一些单目标跟踪数据集
数据集
1. GOT-10k
《GOT-10k: A Large High-Diversity Benchmark for Generic Object Tracking in the Wild》
Generic Object Tracking Benchmark,提供了一个通用目标跟踪基准,发布于2018年。
网站:GOT-10k: Generic Object Tracking Benchmark (http://got-10k.aitestunion.com/)
完整数据大概有 66 66 66 GB。
部分数据预览(来自官网):
主要一些特点:
(1)提供了大规模数据,适用于短期的、通用类别跟踪器。有 10 , 000 10,000 10,000 段视频,超过 1 , 500 , 000 1,500,000 1,500,000 个手工标注的包围框。一共有 563 563 563 个目标种类, 87 87 87 种运动形式。
(2)测试集由 420 420 420 个视频组成,含有 84 84 84 个目标类别和 31 31 31 个运动类别。训练集 和 测试集 完全没有重叠数据,避免评估结果偏向于熟悉的对象,促进跟踪器泛化能力的开发。
(3)提供了额外的标签,例如运动类型、目标的可见比率、遮挡指示,促进了跟踪器的运动感知和遮挡感知的开发。
(4)作者用了 39 39 39 个典型的跟踪算法及其变体,在 GOT-10k 上进行了分析和实验。进行了广泛的实验来研究数据集不同的方面对于训练深度跟踪器的影响。意思是你可以相信这个数据集。
(5)作者提供了功能齐全的工具包,很容易接入和使用。测试集的标注是没有公开的,跑完之后要把结果提交到它们服务器,避免大家作弊。
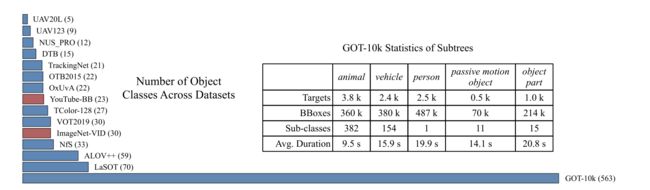
表格里面有 5 5 5 个大类,GOT-10k 的 563 563 563 个目标类别都是从这 5 5 5 个大类扩展来的。
2. TrackingNet
《TrackingNet: A Large-Scale Dataset and Benchmark for Object Tracking in the Wild》
网址:https://tracking-net.org/
2018年发布的数据集。说当时都是一些小的数据集,没办法用于训练深度学习、机器学习的跟踪算法。缺乏大规模的数据集。
共 30 , 643 30,643 30,643 段视频,平均时长 16.6 16.6 16.6s, 14 , 341 , 266 14,341,266 14,341,266 个密集标注框,约 1.14 1.14 1.14 TB。
从 Youtube-BoundingBoxes (YT-BB) 中精心挑选 30 , 132 30,132 30,132 段视频作为训练集。
构建了一个由 511 511 511 段视频组成的新集合作为测试集,其分布与训练集相似。
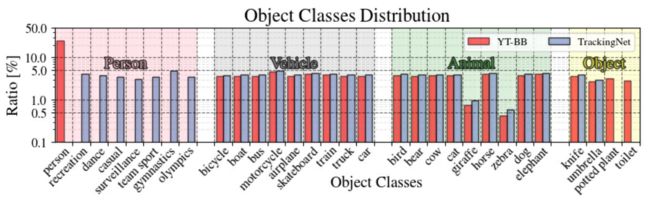
Youtube-BoundingBoxes (YT-BB) 是一个用于目标检测的大规模数据集,包含约380,000个视频片段。这些视频都是直接从YouTube上收集的,在分辨率、帧率和持续时间上有很大的差异。YT-BB包含23个对象类别,其中 person 类占 25 % 25\% 25%,我们把它分成了 7 7 7 个具体类。
为了保证视频的质量,用于跟踪任务,我们基于属性规则过滤掉了 90 % 90\% 90% 的东西。
首先,我们删掉了那些小于 15 15 15 秒的视频。
第二,我们只考虑那些包围框占画面 50 % 50\% 50% 以内的。
第三,保留了那些包围框在合理变化范围内的视频段。
经过过滤后,我们保留了 21 21 21 个目标种类,保留了它们在 YT-BB 中的原始分布,防止数据集存在偏差。最终得到的训练集有 30 , 132 30,132 30,132 段视频,我们把它们分成了 12 12 12 份,每份包含 2 , 511 2,511 2,511 段视频,它们每个里面也维持着 YT-BB 中的原始分布。(意思是你合起来用也行,当做大型数据。分开用也行,数据量小一点,但数据的属性和分布是一样的。)
对于测试数据,提供了 15 15 15 条属性,上面 5 5 5 个是自动提取的,根据分析包围框在一定时间内的变化得到的。下面 10 10 10 个是对数据集的 511 511 511 条视频人工查看分析来手动确认的。

我们能够更好地控制数据集中每个视频的帧数,并且相对于其他数据集具有更大的包容性。们认为这种包含长度多样性更适合于固定批量的训练。
其次,在TrackingNet中,包围框的 分辨率 的分布更加多样化,提供了要跟踪的对象的尺度更加多样化。
对于在 YT-BB 上运动得很快的东西,TrackingNet 展现出更自然的运动分布。而 OTB100 和 VOT17 上的挑战主要就是集中在运动特别大的目标上。
3. LaSOT
《LaSOT: A High-quality Benchmark for Large-scale Single Object Tracking》
Large-scale Single Object Tracking,旨在提供一个专用的平台,为了训练一个需要大量数据的深度跟踪器,也为了评估长期跟踪的性能。
网址:http://vision.cs.stonybrook.edu/~lasot/
第一版有里有 70 70 70 个种类, 1 , 400 1,400 1,400 个视频序列,大概 227 227 227GB 左右。
第二版进行了扩展,额外提供了 15 15 15 个种类, 150 150 150 个视频序列,大约 59 59 59GB 的数据。
2018年左右的数据集。有以下特点:
(1)Large-scale,大规模: 1 , 550 1,550 1,550 个视频序列,超过 3 , 870 , 000 3,870,000 3,870,000 帧图像。
(2)High-quality,高质量:手工标注,每一帧都仔细检擦。
(3)Category balance,类别平衡: 85 85 85 个类别,其中 70 70 70 个每个有二十个序列,其中 15 15 15 个每个有十个序列。无论目标属于哪个类别,都希望跟踪器表现鲁棒,我们包含了不同的目标集合,来自 70 70 70 个类别,每个类别拥有相同数量的视频。
(4)Long-term tracking,长期跟踪: 我们保证每个序列有至少 1 , 000 1,000 1,000 帧,平均视频长度大概 2 , 500 2,500 2,500 帧(例如 30 fps 30\text{fps} 30fps 的视频有 83 83 83 秒)。最短的视频有 1 , 000 1,000 1,000 帧,最长的一个有 11 , 397 11,397 11,397 帧( 378 378 378 秒)。
(5)Comprehensive labeling,详尽的标签:每个序列提供了视觉的语言的标注。
(6)Flexible Evaluation Protocol,灵活的评估协议:在三种不同协议下进行评估:无约束、完全重叠和一次性。
LaSOT 由 70 70 70 种对象类别组成。大多数类别是从 ImageNet 的1000个类中选择的,只有少数例外(例如无人机)是为流行的跟踪应用程序精心选择的。与现有的密集基准不同,这些基准的类别少于 30 30 30 个,而且通常分布不均匀,LaSOT 为每个类别提供相同数量的序列,以缓解潜在的类别偏差。
LaSOT 的每个类别有 20 20 20 种目标,反映了自然场景的类别平衡和多样性。
本数据关注长时间的视频,在这些视频中,目标物体可能会消失,然后再次进入视图。
此外,我们为每个序列提供了自然语言描述。
为了进一步分析跟踪器的性能,我们对每个序列标注了 14 14 14 条属性:
照明变化(illumination variation,IV)
完全遮挡(full occlusion,FOC)
部分遮挡(partial occlusion,POC)
变形(deformation,DEF)
运动模糊(motion blur,MB)
快速运动(fast motion,FM)
尺度变化(scale variation,SV)
相机运动(camera motion,CM)
旋转(rotation,ROT)
背景杂波(background clutter,BC)
低分辨率(low resolution,LR)
视点变化(viewpoint change,VC)
超出视野(out-of-view,OV)
长宽比变化(aspect ratio change,ARC)
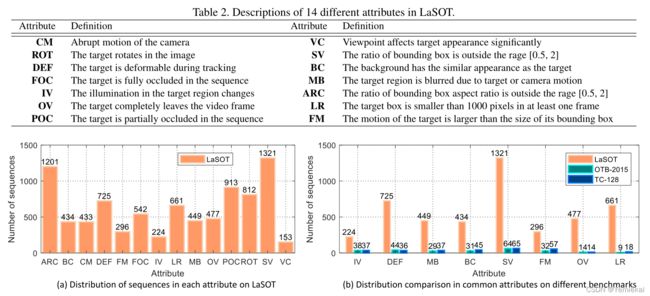
从上图中,我们观察到 LaSOT 中最常见的挑战因素是尺度变化(SV,ARC)、遮挡(POC,FOC)、变形(DEF)、旋转(ROT),这是跟踪器在现实世界的众所周知的挑战。此外,可以看到 LaSOT 有超过 1 , 300 1,300 1,300 条视频涉及尺度变化,有 477 477 477 个序列含有超出视野(OV)的属性,大大高于其他基准数据集。
本数据集提供了两种算法评估协议。
∙ \bullet ∙ 协议 I \text{I} I :用整个 1 , 400 1,400 1,400 个序列来验证跟踪器的性能。研究者可以使用 LaSOT 以外的任何数据来开发跟踪器。
协议 I \text{I} I 旨在提供大规模的评估。
∙ \bullet ∙ 协议 II \text{II} II :我们把 LaSOT 拆分成 training 和 testing 两个子集。根据 80 / 20 80/20 80/20 原则,我们从每个类别的 20 个视频中选择 16 个进行训练,剩下的 4 个用于测试。其中训练集包含 1 , 120 1,120 1,120 个视频, 2 , 830 , 000 2,830,000 2,830,000 帧图片。测试集包含 280 280 280 个序列, 690 , 000 690,000 690,000 帧图片。
协议 II \text{II} II 旨在同时为训练和评估提供大量的视频。
评价方法
参考文章:《Online Object Tracking: A Benchmark》
Yi Wu, Jongwoo Lim, Ming-Hsuan Yang;Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2013, pp. 2411-2418
[下载地址]
论文提供了: (1) precision (精确度) (2) success rate (成功率) 来为单目标跟踪器的性能做定性分析。
另外,还从 2 2 2 个方面来对跟踪算法的鲁棒性进行评估。
∙ \bullet ∙ Precision plot
对于跟踪器的精确度,一个广泛使用的评估指标是中心定位误差(center location error)。
也就是预测框和标签框的中心点之间的(像素)欧式距离。
对每一帧图像都计算中心定位误差,求平均,就得到跟踪器在这段视频上的整体性能。

然而有时候跟丢了目标,预测框的位置是随机的,这样算出来的平均误差不能正确地反映跟踪器的性能。
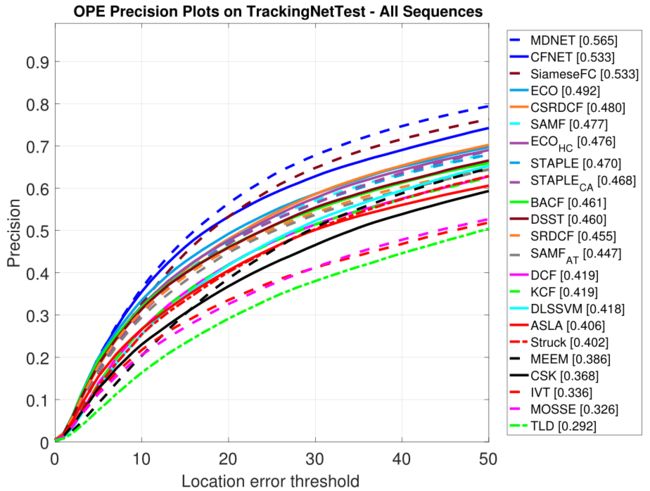
所以我们采用 精度图(precision plot) 来衡量整体跟踪性能。
它反映的是,符合条件的图片的占比,条件是:预测框与真值框的中心点欧式距离小于指定阈值。阈值一般设为 20 20 20 像素。
统计所有阈值下的结果,绘制曲线,大概像这样:
∙ \bullet ∙ Success plot
边界框(bounding box)的重叠度 S S S,也就是计算预测框与真值框的 IOU \textbf{IOU} IOU。 S = ∣ r t ