tensorflow卷积神经网络实战:Fashion Mnist 图像分类与人马分类
卷积神经网络实战:Fashion Mnist 图像分类与人马分类
- 一、FashionMnist的卷积神经网络模型
-
- 1.卷积VS全连接
- 2.卷积网络结构
- 3.卷积模型结构
-
- 1)Output Shape
- 2)Param
- 3.卷积每层的作用
-
- 1)每层都做了什么
- 4.网络看到的图像是什么样的?
-
- 1)第一个卷积层的图像
- 2)第一个池化层的图像
- 3)第1个过滤器的卷积图像
- 二、卷积神经网络人马分类实战
-
- 1.准备训练数据
-
- 1)wget命令
- 2)尝试其他方法下载
- 3)解压数据
- 4)数据预处理之ImageDataGenerator
- 2.构建并训练模型
-
- 1)模型构建与训练
- 2)模型的结构
- 3.参数优化
-
- 1)哪些参数需要进行优化
- 2)Hyperband方法
- 3)增加优化参数
一、FashionMnist的卷积神经网络模型
1.卷积VS全连接
卷积神经网络就是在全连接网络模型的基础上增加了卷积层化池化层,相比全连接网络,卷积神经网络模型的层次更深从而模型的拟合度更好。
2.卷积网络结构
- cov2D是一个二维的卷积层,它的参数包括:过滤器的个数,过滤器的尺寸,激活函数,输入的尺寸;
- MaxPOoling2D是一个二维的最大池化层,它的参数是池化核的大小。
import tensorflow as tf
from tensorflow import keras
fashion_mnist=keras.datasets.fashion_mnist
(train_images,train_labels),(test_images,test_labels)=fashion_mnist.load_data()
model=keras.Sequential()
model.add(keras.layers.Conv2D(64,(3,3),activation='relu',input_shape=(28,28,1)))
model.add(keras.layers.MaxPooling2D(2,2))
model.add(keras.layers.Conv2D(64,(3,3),activation='relu'))
model.add(keras.layers.MaxPooling2D(2,2))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(128,activation=tf.nn.relu))
model.add(keras.layers.Dense(10,activation=tf.nn.softmax))
train_images_scaled=train_images/255.0
test_images=test_images/255.0
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(train_images_scaled, train_labels, epochs=5)
#test_loss = model.evaluate(test_images, test_labels)
运行结果:全连接VS卷积神经网络
图一:全连接网络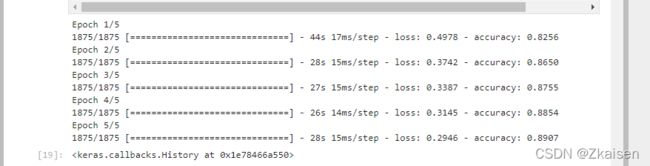
图二:卷积神经网络
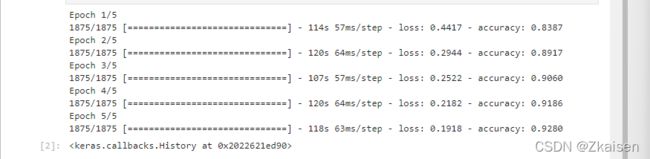
