OpenAI:基于对比学习的预训练文本&代码表征技术
写在前面
大家好,我是刘聪NLP。
今天给大家带来一篇OpenAI的论文,基于对比学习预训练的文本和代码表征,全名《Text and Code Embeddings by Contrastive Pre-Training》。
其实,这篇论文在春节放假期间我就看了,模型是套用GPT-3的模型,只是采用对比学习的方法,又继续预训练了一波;但是里面有个结论假设还挺有意思的,就是「搜索任务和句子相似任务,在句向量表征中是冲突的。」
这与我在真实情况下得到的结论差不多,后面会具体分析。
https://arxiv.org/pdf/2201.10005.pdf
介绍
虽然句子表征和检索任务都为了获取更好地向量表征,但是句子表征往往在相似度任务上进行评测,而检索任务往往是在检索数据集进行评测。该论文旨在训练一个「文本向量表征」模型,可以在两者均较好的模型。
句向量表征技术目前已经通过对比学习获取了很好的效果。对比学习的宗旨就是拉近相似数据,推开不相似数据,有效地学习数据表征。之前一些论文在构造正样本时大多采用数据增强的技术,而该论文在文本向量表征时,采用互联网上的数据进行训练,将「相邻的文本片段」作为对比学习目标的「正例对」。
模型
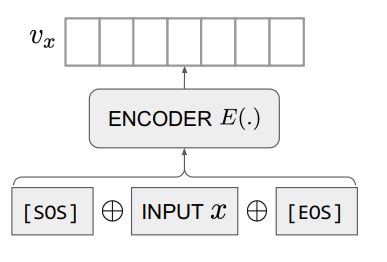
模型结构采用由多层Transformer-Decoder组成的GPT结构。如下图所示,针对一段文本,将其前后插入特殊占位符[SOS]和[EOS],输入到模型中,将模型输出[EOS]向量作为该文本的文本表征向量。
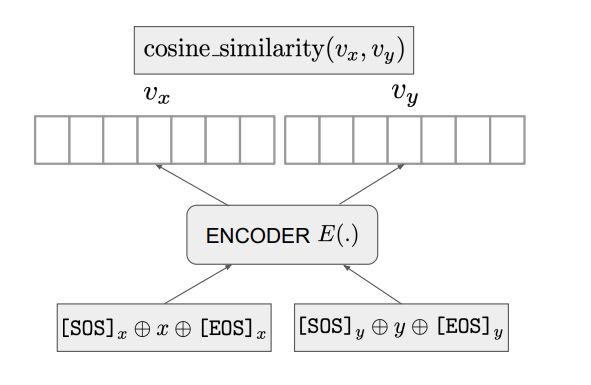
在训练时,如下图所示,针对两段文本和,将其分别输入到模型中,获取对应的文本向量和对应的文本向量,并计算两个向量的余弦相似度。
其中,表示字符链接。发现,当采用不同分隔符时,可以获取更好地训练结果,其中,“[”和“]”作为的前后分隔符,“{”和“}”作为的前后分隔符。
损失函数采用InfoNCE loss,将一个批次内的正样本拉近,负样本推开,批次内对角线上的样本对为正例。
其中,为可训练的温度参数。伪代码如下:
labels = np.arange(M)
l_r = cross_entropy(logits, labels, axis=0)
l_c = cross_entropy(logits, labels, axis=1)
loss = (l_r + l_c) / 2
对于文本向量表征模型采用GPT-3系列模型参数进行初始化,继续进行对比学习训练。并且采用了超大的批次大小,如下表所示。

结果
针对文本分类任务,无监督和有监督的效果如下表所示,在AVG上,从模型S到XL基本上均取得了sota,但在各个任务上,还是存在波动。

