脑电EEG代码开源分享 【6.分类模型-机器学习篇】
往期文章
希望了解更多的道友点这里
0. 分享【脑机接口 + 人工智能】的学习之路
1.1 . 脑电EEG代码开源分享 【1.前置准备-静息态篇】
1.2 . 脑电EEG代码开源分享 【1.前置准备-任务态篇】
2.1 . 脑电EEG代码开源分享 【2.预处理-静息态篇】
2.2 . 脑电EEG代码开源分享 【2.预处理-任务态篇】
3.1 . 脑电EEG代码开源分享 【3.可视化分析-静息态篇】
3.2 . 脑电EEG代码开源分享 【3.可视化分析-任务态篇】
4.1 . 脑电EEG代码开源分享 【4.特征提取-时域篇】
4.2 . 脑电EEG代码开源分享 【4.特征提取-频域篇】
4.3 . 脑电EEG代码开源分享 【4.特征提取-时频域篇】
4.4 . 脑电EEG代码开源分享 【4.特征提取-空域篇】
5 . 脑电EEG代码开源分享 【5.特征选择】
6.1 . 脑电EEG代码开源分享 【6.分类模型-机器学习篇】
6.2 . 脑电EEG代码开源分享 【6.分类模型-深度学习篇】
汇总. 专栏:脑电EEG代码开源分享【文档+代码+经验】
0 . 【深度学习】常用网络总结
脑电EEG代码开源分享 【6. 分类模型-机器学习篇】
- 往期文章
- 一、前言
- 二、分类模型 框架介绍
- 三、代码格式说明
- 三、脑电特征选择 代码
-
- 3.0 参数设置
- 3.1分类器设计
-
- 3.1.1 KNN
- 3.1.2 RF
- 3.1.3 SVM
- 3.1.4 DAC
- 3.1.5 Bayes
- 3.1.6 Boosting
- 3.1.7 Hard-vote
- 3.2 分类结果可视化
-
- 3.2.1 ROC曲线绘制
- 3.2.2 AUC计算
- 四、前置准备 整体代码
- 总结
- To:新想法、鬼点子的道友:
一、前言
本文档旨在归纳BCI-EEG-matlab的数据处理代码,作为EEG数据处理的总结,方便快速搭建处理框架的Baseline,实现自动化、模块插拔化、快速化。本文以任务态(锁时刺激,如快速序列视觉呈现)为例,分享脑电EEG的分析处理方法。
脑电数据分析系列。分为以下6个模块:
- 前置准备
- 数据预处理
- 数据可视化
- 特征提取(特征候选集)
- 特征选择(量化特征择优)
- 分类模型
本文内容:【6. 分类模型-机器学习篇】】
提示:以下为各功能代码详细介绍,若节约阅读时间,请下滑至文末的整合代码
二、分类模型 框架介绍
前文我们花了4篇文章讲完了时域、频域、时频域、空域的特征提取,并应用特征选择方法筛选出了优质特征,终于迎来尾声的分类模型,打通了从原始数据到分类结果的全流程。
分类模型-机器学习篇主要介绍了基础的机器学习算法,使用matlab 自带的分类器函数进行分类。为了方便更多同学对分类器的了解,这里几乎列出了matlab 常用的 6种分类器,并且附带了一种简单的融合分类模型。
7种分类器各有优势,对相同的特征的分类性能也有差异,建议大家广泛尝试,总结形成自己应用分类器经验。分类器也提供了多种参数设置,建议初学者使用默认参数,逐渐熟悉后尝试对重要参数进行探索。
分类模型的代码框图、流程如下所示:

分类模型的主要功能,分为以下7部分:
- KNN
- RF
- SVM
- DAC
- Bayes
- AdaBoost
- Hard-vote
-
KNN:K-Nearest Neighbor,K近邻分类算法,很朴素的分类想法:距离预测样本在特征空间中最近的几个训练样本是哪类,预测样本就分为哪类,类别有矛盾就少数服从多数。KNN算法中重要的参数包括:1. K值:选择最近几个训练样本进行投票,一般设为奇数方便投票。2.距离:定义最近这个距离概念有多种方法,默认使用欧氏距离。
KNN算法示意图:

-
RF:Random forest(RF),随机森林算法,思想在于用多个弱分类器集成为分类能力较好的强分类器,有较好的抗过拟合能力。森林:主体架构通过决策树来实现。随机:随机选择部分样本训练。RF的重要参数就是决策树的个数,一般经验将树个数设置在10-50。

- SVM:(support vector machines,SVM),支持向量机,思想在推导出最佳的分类边界,使得分类边界到各类别的最小距离最大化。这个分类边界也叫分类超平面,二维特征的使用曲线分界,高维特征空间则是分类曲面。SVM的另一重心在于核函数,例如 径向基(RBF)核函数够容易构造复杂曲面(个人亲测有效)。

- DAC:拟合判别分析分类器,matlab源码中介绍Discriminant Discriminant analysis,我推测应该是我们常说的线性判别分析(LDA),如有错误请大家指正。LDA的分类思想等同于fisher判别分析,这在这前我们介绍过多次,直接应用:fisher本质思想是量化目标与非目标样本的聚类、离散程度。其主要公式为 不同类间中心距 除以 各自类内的样本距离,类间距使用欧式距离,类内局使用标准差。该结果越大代表此段数据:1. 不同类之间距离较远。2.并且各自类内样本紧凑。对应就是好划定分类边界。
fisher公式如下:
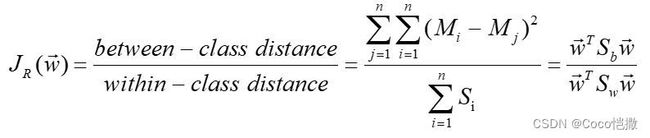
fisher示意图如下:左侧为易分类脑电样本,右侧为难分类脑电样本

- Bayes: 贝叶斯判别,使用统计先验的方法,其中心思想为:最小化分类误差。其假设特征独立并且符合预期分布,有严格的统计学推导过程,详细理论可参考:点击 点击
- AdaBoost:Adaptive Boosting(自适应增强),作为Boosting(增强)算法中代表性的一种,其通过贪婪算法的思想,每轮迭代更关注分类错误的样本,多轮迭代后错误样本的个数因高度关注而得到改善。需要注意的是,boosting算法调参时需小心,可能出现过拟合问题。近几年boosting算法都很火热,其优异稳定的性能成为多项分类算法比赛的标配,经过了时间和现实的检验,十分建议大家拓展学习Xgboost、Lightboost等算法,使用默认参数的效果都很出色。