从运行结果可以看出:卷积神经网络模loss更小了,accuracy更高了。accuracy已经增加到0.9280,loss已经减少到0.1918,与全连接神经网络模型相比,精度更高了,训练的时间也增加了,全连接网络结构,没次平均训练时间是30秒左右,而卷积神经网络结构训练时间平均是120秒左右。
3.卷积模型结构
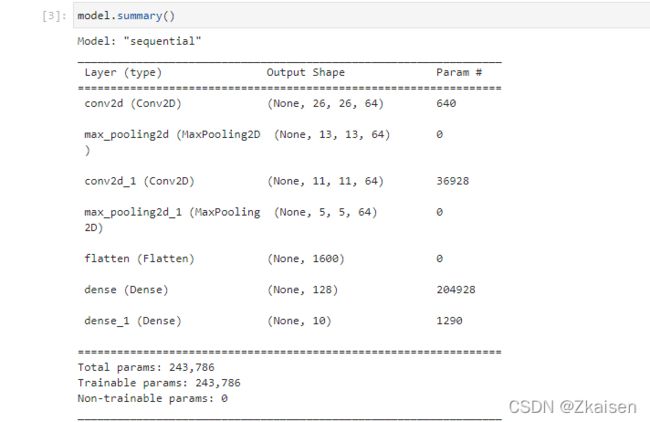
1)Output Shape
- 第一个卷积层:输入是28×28,过滤器是3×3,输出是26×26,64个过滤器,经过第一次卷积一张图片就变成了64张图片;
- 第一个池化层:把图像尺寸减为四分之一,即长宽各减一半,原来26×26的图像变为13×13的图像,64个过滤器;
- 第二个卷积层和第一个卷积层的操作一样,输入13×13的图像经过卷积变为11×11的图像,
- 第二个池化层和第一个池化层的操作一样,输入11×11的图像变为5×5的图像 ;
- Flatten层:把所有像素“展平”,那么一共为5×5×64=1600个神经元
2)Param
- 第一个卷积层:(33+1)64=640;
- 第一个池化层:没有调整参数,所以为 0;
- 第二个卷积层:((33+1)64+1)*64=36928 ;
- 第二个池化层没有调整参数,所以为0 ;
- Flatten层:没有调整参数,所以为0。
3.卷积每层的作用
1)每层都做了什么
以下代码是实现查看卷积神经网络各层数据的
import matplotlib.pyplot as plt
layer_outputs=[layer.output for layer in model.layers]#读取模型的每个层
activation_model=tf.keras.models.Model(inputs=model.input,outputs=layer_outputs)#把input和output放到一起构成一个对象
pred=activation_model.predict(test_images[0].reshape(1,28,28,1))#把这个对象用到一张图片上,这里是测试第一张图像,把结果传给pre
pred
运行结果:
执行以下代码,根据输出结果我们可知上面的pred实际输出的是跟层的数据,因为一共有7层,所以pred的长度为7.
len(pred)

4.网络看到的图像是什么样的?
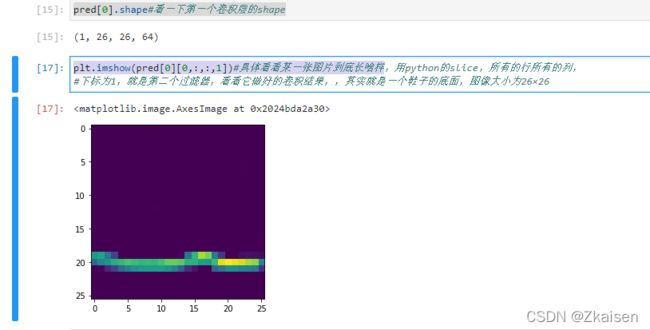
1)第一个卷积层的图像
第0张图像,第一个卷积层的图像,用python的slice,所有的行所有的列,下标为1,就是第二个过滤器,看看它做好的卷积结果,,其实就是一个鞋子的底面,图像大小为26×26
pred[0].shape#看一下第一个卷积层的shape
plt.imshow(pred[0][0,:,:,1])#具体看看某一张图片到底长啥样
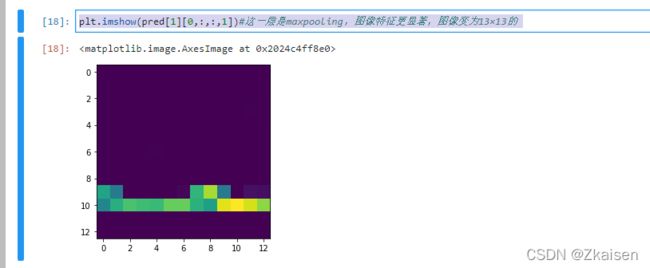
2)第一个池化层的图像
第0张图像第一个池化层的图像的样子,maxpooling,图像特征更显著,图像变为13×13的
plt.imshow(pred[1][0,:,:,1])#这一层是maxpooling,图像特征更显著,图像变为13×13的
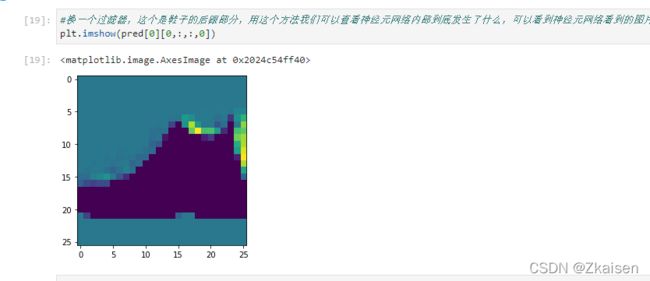
3)第1个过滤器的卷积图像
二、卷积神经网络人马分类实战
1.准备训练数据
1)wget命令
- wget命令简介
