Scanpy(二)可视化函数
目录
- embedding的散点图
-
- 可视化基因表达量与其他变量
- 用已知marker基因识别clusters
-
- dotplot
- violin plot
- stacked-violin plot
- matrixplot
- 将图放到子图中
- Heatmaps
- Tracksplot
- 标记基因的可视化
-
- 用dotplot可视化marker基因
- 用matrixplot可视化marker基因
- 用tracksplot可视化marker基因
- 使用violin plot比较标记基因
- 树状图选项Dendrogram
- 可视化相关性
本篇内容为scanpy的可视化方法,可以分为三部分:
- embedding的散点图;
- 用已知marker genes的聚类识别(Identification of clusters);
- 可视化基因的差异表达;
我们使用10x的PBMC数据集(包含68k个细胞)。Scanpy在其发行版中包含了这个数据集的缩减版,该数据集只包含700个细胞和765个高变基因。此数据集已经过预处理和UMAP计算。
在本篇内容里,我们使用到以下标记基因(来自于已知的文献结论,比如B-cell的标记基因为CD79A, MS4A1):
- B-cell: CD79A, MS4A1
- Plasma: IGJ (JCHAIN)
- T-cell: CD3D
- NK: GNLY, NKG7
- Myeloid: CST3, LYZ
- Monocytes: FCGR3A
- Dendritic: FCER1A
embedding的散点图
基于scanpy,tSNE、UMAP和其他几个embedding的散点图可以从文档轻松找到。比如可以看这里的选项列表:sc.pl.tsne,sc.pl.umap。
我们先进行初始化设置:
import scanpy as sc
import pandas as pd
from matplotlib.pyplot import rc_context
sc.set_figure_params(dpi=100, color_map = 'viridis_r')
sc.settings.verbosity = 1
sc.logging.print_header()
"""
scanpy==1.6.0 anndata==0.8.0 numpy==1.21.6 scipy==1.8.0 pandas==1.4.2 scikit-learn==1.0.2 statsmodels==0.11.0 python-igraph==0.8.0
"""
加载pbmc缩减版数据集:
pbmc = sc.datasets.pbmc68k_reduced()
# 检查pbmc内容
pbmc
"""
AnnData object with n_obs × n_vars = 700 × 765
obs: 'bulk_labels', 'n_genes', 'percent_mito', 'n_counts', 'S_score', 'G2M_score', 'phase', 'louvain'
var: 'n_counts', 'means', 'dispersions', 'dispersions_norm', 'highly_variable'
uns: 'bulk_labels_colors', 'louvain', 'louvain_colors', 'neighbors', 'pca', 'rank_genes_groups'
obsm: 'X_pca', 'X_umap'
varm: 'PCs'
obsp: 'distances', 'connectivities'
"""
这里补充关于adata的obsm,varm和obsp的内容:
- obsm:对于观测的多维注释(即对于矩阵的行的多维注释),它是可变的ndarray,长度为n_obs,维度为2至多维。这里的m指的就是multi-dim多个维度的,obs_m对应于obs,但obs的每个成员都是一维的观测注释,obs_m的每个成员(X_pac和X_umap)都是多维的观测注释。
- varm:用于描述特征的,与obsm相对应。
- obsp(obs pair):针对观测的配对的注释(存储为稀疏矩阵),稀疏矩阵两维都是n_obs,obsp通常用于描述观测与观测之间的距离和连通性。比如:
pbmc.obsp['distances']
"""
<700x700 sparse matrix of type ''
with 6300 stored elements in Compressed Sparse Row format>
"""
行和列索引 距离
(0, 9) 8.365935325622559
(0, 54) 8.560888290405273
(0, 94) 7.486799716949463
......
(699, 695) 3.6524178981781006
可视化基因表达量与其他变量
对于散点图,参数color是可视化的一个值,可以是Adata的任何基因或者obs里的任何对象,注意obs是存储注释信息的dataframe。
可视化基因CD79A在所有细胞中的表达量分布,由于pbmc这个adata已经有X_umap,我们可以用sc.pl.umap实现UMAP下的基因表达分布:
# rc_context用于指定figure大小
with rc_context({'figure.figsize': (4, 4)}):
sc.pl.umap(pbmc, color='CD79A')
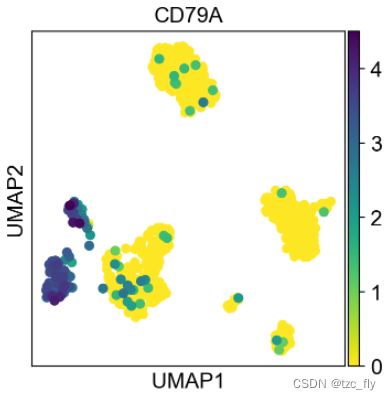
可以给多个值。在下面的示例中,我们将绘制6个基因:“CD79A”、“MS4A1”、“IGJ”、“CD3D”、“FCER1A”和“FCGR3A”,以了解这些marker基因的表达。
此外,我们还将绘制另外两个值:
- 一个是每个细胞的UMI计数数
n_counts(UMI检测到的基因越多,数据越复杂); - 一个是一个分类值categorical value
bulk_labels(来自10x的细胞原始标签)。
使用参数ncols控制每行的可视化案例数。可以使用vmax调整绘制颜色的最大值(同样vmin可以用于最小值)。在本例中,我们使用vmax='p99',这意味着使用99%作为最大值。如果要分别为多个可视化案例设置vmax,则vamx可以是一个数字或一组数字。
此外,我们还使用frameon=False移除可视化图的边框,并用s=50设置点大小。
with rc_context({'figure.figsize': (3, 3)}):
sc.pl.umap(pbmc, color=['CD79A', 'MS4A1', 'IGJ', 'CD3D', 'FCER1A', 'FCGR3A', 'n_counts', 'bulk_labels'], s=50, frameon=False, ncols=4, vmax='p99')

在图中,我们可以看到标记基因的细胞群与原始细胞标签的大概一致性。
散点图函数还有很多选项,可以微调图像。例如,我们可以如下所示查看clustering:
# 用leiden聚类计算, 结果存储到'clusters'中
sc.tl.leiden(pbmc, key_added='clusters', resolution=0.5)
pbmc
"""
AnnData object with n_obs × n_vars = 700 × 765
obs: 'bulk_labels', 'n_genes', 'percent_mito', 'n_counts', 'S_score', 'G2M_score', 'phase', 'louvain', 'clusters'
var: 'n_counts', 'means', 'dispersions', 'dispersions_norm', 'highly_variable'
uns: 'bulk_labels_colors', 'louvain', 'louvain_colors', 'neighbors', 'pca', 'rank_genes_groups', 'leiden'
obsm: 'X_pca', 'X_umap'
varm: 'PCs'
obsp: 'distances', 'connectivities'
"""
注意到,obs中多了一个注释"clusters",下一步用"clusters"作为可视化的绘制值:
with rc_context({'figure.figsize': (5, 5)}):
sc.pl.umap(pbmc, color='clusters', add_outline=True, legend_loc='on data',
legend_fontsize=12, legend_fontoutline=2,frameon=False,
title='clustering of cells', palette='Set1')

用已知marker基因识别clusters
通常,clusters需要使用已知的标记基因进行标记。使用散点图,我们可以看到一个基因在所有细胞中的表达,并可能将其与一个簇相关联。在这里,我们将展示使用点图dotplots、小提琴图violin plots、热图heatmaps和我们称之为“tracksplot”的图将标记基因与clusters关联。所有这些可视化都展示了相同的信息,最佳结果的选择由研究人员决定。
首先,我们为标记基因建立了一个字典,因为这将允许scanpy自动标记基因组:
marker_genes_dict = {
'B-cell': ['CD79A', 'MS4A1'],
'Dendritic': ['FCER1A', 'CST3'],
'Monocytes': ['FCGR3A'],
'NK': ['GNLY', 'NKG7'],
'Other': ['IGLL1'],
'Plasma': ['IGJ'],
'T-cell': ['CD3D'],
}
dotplot
检查每个簇中这些基因表达的快速方法是使用dotplot。这种图概括了两种类型的信息:
- 颜色表示一个基因,在每个类别(每个簇)内的平均表达;
- 点大小表示表达基因的细胞类别中的细胞比例。
此外,将树状图添加到图中也很有用(点图右侧的树状结构),可以将类似的簇聚集在一起。scanpy使用簇之间的PCA分量的相关性实现层次聚类。
sc.pl.dotplot(pbmc, marker_genes_dict, 'clusters', dendrogram=True)

