_1),
nn .BatchNormld(n_hidden_1), nn.ReLU(True))
self.layer2 = nn. Sequential(
nn.Linear(n_hidden_1,n_hidden_2),
nn. BatchNormld(n_hidden_2), nn. ReLU(True))
self.layer3 = nn.Sequential (nn.Linear (n_hidden_2,out_dim))
def forward(self, x) :
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3 (x)
return x
在另一个py文件中,训练网络,代码如下:
import torch
from torch import nn,optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
import net
#定义一些超参数
batch_size = 64
learning_rate = 1e-2
num_epoches = 20
#数据预处理,即将数据标准化,此处用的是torchvision.transforms
data_tf = transforms.Compose( #transforms.Compose将各种预处理操作组合到一起
[transforms.ToTensor(), #将图片转换成pytorch中处理的对象tensor
transforms.Normalize([0.5],[0.5])] #该函数需要传入两个参数,第一个是均值,第二个是方差,其处理是减均值,再除以方差;即减去0.5再除以0.5,这样能把图片转化到-1到1间
)
#下载训练集MNIST手写数字训练集
train_dataset = datasets.MNIST( #通过pytorch内置函数torchvision.datasets.MNIST导入数据集
root='./data', train=True, transform = data_tf, download = True)
test_dataset = datasets.MNIST (root='./data', train = False, transform = data_tf,download = True)
#使用torch.utils.data.DataLoader建立数据迭代器,传入数据集和batch_size,通过shuffle=True来表示每次迭代数据时是否将数据打乱
train_loader = DataLoader (train_dataset, batch_size = batch_size, shuffle = True)
test_loader = DataLoader (test_dataset, batch_size = batch_size, shuffle = False)
#导入网络,定义损失函数和优化方法
model = net.simpleNet(28 * 28, 300, 100, 10) #net.simpleNet是简单的三层网络,输入维度是28*28,两个隐藏层是300和100,最后输出结果必须是10,有0-9个分类结果
if torch. cuda.is_available():
model = model.cuda ()
criterion = nn. CrossEntropyLoss() #使用损失函数交叉熵来定义损失函数
optimizer = optim.SGD (model.parameters(), lr=learning_rate) #用随机梯度下降来优化损失函数
#开始训练模型
model.eval()
eval_loss = 0
eval_acc = 0
for data in test_loader:
img, label = data
img = img.view(img.size(0), -1)
if torch. cuda.is_available() :
img = Variable(img, volatile = True) . cuda()
label = Variable(label, volatile = True) .cuda()
else:
img = Variable(img, volatile = True)
label = Variable(label, volatile = True)
out = model(img)
loss = criterion(out, label)
eval_loss += loss.item() * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(
eval_loss / (len(test_dataset)),
eval_acc / (len(test_dataset))))运行结果如下:
C:\Users\Administrator\anaconda3\python.exe "D:/paper reading/code/learningcode/trainnet.py"
D:/paper reading/code/learningcode/trainnet.py:52: UserWarning: volatile was removed and now has no effect. Use `with torch.no_grad():` instead.
img = Variable(img, volatile = True)
D:/paper reading/code/learningcode/trainnet.py:53: UserWarning: volatile was removed and now has no effect. Use `with torch.no_grad():` instead.
label = Variable(label, volatile = True)
Test Loss: 2.336183, Acc: 0.088200
Process finished with exit code 0