wget是linux上的命令行的下载工具。wget支持HTTP和FTP协议,支持代理服务器和断点续传功能,能够自动递归远程主机的目录,找到合乎条件的文件并将其下载到本地硬盘上,通常,wget用于成批量地下载Internet网站上的文件,或制作远程网站的镜像。 - 使用wget命令的话,Windows系统首先需要下载wet.exe并存放到“C:\windows\system32\”目录下
!wget --no-check-certificate \https://storage.googleapis.com/laurencemoroney-blog.appspot.com/validation-horse-or-human.zip\
-O /tmp/validation-horse-or-human.zip
!wget --no-check-certificate \
https://storage.googleapis.com/laurencemoroney-blog.appspot.com/horse-or-human.zip \
-O /tmp/horse-or-human.zip
运行结果报错:

尝试过在当前目录创建tmp文件夹、查看当前路径下文件名是否有中文字符等各种操作均以失败告终,无奈之下只好尝试其他方法
2)尝试其他方法下载
- 可以直接复制下载链接到浏览器中下载
- 也可使用wget命令直接下载到当前目录
!wget https://storage.googleapis.com/laurencemoroney-blog.appspot.com/validation-horse-or-human.zip
!wget https://storage.googleapis.com/laurencemoroney-blog.appspot.com/horse-or-human.zip
执行下载命令会显示下载进度
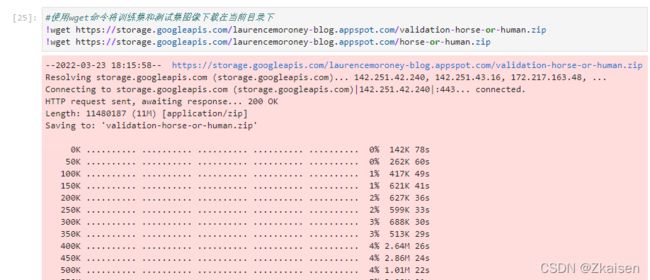
下载完成后从当前目录找到下载的压缩包,在当前目录创建tmp文件并把压缩包放进tmp文件夹中,如果不知道当前目录在哪,可以使用命令:
%pwd
3)解压数据
学习的代码没能在我电脑上直接跑通,还是找不到当前路径下的tmp文件夹,我明明已经创建了该文件夹,直接复制压缩包路径地址还不对,经过一番百度后,我觉得可能是“\”的问题,将“\”换成“\”终于对了,原来是系统把“\”当成转义字符了。
import os
import zipfile
#给出压缩包具体的路径,解压到horse-or-human目录下
local_zip = 'C:\\Users\\Zhaoyuzhu\\tmp\\horsq
e-or-human.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('C:\\Users\\Zhaoyuzhu\\tmp\\horse-or-human')
zip_ref.close()
local_zip = 'C:\\Users\\Zhaoyuzhu\\tmp\\validation-horse-or-human.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('C:\\Users\\Zhaoyuzhu\\tmp\\validation-horse-or-human')
zip_ref.close()
运行代码后在tmp文件夹生成解压好的horse-or-human和validation-horse-or -human两文件夹.
