PVT:Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
文章目录
- Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
- 一、Feature Pyramid for Transformer
-
- 1.代码
- 二、 Transformer Encoder
-
- 1.代码
- 三、Ablation Study
-
- 1.Pyramid Structure
- 2.Deeper vs. Wider
- 3.Computation Overhead
Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
多用途的backbone,CLS、DET、SEG…
通过在transfomer blocks之间进行Shrink操作,来获得多尺度的特征图
通过spatial-reduction attention来降低计算量

一、Feature Pyramid for Transformer
通过每一层前的reshape和patch embedding来进行Shrink操作
将transformer的输出reshape成三维
在patch embedding中,先通过卷积降低HW并增加C,再reshape成二维

1.代码
PyramidVisionTransformer:将transformer的输出reshape成三维,此时的HW小于上一层,C大于上一层,参数来自于PatchEmbed
def forward_features(self, x):
outs = []
B = x.shape[0]
for i in range(self.num_stages):
patch_embed = getattr(self, f"patch_embed{i + 1}") # patch embedding中进行Shrink
pos_embed = getattr(self, f"pos_embed{i + 1}")
pos_drop = getattr(self, f"pos_drop{i + 1}")
block = getattr(self, f"block{i + 1}")
x, (H, W) = patch_embed(x) # 从patch_embed获得这一层的HW
if i == self.num_stages - 1:
pos_embed = self._get_pos_embed(pos_embed[:, 1:], patch_embed, H, W)
else:
pos_embed = self._get_pos_embed(pos_embed, patch_embed, H, W)
x = pos_drop(x + pos_embed)
for blk in block:
x = blk(x, H, W) # Attention中对k和v做SR
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() # 将transformer的输出reshape成三维 patch_size[4,2,2,2] embed_dims:[64, 128, 256, 512] 在atten之后,reshape成三维,重新进行patch embedding等操作
outs.append(x)
return outs
def forward(self, x):
x = self.forward_features(x)
if self.F4:
x = x[3:4]
return x
PatchEmbed:先通过卷积降低HW并增加C,再reshape成二维
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \
f"img_size {img_size} should be divided by patch_size {patch_size}."
self.H, self.W = img_size[0] // patch_size[0], img_size[1] // patch_size[1]
self.num_patches = self.H * self.W
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) # kernel_size=stride=patch_size 将H和W缩小patch_size倍 C变为embed_dim
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
B, C, H, W = x.shape
x = self.proj(x).flatten(2).transpose(1, 2) # 再卷积降低HW增加C 再reshape成二维 B, D, H/P, W/P -> B, D, N(HW/PP) -> B, N, D
x = self.norm(x)
H, W = H // self.patch_size[0], W // self.patch_size[1]
return x, (H, W)
二、 Transformer Encoder
Spatial-Reduction Attention:先将输入reshape成三维,再通过卷积降低HW,再将HW reshape成一个维度

1.代码
Attention
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio) # Spatial Reduction:kernel_size=stride=sr_ratio 将x_的HW降低sr_ratio倍,C不变 降低计算量和显存占用
self.norm = nn.LayerNorm(dim)
def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # q不做处理
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W) # 先reshape,将N分为H和W
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1) # 对k和v做nn.Conv2d 从而SR
x_ = self.norm(x_)
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) # 再将H和Wreshape为N
else:
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
三、Ablation Study
1.Pyramid Structure

ViT采用patch size为32时,生成的特征图分辨率太低,导致效果不好
ViT采用的patch size过小时会导致显存占用过高
PVT可以在浅层和深层分别处理高分辨率和低分辨率的特征图
2.Deeper vs. Wider

Wider:将PVT-Small中hidden dimensions {C1, C2, C3, C4}扩宽1.4倍
Deeper:增加Transformer中的block数目
3.Computation Overhead
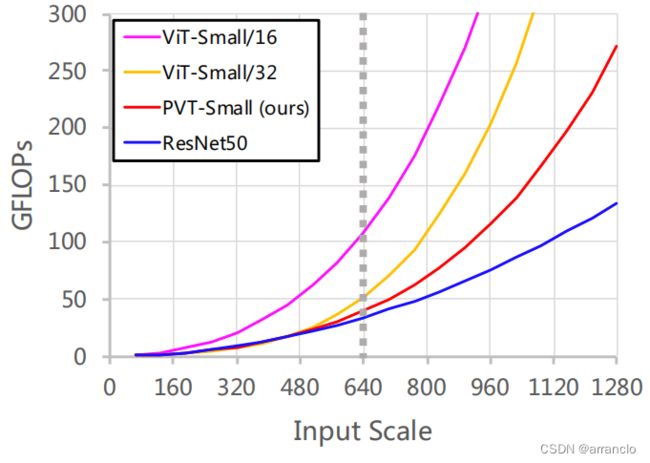
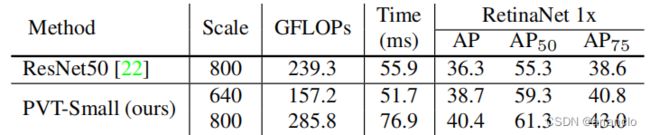
PVT的计算量高于ResNet50,低于PVT-Small