- Hard-vote:vote投票算法,融合多个子分类器的分类结果,将子分类器的预测输出作为特征,少数服从多数的获得最终预测结果。Vote作为最简单基础的决策融合方法,其思想是集百家之长,不同分类器有各自长处,最后的融合结果综合考虑每个分类器。需要注意的是,子分类器设计尽量有差异,避免重复相近的分类模型。这里的Hard的是指硬判决,意思是将子分类器的分类标签结果作为投票依据;相对应的soft软判决,将子分类器的判别概率作为投票依据,个人经验软分类器优于硬分类器1~3%。
三、代码格式说明
本文非锁时任务态(下文以静息态代替)范例为:ADHD患者、正常人群在静息状态下的脑模式分类
代码名称:代码命名为Class_detail
参数设置:训练集和测试集的数据标签/选择特征个数百分比/特征个数与样本个数百分比/随机循环个数/分类器选择
输入格式:输入格式承接特征候选集Festure_candidate_xxx(特征域名称)_target/nontarget,以及单域/全域的特征选择排序。
输出及保存格式:分别进行开集\闭集的分类性能测试,在单域/全域进行特征排序和打分,分类结果包括ACC\TA\TR\ROC\AUC。绘图命名为Class__XX(特征域)_XX(分类指标),绘图的开闭集结果绘制一幅图中,横轴为特征个数,纵轴为分类指标。分类结果保存格式为Class_open\5flod_XX(特征域)_XX(分类指标ACC\TA\TR\ROC\AUC)。
三、脑电特征选择 代码
提示:代码环境为 matlab 2018
提示:2分类的代码示例,少量分类器不支持多分类如SVM,多分类器设置会撰写新文章介绍
3.0 参数设置
输入值:
1.all_train_sample:训练数据
2.label_train:训练标签
3.all_test_sample:测试数据
4.test_label:测试标签
返回值:
1.class_list 为分类性能结果反馈包括:
1.1正确率ACC,第1列
1.2正确接受率, 第2列
1.3正确拒绝率, 第3列
2. class_label_list 按照原样本顺序返回的预测标签,结果矩阵为7*样本数,7分别代表7种分类器各自的预测标签
3.1分类器设计
3.1.1 KNN
采用KNN常用参数设置,最近邻的3个样本:‘NumNeighbors’,3:
%% KNN
knn_class = ClassificationKNN.fit(all_train_sample,label_train,'NumNeighbors',3);
[predict_label_knn,Scores_knn] = predict(knn_class, all_test_sample);
accuracy_knn = length(find(predict_label_knn == test_label))/length(test_label)*100;
class_label_list(1,:) = predict_label_knn;
class_list(1,:) = accuracy_knn;
TA_list(1,:) = length(find(predict_label_knn(1:label_0,1) == test_label(1:label_0,1)))/length(test_label(1:label_0,1))*100;
TC_list(1,:) = length(find(predict_label_knn(label_0+1:end,1) == test_label(label_0+1:end,1)))/length(test_label(label_0+1:end,1))*100;
3.1.2 RF
决策树数量为10,特征数个人习惯设置成1/10的特征个数,此参数>100严重影响计算时间
RF分类器输出结果是最奇怪的Str + Cell格式,需要转换成mat格式
%% RF
nTree = 10;
RF_class = TreeBagger(nTree,all_train_sample,label_train);
[predict_label_RF,Scores_RF] = predict(RF_class,all_test_sample);
predict_label_RF= cell2mat(predict_label_RF);
predict_label_RF = str2num(predict_label_RF);
accuracy_RF = length(find(predict_label_RF == test_label))/length(test_label)*100;
class_label_list(2,:) = predict_label_RF;
class_list(2,:) = accuracy_RF;
TA_list(2,:) = length(find(predict_label_RF(1:label_0,1) == test_label(1:label_0,1)))/length(test_label(1:label_0,1))*100;
TC_list(2,:) = length(find(predict_label_RF(label_0+1:end,1) == test_label(label_0+1:end,1)))/length(test_label(label_0+1:end,1))*100;
3.1.3 SVM
参数设置,核选择为经典的径向基函数:‘KernelFunction’,‘rbf’
%% SVM
SVM_class = fitcsvm(all_train_sample, label_train,'Standardize',true,'KernelFunction','rbf','KernelScale','auto');
[predict_label_svm,Scores_svm] = predict(SVM_class, all_test_sample);
accuracy_SVM = length(find(predict_label_svm == test_label))/length(test_label)*100;
class_label_list(3,:) = predict_label_svm;
class_list(3,:) = accuracy_SVM;