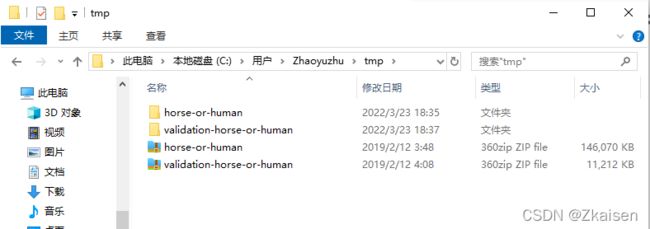
4)数据预处理之ImageDataGenerator
把下载好的图片变为可用于神经元网络寻来你的数据,需要用到一ImageDataGenerator组件 真实数据的特点:图片大小尺寸不一样通常我们需要裁剪成一个正方形的图像,数据量比较大不能一下子全装入内存,经常需要修改参数,例如输出的尺寸,增补图像的拉伸,所有这些通过手工编程也是可以实现的,就是会比较麻烦。
from tensorflow.keras.preprocessing.image import ImageDataGenerator#从keras中import ImageDataGenerator
#创建两个数据生成器,指定scaling范围0到1
train_datagen=ImageDataGenerator(rescale=1/255)
validation_datagen=ImageDataGenerator(rescale=1/255)
#指定训练数据文件夹
train_generator = train_datagen.flow_from_directory(
'C:\\Users\\Zhaoyuzhu\\tmp\\horse-or-human',#训练数据所在文件夹
target_size=(300,300),
batch_size=32,
class_mode='binary')
#指定测试数据文件夹
validation_generator = validation_datagen.flow_from_directory(
'C:\\Users\\Zhaoyuzhu\\tmp\\validation-horse-or-human',#训练数据所在文件夹
target_size=(300,300),
batch_size=32,
class_mode='binary')
运行结果:执行完可以可看到:找到1027张寻来你数据,256张测试数据

2.构建并训练模型
1)模型构建与训练
- 典型的CNN模型:有Conv2D三层,然后是全连接层,最后是一个神经元,因为是二分类问题,所以激活函数是sigmoid,
- 如果是看多分类问题的话,激活函数用‘softmax’
from tensorflow.keras.optimizers import RMSprop
model.compile(loss='binary_crossentropy',
optimizer=RMSprop(learning_rate=0.001),
metrics=['acc'])
#这里optimizer用的是RMS,也可以换成其他的
#构建并训练模型
import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16,(3,3),activation='relu',input_shape=(300,300,3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32,(3,3),activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64,(3,3),activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512,activation='relu'),
tf.keras.layers.Dense(1,activation='sigmoid')
])
#模型训练
model.compile(loss='binary_crossentropy',optimizer=RMSprop(learning_rate=0.001),metrics=['acc'])
history=model.fit(
train_generator,
epochs=15,
verbose=1,
validation_data=validation_generator,
validation_steps=8)
#model.fit中原来写x_train的地方写成train_generator,原来x_test的地方写成validation_generator
运行结果:代码未报错等它跑完
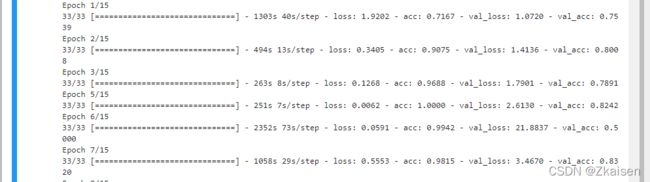
2)模型的结构
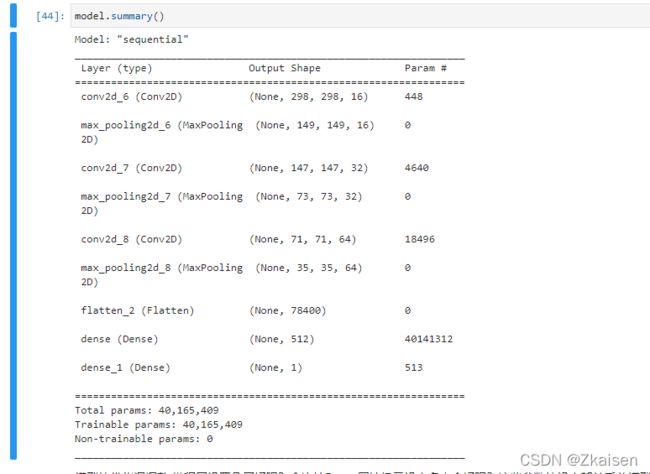
3.参数优化
1)哪些参数需要进行优化
-
模型的优化调调整:卷积层设置几层好呢?全连接Dense层神经元设定多少个好呢?这些参数的设定都关系着模型的好坏。
-
如何调整?手工调整,自己评经验修改参数看训练精度 或者写个循环来调整它的数值再记录最后的训练精度,上述方法不仅需要有一定的经验,而且比较麻烦
-
可以使用一个KerasTuner库的Hyperband方法来做参数的优化 import kerastuner.tuner import Hyperband
2)Hyperband方法
先尝试做一个参数的优化,把整个优化流程写完,运行测试代码的准确性,没有错的话再继续
import os
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import RMSprop
#创建两个数据生成器,指定scaling范围0到1
train_datagen=ImageDataGenerator(rescale=1/255)
validation_datagen=ImageDataGenerator(rescale=1/255)
#指定训练数据文件夹
train_generator = train_datagen.flow_from_directory(
'C:\\Users\\Zhaoyuzhu\\tmp\\horse-or-human',#训练数据所在文件夹
target_size=(300,300),
batch_size=32,
class_mode='binary')
#指定测试数据文件夹
validation_generator = validation_datagen.flow_from_directory(
'C:\\Users\\Zhaoyuzhu\\tmp\\validation-horse-or-human',#训练数据所在文件夹
target_size=(300,300),
batch_size=32,
class_mode='binary')
from kerastuner.tuners import Hyperband
from kerastuner.engine.hyperparameters import HyperParameters#KerasTuner库的Hyperband方法来做参数的优化
import tensorflow as tf
hp=HyperParameters()
def build_model(hp):
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(hp.Choice('num_filters_layer0',values=[16,64],default=16),(3,3),activation='relu',input_shape=(300,300,3)))
#比如:这里filters,我们就用hp.Choice('num_filters_layer0',values=[16,64],default=16)
#里随便起一个名字,训练好后它会把这个数值和这个名字num_filters_layer0对应起来保存下来,输入values指定一个范围,设定一个默认值
model.add(tf.keras.layers.MaxPooling2D(2,2))
model.add(tf.keras.layers.Conv2D(32,(3,3),activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(2,2))
model.add(tf.keras.layers.Conv2D(64,(3,3),activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(2,2))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(512,activation='relu'))
model.add(tf.keras.layers.Dense(1,activation='sigmoid'))
model.compile(loss='binary_crossentropy',optimizer=RMSprop(learning_rate=0.001),metrics=['acc'])
# model.fit(train_generator,epochs=10, validation_data=validation_generator)
return model#最后返回模型
tuner=Hyperband(
build_model,
objective='val_acc',
max_epochs=15,
directory='horse_human_params',
hyperparameters=hp,
project_name='my_horse_human_project'
)
tuner.search(train_generator,epochs=10, validation_data=validation_generator)
3)增加优化参数
- 前边只做了第一个卷积层filter数目的参数优化
- 可优化的还有全连接层的神经元个数:
hp.Int(“hidden_units”,128,512,step=32),其中三个参数分别表示名字,范围和步长 - 添加一个for循环用于实现卷积池化层数目的优化
for i in range(“num_conv_layers”,1,3)使用一个for循环,给它一个范围,这个范围不能太大,因为MaxPooling后图像会越来越小,小到变成负数时训练就无法进行了,默认的步长是1 - 每次修改部分代码后就先运行一下,无报错就先暂停运行,继续修改其他参数。
- 优化后的最终代码如下:
import os
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import RMSprop
#创建两个数据生成器,指定scaling范围0到1
train_datagen=ImageDataGenerator(rescale=1/255)
validation_datagen=ImageDataGenerator(rescale=1/255)
#指定训练数据文件夹
train_generator = train_datagen.flow_from_directory(
'C:\\Users\\Zhaoyuzhu\\tmp\\horse-or-human',#训练数据所在文件夹
target_size=(150,150),
batch_size=32,
class_mode='binary')
#指定测试数据文件夹
validation_generator = validation_datagen.flow_from_directory(
'C:\\Users\\Zhaoyuzhu\\tmp\\validation-horse-or-human',#训练数据所在文件夹
target_size=(150,150),
batch_size=32,
class_mode='binary')
from keras_tuner.tuners import Hyperband
from keras_tuner.engine.hyperparameters import HyperParameters#KerasTuner库的Hyperband方法来做参数的优化
import tensorflow as tf
hp=HyperParameters()
def build_model(hp):
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(hp.Choice('num_filters_layer0',values=[16,64],default=16),(3,3),activation='relu',input_shape=(150,150,3)))
#比如:这里filters,我们就用hp.Choice('num_filters_layer0',values=[16,64],default=16)
#里随便起一个名字,训练好后它会把这个数值和这个名字num_filters_layer0对应起来保存下来,输入values指定一个范围,设定一个默认值
model.add(tf.keras.layers.MaxPooling2D(2,2))
for i in range(hp.Int("num_conv_layers",1,3)):
model.add(tf.keras.layers.Conv2D(hp.Choice(f'num_filters_layer{i}',values=[16,64],default=16),(3,3),activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(2,2))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(hp.Int("hidden_units",128,512,step=32),activation='relu'))
model.add(tf.keras.layers.Dense(1,activation='sigmoid'))
model.compile(loss='binary_crossentropy',optimizer=RMSprop(learning_rate=0.001),metrics=['acc'])
# model.fit(train_generator,epochs=10, validation_data=validation_generator)
return model#最后返回模型
tuner=Hyperband(
build_model,
objective='val_acc',
max_epochs=15,
directory='horse_human_params',
hyperparameters=hp,
project_name='my_horse_human_project'
)
tuner.search(train_generator,epochs=10, validation_data=validation_generator)
运行结果:训练时间可能有点长,耐心等代码跑完,程序会不断的更新当前测试集最好的准确性然后保存并输出此时模型的参数。
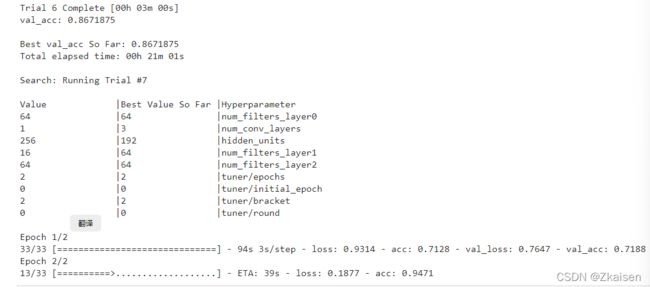
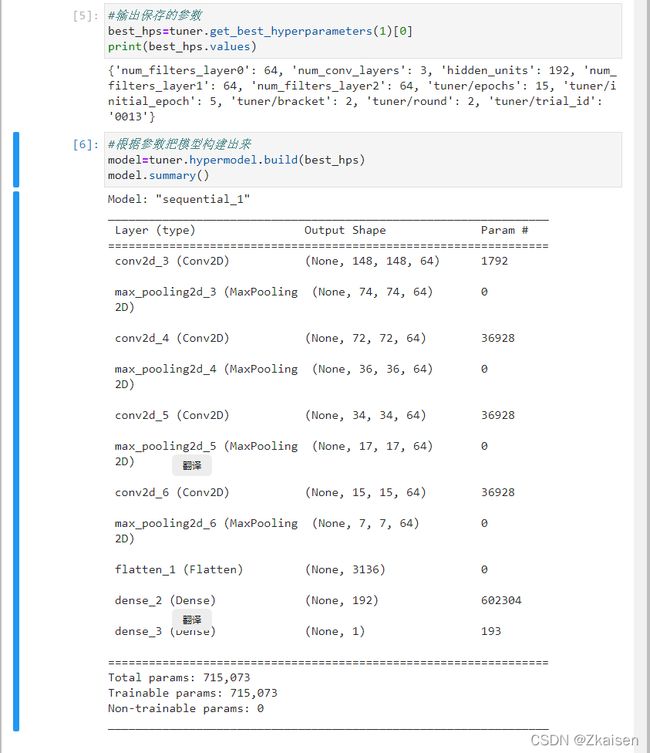
总共跑了30个Trial,最终保存的最好的一次训练的准确度0.9140625

最后,我们用保存好的参数来构建模型,下面就是我们根据最优参数构建出来的模型的结构