使用该图,我们可以看到簇4对应于B-cell,簇2对应于T-cell等。该信息可用于手动注释细胞,如下所示:
# 手动创建字典用于映射 簇 与 标签
cluster2annotation = {
'0': 'Monocytes',
'1': 'Dendritic',
'2': 'T-cell',
'3': 'NK',
'4': 'B-cell',
'5': 'Dendritic',
'6': 'Plasma',
'7': 'Other',
'8': 'Dendritic',
}
# 加入一个新的观测注释 `cell type` (使用pandas的map函数将clusters中的簇编号映射为cell type的标签)
pbmc.obs['cell type'] = pbmc.obs['clusters'].map(cluster2annotation).astype('category')
pbmc.obs['clusters']
"""
index
AAAGCCTGGCTAAC-1 0
..
TTGAGGTGGAGAGC-8 1
Name: clusters, Length: 700, dtype: category
Categories (9, object): ['0', '1', '2', '3', ..., '5', '6', '7', '8']
"""
pbmc.obs['cell type']
"""
index
AAAGCCTGGCTAAC-1 Monocytes
...
TTGAGGTGGAGAGC-8 Dendritic
Name: cell type, Length: 700, dtype: category
Categories (7, object): ['B-cell', 'Dendritic', 'Monocytes', 'NK', 'Other', 'Plasma', 'T-cell']
"""
我们用cell type去可视化点图:
sc.pl.dotplot(pbmc, marker_genes_dict, 'cell type', dendrogram=True)

将标签可视化到散点图中,用cell type作为绘制的参数:
sc.pl.umap(pbmc, color='cell type', legend_loc='on data',
frameon=False, legend_fontsize=10, legend_fontoutline=2)

violin plot
探索marker基因的另一种方式是violin plot。我们可以看到CD79A在簇4和簇6中的表达,以及MS4A1在簇4中的表达。(注意一个事实:CD79A和MS4A1是B-cell的标记基因)与dotplot相比,violin plot为我们提供了基因表达值在细胞中的分布概念。
使用clusters作为group的索引:
with rc_context({'figure.figsize': (4.5, 3)}):
sc.pl.violin(pbmc, ['CD79A', 'MS4A1'], groupby='clusters' )

小提琴图也可用于绘制存储在obs中的任何值。例如,这里使用小提琴图来比较不同簇之间的基因数量n_genes和线粒体基因百分比percent_mito。
with rc_context({'figure.figsize': (4.5, 3)}):
# stripplot=False用于删除internal dots, inner='box'用于在小提琴内部加方框图
sc.pl.violin(pbmc, ['n_genes', 'percent_mito'], groupby='clusters', stripplot=False, inner='box')

stacked-violin plot
为了同时查看所有marker基因的小提琴图,我们使用sc.pl.stacked_violin,如前所述,添加了一个树状图(dendrogram)来对相似的簇进行分组。
ax = sc.pl.stacked_violin(pbmc, marker_genes_dict, groupby='clusters', swap_axes=False, dendrogram=True)