TA_list(3,:) = length(find(predict_label_svm(1:label_0,1) == test_label(1:label_0,1)))/length(test_label(1:label_0,1))*100;
TC_list(3,:) = length(find(predict_label_svm(label_0+1:end,1) == test_label(label_0+1:end,1)))/length(test_label(label_0+1:end,1))*100;
3.1.4 DAC
参数设置,DAC默认设置
%% DAC
DAC_class = ClassificationDiscriminant.fit(all_train_sample, label_train);
[predict_label_DAC,Scores_DAC] = predict(DAC_class, all_test_sample);
accuracy_DAC = length(find(predict_label_DAC == test_label))/length(test_label)*100;
class_label_list(4,:) = predict_label_DAC;
class_list(4,:) = accuracy_DAC;
TA_list(4,:) = length(find(predict_label_DAC(1:label_0,1) == test_label(1:label_0,1)))/length(test_label(1:label_0,1))*100;
TC_list(4,:) = length(find(predict_label_DAC(label_0+1:end,1) == test_label(label_0+1:end,1)))/length(test_label(label_0+1:end,1))*100;
3.1.5 Bayes
参数设置,Bayes默认设置
%% bayes
Bayes_class = fitcnb(all_train_sample, label_train);
[predict_label_bayes,Scores_bayes] = predict(Bayes_class, all_test_sample);
accuracy_bayes = length(find(predict_label_bayes == test_label))/length(test_label)*100;
class_label_list(5,:) = predict_label_bayes;
class_list(5,:) = accuracy_bayes;
TA_list(5,:) = length(find(predict_label_bayes(1:label_0,1) == test_label(1:label_0,1)))/length(test_label(1:label_0,1))*100;
TC_list(5,:) = length(find(predict_label_bayes(label_0+1:end,1) == test_label(label_0+1:end,1)))/length(test_label(label_0+1:end,1))*100;
3.1.6 Boosting
参数设置:应用AdaBoostM1算法使用5个决策树的分类模型,‘AdaBoostM1’ ,5,‘tree’,‘type’,‘classification’
%% Boosting
boost_class = fitensemble(all_train_sample, label_train,'AdaBoostM1' ,5,'tree','type','classification');
[predict_label_boost,Scores_boost] = predict(boost_class, all_test_sample);
accuracy_boost = length(find(predict_label_boost == test_label))/length(test_label)*100;
class_label_list(6,:) = predict_label_boost;
class_list(6,:) = accuracy_boost;
TA_list(6,:) = length(find(predict_label_boost(1:label_0,1) == test_label(1:label_0,1)))/length(test_label(1:label_0,1))*100;
TC_list(6,:) = length(find(predict_label_boost(label_0+1:end,1) == test_label(label_0+1:end,1)))/length(test_label(label_0+1:end,1))*100;
3.1.7 Hard-vote
参数设置:用前6种分类器的结果投票,少数服从多数
%% hard class
class_label_list(7,:) = round(mean(class_label_list(1:6,:)));
3.2 分类结果可视化
3.2.1 ROC曲线绘制
function [Pd Pf]=ROC( Y_taris,Y_othis)
amin=min(min(Y_othis));
amax=max(max(Y_othis));
middata=(amax-amin)/1e5;
x=[amin:middata:amax]; %x 表示阈值选择范围
Pd=zeros(1,length(x));
Pf=zeros(1,length(x));
for i=1:length(x)
Pd(i)=length(find((Y_taris>x(i))==1))/length(Y_taris);
Pf(i)=length(find((Y_othis>x(i))==1))/length(Y_othis);
end
% figure
% plot(Pf,Pd)
% for i=1:length(x)
% dt(i)=Pd(i)/Pf(i) ;
% end
% b=x(find(dt==max(dt)));
end
3.2.2 AUC计算
function value = AUC(Pf,Pd)
% 给定Pf,Pd返回对应的AUC值
% s=size(Pf,2);
% value=sum(Pd)*(1/s);
Pf_diff=diff(Pf);
value=abs(sum(Pd(2:end).*Pf_diff));
end
四、前置准备 整体代码
分类器-机器学习 整体汇总:
function [class_label_list,class_list] = zrk_class_detail(all_train_sample,label_train,all_test_sample,test_label)
%% ZRK 寒假 2020-02-13
% 应用matlab自带分类器进行分类
% KNN、RF、SVM、DAC、Bayes、AdaBoost、Hard-vote
% 输入值:
% 1.all_train_sample:训练数据
% 2.label_train:训练标签
% 3.all_test_sample:测试数据
% 4.test_label:测试标签
% 返回值:
% 1.class_list 为分类性能结果反馈包括:
% 1.1正确率ACC 第1列
% 1.2正确接受率 第2列
% 1.3正确拒绝率 第3列
% 2. class_label_list 按照原样本顺序返回的预测标签
% 结果矩阵为7*样本数,7分别代表7种分类器各自的预测标签
class_label_list = zeros(7,size(test_label,1));
class_list = zeros(7,1);
TA_list = zeros(7,1);
TR_list = zeros(7,1);
label_0 = sum(test_label==0);
label_1 = sum(test_label==1);
%% KNN
knn_class = ClassificationKNN.fit(all_train_sample,label_train,'NumNeighbors',3);
[predict_label_knn,Scores_knn] = predict(knn_class, all_test_sample);
accuracy_knn = length(find(predict_label_knn == test_label))/length(test_label)*100;
class_label_list(1,:) = predict_label_knn;
class_list(1,:) = accuracy_knn;
TA_list(1,:) = length(find(predict_label_knn(1:label_0,1) == test_label(1:label_0,1)))/length(test_label(1:label_0,1))*100;
TC_list(1,:) = length(find(predict_label_knn(label_0+1:end,1) == test_label(label_0+1:end,1)))/length(test_label(label_0+1:end,1))*100;
%% RF
nTree = 10;
RF_class = TreeBagger(nTree,all_train_sample,label_train);
[predict_label_RF,Scores_RF] = predict(RF_class,all_test_sample);
predict_label_RF= cell2mat(predict_label_RF);
predict_label_RF = str2num(predict_label_RF);
accuracy_RF = length(find(predict_label_RF == test_label))/length(test_label)*100;
class_label_list(2,:) = predict_label_RF;
class_list(2,:) = accuracy_RF;
TA_list(2,:) = length(find(predict_label_RF(1:label_0,1) == test_label(1:label_0,1)))/length(test_label(1:label_0,1))*100;
TC_list(2,:) = length(find(predict_label_RF(label_0+1:end,1) == test_label(label_0+1:end,1)))/length(test_label(label_0+1:end,1))*100;
%% SVM
SVM_class = fitcsvm(all_train_sample, label_train,'Standardize',true,'KernelFunction','rbf','KernelScale','auto');
[predict_label_svm,Scores_svm] = predict(SVM_class, all_test_sample);
accuracy_SVM = length(find(predict_label_svm == test_label))/length(test_label)*100;
class_label_list(3,:) = predict_label_svm;
class_list(3,:) = accuracy_SVM;
TA_list(3,:) = length(find(predict_label_svm(1:label_0,1) == test_label(1:label_0,1)))/length(test_label(1:label_0,1))*100;
TC_list(3,:) = length(find(predict_label_svm(label_0+1:end,1) == test_label(label_0+1:end,1)))/length(test_label(label_0+1:end,1))*100;
%% DAC
DAC_class = ClassificationDiscriminant.fit(all_train_sample, label_train);
