脑电EEG代码开源分享 【1.前置准备-任务态篇】
往期文章
希望了解更多的道友点这里
0. 分享【脑机接口 + 人工智能】的学习之路
1.1 . 脑电EEG代码开源分享 【1.前置准备-静息态篇】
1.2 . 脑电EEG代码开源分享 【1.前置准备-任务态篇】
2.1 . 脑电EEG代码开源分享 【2.预处理-静息态篇】
2.2 . 脑电EEG代码开源分享 【2.预处理-任务态篇】
3.1 . 脑电EEG代码开源分享 【3.可视化分析-静息态篇】
3.2 . 脑电EEG代码开源分享 【3.可视化分析-任务态篇】
4.1 . 脑电EEG代码开源分享 【4.特征提取-时域篇】
4.2 . 脑电EEG代码开源分享 【4.特征提取-频域篇】
4.3 . 脑电EEG代码开源分享 【4.特征提取-时频域篇】
4.4 . 脑电EEG代码开源分享 【4.特征提取-空域篇】
5 . 脑电EEG代码开源分享 【5.特征选择】
6.1 . 脑电EEG代码开源分享 【6.分类模型-机器学习篇】
6.2 . 脑电EEG代码开源分享 【6.分类模型-深度学习篇】
汇总. 专栏:脑电EEG代码开源分享【文档+代码+经验】
0 . 【深度学习】常用网络总结
脑电EEG代码开源分享 【1.前置准备-任务态篇】
- 往期文章
- 一、前言
- 二、前置准备 框架介绍
- 三、代码格式说明
- 三、脑电处理 代码
-
- 3.0 参数设置
- 3.1 数据导入
- 3.2 前置准备-主函数
- 3.3 前置准备-功能函数
- 3.4 前置准备-结果保存
- 四、前置准备 整体代码
- 总结
- To:新想法、鬼点子的道友:
一、前言
本文档旨在归纳BCI-EEG-matlab的数据处理代码,作为EEG数据处理的总结,方便快速搭建处理框架的Baseline,实现自动化、模块插拔化、快速化。本文以任务态(锁时刺激,如快速序列视觉呈现)为例,分享脑电EEG的分析处理方法。
脑电数据分析系列。分为以下6个模块:
1. 前置准备
2. 数据预处理
3. 数据可视化
4. 特征提取(特征候选集)
5. 特征选择(量化特征择优)
6. 分类模型
本文内容:【1.前置准备】
提示:以下为各功能代码详细介绍,若节约阅读时间,请下滑至文末的整合代码
二、前置准备 框架介绍
前置准备
前置准备的主要功能,分为以下4部分:
1. 降采样
2. 数据分段
3. 去暂态
4. 选择导联
前期准备的代码框图、流程如下所示:
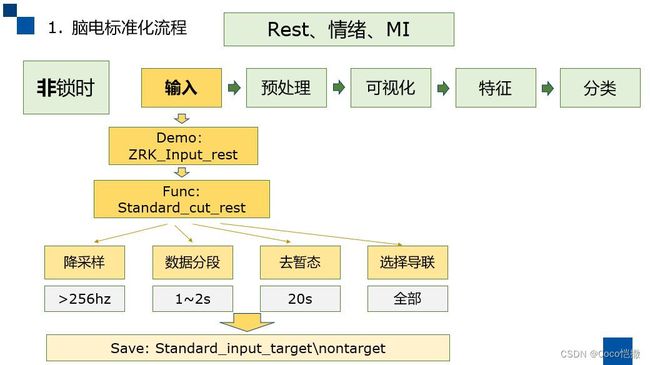
注:前置准备 理论上可以归类到 预处理阶段,本代码将两者分开基于以下考虑:
- 前置准备是数据处理的准备阶段,对脑电数据无损处理,不对原始数据进行变换、映射
- 为提升中间数据的可读性、可分析性,将原本9步骤的预处理,分为 4步【前置准备】 + 5步【预处理】
三、代码格式说明
本文任务态范例为:大脑对自身、非自身视觉刺激的认知模式分类
- **分段代码名称:**代码命名为Standard_cut_task/rest
- **输入格式:**任务态为Task_EEG的结构体,Task_EEG.data为原始数据(通道x总采样点数) ,Task_EEG. event_time为标签时间,Task_EEG. event_num为相应标签。
- **参数设置:**采样率\单试次时长\试次标签\试次位置\频域去除暂态时长\降采样(防止数据过大导致运行和内存消耗)
- **处理形式:**EEG数据汇总为cell(试次被试数),每个cell内为(通道数采样点数)。按照不同分类的类别放入不同cell,cell自身名称如下保存格式名称。例如任务态数据为{100,1}[16*512],其意为16通道数据采集,100试次,单试次为512点数据点。
- **保存格式:**单独保存个人的名称为Standard_input_target_sx(被试序号),总保存文件名称为Standard_input_target\ nontarget _xx代表被试个数。若多分类数据则为Standard_input_xx (self/other/nonblind等)。
三、脑电处理 代码
提示:代码环境为 matlab 2018
3.0 参数设置
原采样率 fs_raw=1000Hz,降低到 fs_down = 125Hz
一次进行10人次的批处理,subject_num = [1;29]
每段数据分段长度为1秒,从刺激开始前0.2秒,至刺激开始后1.2秒 ,start_point = -0.2; end_point = 1.2;
目标刺激的打标标签为4,target_label = 4;
非目标刺激的打标标签为6,nontarget_label = 6;
处理全部导联编号为1-128的电极,perocess_channel = [1 ; 128];
%% 0.!!!需手动调整参数
data_path = 'C:\Users\Amax\Desktop\basetest_flod\raw_data_flod\';
svae_path = 'C:\Users\Amax\Desktop\basetest_flod\save_fold\';
file_name = 'Edge128_s';
stuct_name = 'Task_EEG';
file_target_name = 'self';
file_nontarget_name = 'nonblind';
raw_temp_file = load ([data_path ,file_name,'2']);
raw_temp_data = raw_temp_file.(stuct_name);
fs_raw = 1000;
fs_down = 125; %降采样后采样率
subject_num = [1 ; 10];
start_point = -0.2;
end_point = 1.2;
target_label = 4;
nontarget_label=6;
perocess_channel = [1 ; 128];
经验建议:
- 采样率降到200Hz以下,目前主流研究认为,ERP脑电有效频率<30Hz,根据脑奎斯特定理,采样率到60Hz以上即可。但为了多一些保存细节,降采样也会保持在100Hz以上,采样率是最影响计算时间的参数之一,尤其影响后期的非线性计算,绘图、特征分析等。
- 建议每批处理人数<10人,如有大量被试应分为多组。一是由于多被试处理时间长,中间运算和调试周期较长;二是多被试计算结果存储量大,MATLAB对于2GB以上的数据存储较慢,并且下一阶段读取也缓慢。
- 任务态脑电信号相比静息态信号,最主要是具有时间锚点,即刺激开始播放的时刻标记(称为Triger或者Marker)。分析时关注刺激发生后的大脑活动,一半时间长度为1~2秒,但也许截取刺激前 0.1~0.2秒数据作为基线(一般为刺激后留取数据长度的10%),用来对比刺激出现前后的脑模式差异
3.1 数据导入
导入原始数据,并输出显示基本数据信息:
%% 1.Standard_input
% 0.1 task_data 输入数据格式为:通道数*采样点数
Standard_input_target = [];
Standard_input_nontarget = [];
Standard_input_target.fs = fs_down; %保存结构体中有当前采样率信息
Standard_input_nontarget.fs = fs_down;
event_target_time = raw_temp_data.event_time(find(raw_temp_data.event_num==target_label));
event_nontarget_time = raw_temp_data.event_time(find(raw_temp_data.event_num==nontarget_label));
remain_trial = size(raw_temp_data.event_num,2);
disp(['采样率: ' , num2str(fs_raw), '||总试次数量: ' , num2str(remain_trial), '||目标试次数量: ' , num2str(size(event_target_time,2)), '||非目标试次数量: ' ,num2str(size(event_nontarget_time,2))]);
3.2 前置准备-主函数
主要功能依靠调用 Standard_cut_task函数实现:
%% 1.切分数据
disp(['数据分段中..']);
[Standard_input_target.data,Standard_input_nontarget.data] = Standard_cut_task(data_path,file_name,stuct_name,fs_raw,fs_down,subject_num,target_label,nontarget_label,start_point,end_point,perocess_channel);
disp(['||已完成标准分段||']);
3.3 前置准备-功能函数
主功能函数 Standard_cut_task:
function [Standard_input_target,Standard_input_nontarget] = Standard_cut_task(data_path,file_name,stuct_name,fs_raw,fs_down,subject_num,target_label,nontarget_label,start_point,end_point,perocess_channel)
%% 0.参数说明
% data_path 数据路径
% file_name mat文件统一前缀
% stuct_name 结构体名称
% fs_raw 为原始数据采样率
% fs_down 为降采样率
% subject_num 被试起止编号
% target_label 为目标标签号
% nontarget_label 为非目标标签号
% 起止位置可设-0.2 0.8,或0,1
% start_point 为试次起始位置
% end_point 为试次终止位置
% perocess_channel 有效数据通道的首末
print_count=0;
Standard_input_target = [];