matrixplot
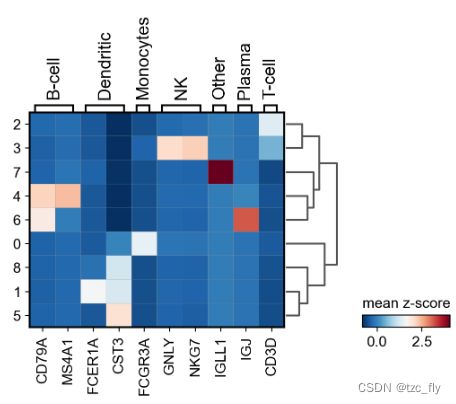
可视化基因表达的一种简单方法是使用matrixplot,这是按类别(簇)分组的每个基因的平均表达值的热图。这种图基本上显示与点图中的颜色相同的信息。
在这里,将基因的表达从0缩放到1,这是最大的平均表达,0是最小的。
sc.pl.matrixplot(pbmc, marker_genes_dict, 'clusters', dendrogram=True, cmap='Blues', standard_scale='var', colorbar_title='column scaled\nexpression')

其他有用的选项是用sc.pp.scale对表达标准化,这里,我们将scale后的信息保存在adata的隐藏dataframelayers中:
pbmc.layers['scaled'] = sc.pp.scale(pbmc, copy=True).X
再用matrixplot可视化,并使用其他cmap:
sc.pl.matrixplot(pbmc, marker_genes_dict, 'clusters', dendrogram=True,
colorbar_title='mean z-score', layer='scaled', cmap='RdBu_r')
将图放到子图中
可以使用plt.subplots的返回对象ax将图变成子图:
import matplotlib.pyplot as plt
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(20,4), gridspec_kw={'wspace':0.9})
ax1_dict = sc.pl.dotplot(pbmc, marker_genes_dict, groupby='bulk_labels', ax=ax1, show=False)
ax2_dict = sc.pl.stacked_violin(pbmc, marker_genes_dict, groupby='bulk_labels', ax=ax2, show=False)
ax3_dict = sc.pl.matrixplot(pbmc, marker_genes_dict, groupby='bulk_labels', ax=ax3, show=False, cmap='viridis')

Heatmaps
热图不像前面的图会折叠了每个细胞,热图中,每个细胞都显示在每一行上。
ax = sc.pl.heatmap(pbmc, marker_genes_dict, groupby='clusters', cmap='viridis', dendrogram=True)

热图也可以绘制在scale过的数据上。在下图中,与前面的matrixplot相似(注意参数layer='scaled)。
ax = sc.pl.heatmap(pbmc, marker_genes_dict, groupby='clusters', layer='scaled',
vmin=-2, vmax=2, cmap='RdBu_r', dendrogram=True, swap_axes=True, figsize=(11,4))

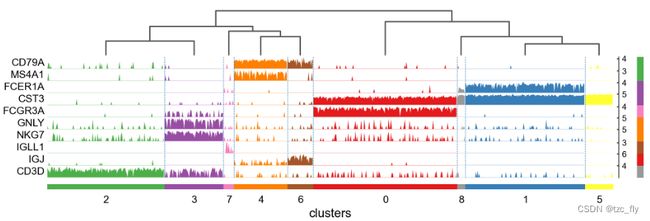
Tracksplot
Tracksplot显示的信息与热图相同,但基因表达由高度表示,而不是色阶。
ax = sc.pl.tracksplot(pbmc, marker_genes_dict, groupby='clusters', dendrogram=True)
标记基因的可视化
我们可以识别在簇中差异表达的基因,而不是像前面那样通过已知的标记基因来表示簇。
我们用sc.tl.rank_genes_groups识别差异表达的基因,此函数将获取每组细胞,并将每组中每个基因的分布与不在该组中的所有其他细胞中的分布进行比较。
sc.tl.rank_genes_groups(pbmc, groupby='clusters', method='wilcoxon')
在这里,我们将使用10x给出的原始细胞标签来验证这些细胞类型的标记基因。
用dotplot可视化marker基因
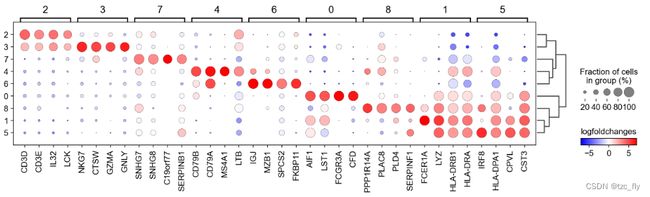
dotplot可以得到大致的差异基因表达总览。为了让可视化结果更紧凑,我们仅对每类细胞的差异表达得分前4的基因可视化(n_genes=4)。
sc.pl.rank_genes_groups_dotplot(pbmc, n_genes=4)

为了获得更好的表示,我们可以可视化取log(values_to_plot='logfoldchanges'),而不是原始的基因表达图。此外,我们希望关注差异得分取log后>=3的基因(min_logfoldchange=3)。
由于log是一个发散比例,我们还要调整可视化的最小值和最大值。注意,在下面的图中,很难区分T-cell。
sc.pl.rank_genes_groups_dotplot(pbmc, n_genes=4, values_to_plot='logfoldchanges', min_logfoldchange=3, vmax=7, vmin=-7, cmap='bwr')
下一步,我们集中关注不好分辨的两个组(簇1和5),在这里,我们增加参数groups=['1', '5'],并且设置更大范围的基因,再取对数。
sc.pl.rank_genes_groups_dotplot(pbmc, n_genes=30, values_to_plot='logfoldchanges',
min_logfoldchange=4, vmax=7, vmin=-7, cmap='bwr',
groups=['1', '5'])
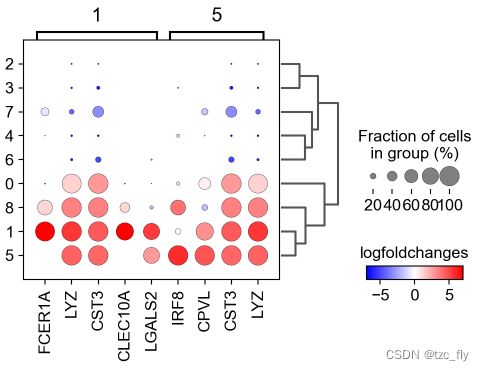
用matrixplot可视化marker基因
对于下图,我们使用之前计算的scale数据(存储在layers下)可视化。
sc.pl.rank_genes_groups_matrixplot(pbmc, n_genes=3, use_raw=False, cmap='bwr', layer='scaled')

用tracksplot可视化marker基因
每个簇都选出差异得分前3的基因,下图右侧即为每个簇的前3高差异表达基因。
sc.pl.rank_genes_groups_tracksplot(pbmc, n_genes=3)

使用violin plot比较标记基因
在scanpy中,使用split violin plots同时对所有簇比较标记基因非常容易。我们对每个比较都展示前20个高差异得分的基因:
with rc_context({'figure.figsize': (9, 1.5)}):
sc.pl.rank_genes_groups_violin(pbmc, n_genes=20, jitter=False)
每个簇都与其他簇比较,会可视化得到9个子图(0-rest直到8-rest),比如0-rest:
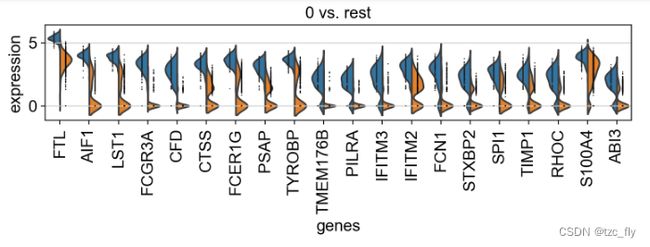
我们可以对比上面两张图(tracksplot和split violin 0-rest),发现前3个差异基因正好是FTL,AIF1,LST1。
树状图选项Dendrogram
大多数可视化可以使用树状图来排列类别。当然,树状图也可以单独绘制,如下所示:
# 计算簇间的层次结构, 此处使用obs的bulk_labels做标签
sc.tl.dendrogram(pbmc, 'bulk_labels')
ax = sc.pl.dendrogram(pbmc, 'bulk_labels')

可视化相关性
相关性的可视化可以与树状图一起,相关性可视化通常是绘制类别的相关性。
ax = sc.pl.correlation_matrix(pbmc, 'bulk_labels', figsize=(5,3.5))