[predict_label_DAC,Scores_DAC] = predict(DAC_class, all_test_sample);
accuracy_DAC = length(find(predict_label_DAC == test_label))/length(test_label)*100;
class_label_list(4,:) = predict_label_DAC;
class_list(4,:) = accuracy_DAC;
TA_list(4,:) = length(find(predict_label_DAC(1:label_0,1) == test_label(1:label_0,1)))/length(test_label(1:label_0,1))*100;
TC_list(4,:) = length(find(predict_label_DAC(label_0+1:end,1) == test_label(label_0+1:end,1)))/length(test_label(label_0+1:end,1))*100;
%% bayes
Bayes_class = fitcnb(all_train_sample, label_train);
[predict_label_bayes,Scores_bayes] = predict(Bayes_class, all_test_sample);
accuracy_bayes = length(find(predict_label_bayes == test_label))/length(test_label)*100;
class_label_list(5,:) = predict_label_bayes;
class_list(5,:) = accuracy_bayes;
TA_list(5,:) = length(find(predict_label_bayes(1:label_0,1) == test_label(1:label_0,1)))/length(test_label(1:label_0,1))*100;
TC_list(5,:) = length(find(predict_label_bayes(label_0+1:end,1) == test_label(label_0+1:end,1)))/length(test_label(label_0+1:end,1))*100;
%% Boosting
boost_class = fitensemble(all_train_sample, label_train,'AdaBoostM1' ,5,'tree','type','classification');
[predict_label_boost,Scores_boost] = predict(boost_class, all_test_sample);
accuracy_boost = length(find(predict_label_boost == test_label))/length(test_label)*100;
class_label_list(6,:) = predict_label_boost;
class_list(6,:) = accuracy_boost;
TA_list(6,:) = length(find(predict_label_boost(1:label_0,1) == test_label(1:label_0,1)))/length(test_label(1:label_0,1))*100;
TC_list(6,:) = length(find(predict_label_boost(label_0+1:end,1) == test_label(label_0+1:end,1)))/length(test_label(label_0+1:end,1))*100;
%% hard class
class_label_list(7,:) = round(mean(class_label_list(2:6,:)));
class_list(7,:) = length(find(class_label_list(7,:) == test_label'))/length(test_label)*100;
TA_list(7,:) = length(find(class_label_list(7,1:label_0)' == test_label(1:label_0,1)))/length(test_label(1:label_0,1))*100;
TC_list(7,:) = length(find(class_label_list(7,label_0+1:end)' == test_label(label_0+1:end,1)))/length(test_label(label_0+1:end,1))*100;
class_list = [class_list TA_list TC_list ];
end
总结
准确的分类、识别、决策、判断,自古以来就是现实中要面对的难题,
当下最火的神经网络的打响,离不开猫狗分类的ImageNet
分类器模型的构建思路多样,组合样式丰富,
由于分类器几乎惠及所有判别领域,有很大的现实需求,
大量的学者将精力花费在好的分类器设计上,
我们可以借鉴多个领域的分类建模思想。
通过脑电信号反推刺激类别、预测脑响应模式,
此类大脑解码问题,不仅有助于脑机接口(BCI)应用,还会辅助机制分析,脑活动建模
囿于能力,挂一漏万,如有笔误请大家指正~
感谢您耐心的观看,本系列更新了约30000字,约3000行开源代码,体量相当于一篇硕士工作。
往期内容放在了文章开头,麻烦帮忙点点赞,分享给有需要的朋友~
坚定初心,本博客永远:
免费拿走,全部开源,全部无偿分享~
To:新想法、鬼点子的道友:
自己:脑机接口+人工智领域,主攻大脑模式解码、身份认证、仿脑模型…
在读博士第3年,在最后1年,希望将代码、文档、经验、掉坑的经历分享给大家~
做的不好请大佬们多批评、多指导~ 虚心向大伙请教!
想一起做些事情 or 奇奇怪怪点子 or 单纯批评我的,请至[email protected]