Standard_input_nontarget = [];
sub_count = 1;
for sub_loop = subject_num(1,1):subject_num(2,1)
raw_file = load ([data_path ,file_name , num2str(sub_loop)]);
event_num = raw_file.(stuct_name).event_num;
event_time = raw_file.(stuct_name).event_time;
raw_data = raw_file.(stuct_name).data;
event_target_time = event_time(find(event_num==target_label));
event_nontarget_time = event_time(find(event_num==nontarget_label));
%% 1.切分数据
for trial_loop = 1:size(event_target_time,2)
cut_temp = [];
cut_temp = raw_data(perocess_channel(1,1):perocess_channel(2,1), event_target_time(1,trial_loop)+start_point*fs_raw : event_target_time(1,trial_loop)+end_point*fs_raw-1);
cut_temp_downsample = downsample(cut_temp',fs_raw/fs_down)';
Standard_input_target{trial_loop,sub_count} = cut_temp_downsample;
end
for trial_loop = 1:size(event_nontarget_time,2)
cut_temp = [];
cut_temp = raw_data(perocess_channel(1,1):perocess_channel(2,1), event_nontarget_time(1,trial_loop)+start_point*fs_raw : event_nontarget_time(1,trial_loop)+end_point*fs_raw-1);
cut_temp_downsample = downsample(cut_temp',fs_raw/fs_down)';
Standard_input_nontarget{trial_loop,sub_count} = cut_temp_downsample;
end
fprintf(repmat('\b',1,print_count));
print_count=fprintf('计算标准化分段进度 : %f',sub_count/(subject_num(2,1) - subject_num(1,1)+1));
sub_count = sub_count+1;
end
fprintf('\n');
end
3.4 前置准备-结果保存
最终,结果保存:
%% 2.保存标准输入文件
Standard_input_target.subject_num = subject_num;
Standard_input_nontarget.subject_num = subject_num;
disp(['标准分段保存中..']);
save([ svae_path , 'Standard_input_',file_target_name,'_',num2str(subject_num(1,1)),'_',num2str(subject_num(2,1))],'Standard_input_target');
save([ svae_path , 'Standard_input_',file_nontarget_name,'_',num2str(subject_num(1,1)),'_',num2str(subject_num(2,1))],'Standard_input_nontarget');
disp(['||已完成标准分段保存||']);
t_Standard_input_cost = toc;
disp(['标准输入格式调整完毕,耗时: ',num2str(t_Standard_input_cost)]);
四、前置准备 整体代码
静息态信号整体代码:
disp(['||0.任务态类数据处理-标准输入格式||']);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%% 0.!!!需手动调整参数
data_path = 'C:\Users\Amax\Desktop\basetest_flod\raw_data_flod\';
svae_path = 'C:\Users\Amax\Desktop\basetest_flod\save_fold\';
file_name = 'Edge128_s';
stuct_name = 'Task_EEG';
file_target_name = 'self';
file_nontarget_name = 'nonblind';
raw_temp_file = load ([data_path ,file_name,'2']);
raw_temp_data = raw_temp_file.(stuct_name);
fs_raw = 1000;
fs_down = 125; %降采样后采样率
subject_num = [1 ; 10];
start_point = -0.2;
end_point = 1.2;
target_label = 4;
nontarget_label=6;
perocess_channel = [1 ; 128];
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
tic;
%% 1.Standard_input
% 0.1 task_data 输入数据格式为:通道数*采样点数
Standard_input_target = [];
Standard_input_nontarget = [];
Standard_input_target.fs = fs_down; %保存结构体中有当前采样率信息
Standard_input_nontarget.fs = fs_down;
event_target_time = raw_temp_data.event_time(find(raw_temp_data.event_num==target_label));
event_nontarget_time = raw_temp_data.event_time(find(raw_temp_data.event_num==nontarget_label));
remain_trial = size(raw_temp_data.event_num,2);
disp(['采样率: ' , num2str(fs_raw), '||总试次数量: ' , num2str(remain_trial), '||目标试次数量: ' , num2str(size(event_target_time,2)), '||非目标试次数量: ' ,num2str(size(event_nontarget_time,2))]);
%% 1.切分数据
disp(['数据分段中..']);
[Standard_input_target.data,Standard_input_nontarget.data] = Standard_cut_task(data_path,file_name,stuct_name,fs_raw,fs_down,subject_num,target_label,nontarget_label,start_point,end_point,perocess_channel);
disp(['||已完成标准分段||']);
%% 2.保存标准输入文件
Standard_input_target.subject_num = subject_num;
Standard_input_nontarget.subject_num = subject_num;
disp(['标准分段保存中..']);
save([ svae_path , 'Standard_input_',file_target_name,'_',num2str(subject_num(1,1)),'_',num2str(subject_num(2,1))],'Standard_input_target');
save([ svae_path , 'Standard_input_',file_nontarget_name,'_',num2str(subject_num(1,1)),'_',num2str(subject_num(2,1))],'Standard_input_nontarget');
disp(['||已完成标准分段保存||']);
t_Standard_input_cost = toc;
disp(['标准输入格式调整完毕,耗时: ',num2str(t_Standard_input_cost)]);
总结
前置准备是数据处理的敲门砖,本文仅进行了基础的处理。
任务态的前置准备,通过主功能函数 Standard_cut_task实现
任务态作为BCI中的常用刺激范式,科研人员也希望探索大脑对外界刺激的响应
毕竟人类是个开放的系统,人作为自然的一部分,随时准备响应外界的环境,
这个响应,可以理解为脑响应
还有很多潜在的bug,例如仪器数据格式、软件运行内存、硬件运行时间等等…
挂一漏万,如有笔误请大家指正~
感谢您耐心的观看,本系列更新了约30000字,约3000行开源代码,体量相当于一篇硕士工作。
往期内容放在了文章开头,麻烦帮忙点点赞,分享给有需要的朋友~
坚定初心,本博客永远:
免费拿走,全部开源,全部无偿分享~
To:新想法、鬼点子的道友:
自己:脑机接口+人工智领域,主攻大脑模式解码、身份认证、仿脑模型…
在读博士第3年,在最后1年,希望将代码、文档、经验、掉坑的经历分享给大家~
做的不好请大佬们多批评、多指导~ 虚心向大伙请教!
想一起做些事情 or 奇奇怪怪点子 or 单纯批评我的,请至[email protected]