针对文本相似度任务,无监督和有监督的效果如下表所示,无论是大模型还是小模型,效果均不理想,相较于SimCSE低了很多。 针对文本检索任务,无监督和有监督的效果如下表所示,取得了较好的效果。相较于ColBert等交互或半交互式向量表征,在计算时间上也存在优势。 对于代码检索任务,该论文还进行了代码-文本的对比学习模型,效果如下表所示,在各种语言代码上,均取得了非常好的效果。并且,仅用文本训练的模型,在python语言上的代码检索任务也取得了很好的效果。
分析
-
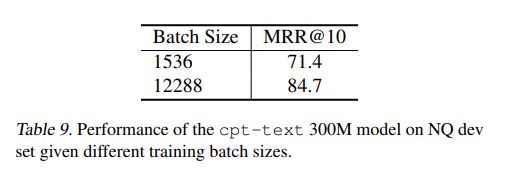
Batch Size对模型的影响
这个已经是老生常谈的问题了,由于对比学习的机制,当Batch Size越大时,学习难度就越高,使得模型可以学得更好。并且实验证明,当Batch Size为1536时,在NQ数据上MRR@10可以仅有71.4,而Batch Size为12288时,可以达到84.7。
-
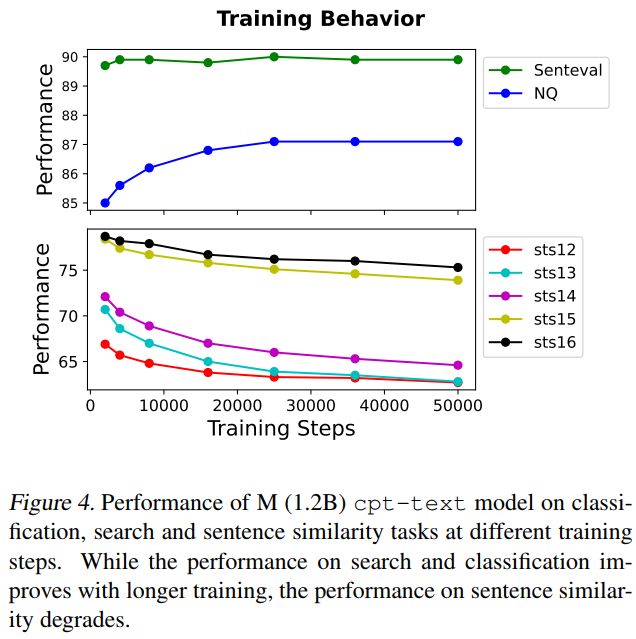
训练步数对模型效果得影响
这个也是一个老生常谈的问题,一般认为,训练越久,效果越好,后面会趋于稳定。该论文实验结果显示,训练越久,在检索和分类任务上,效果越好;而对于句子相似度任务来说,恰巧相反。
-
为什么检索任务与相似度任务会存在冲突?
个人观点,从本质出发,检索任务是判断两段内容是否有关联,相似度任务是判断两端内容是否相似,往往有关联得内容是不相似,这就导致两个任务得目标是有差别的。从该论文预训练任务出发,采用上下文数据,作为对比学习正例,上下文数据往往是关联的,而不是相似的,导致模型越训练,在检索任务上就越好,而在相似度任务上恰巧相反。从数据出发,对于检索任务一般输入为短句和长句,对于相似任务一般是短句和短句,因此在模型获取信息上有所区别,并在该论文的预训练任务上,数据分布更趋近于检索任务。
-
个人真实案例
在工业上,QQ匹配就是相似度任务、QD匹配就是检索任务。本人曾经在大量阅读理解数据上训练QD向量表征模型,可以在检索任务上达到比较的效果。当迁移到FAQ任务的QQ匹配时,效果很差,并且就算将Q+A作为D,采用QD模型表征的效果也不是很理想,不如直接训练的QQ匹配模型。个人感觉还是由于数据分布,以及模型学到内容存在差异导致。
总结
总感觉OpenAI为了证明什么,非要采用GPT结构,感觉采用RoBerta-www模型作为初始化模型进行预训练,效果会比同等参数的GPT效果要好说不定会有意想不到收获。(没有实验,随便说说)
整理不易,请多多点赞,关注,有问题的朋友也欢迎加我微信「logCong」、公众号「NLP工作站」、知乎「刘聪NLP」私聊,交个朋友吧,一起学习,一起进步。
我们的口号是“生命不止,学习不停”。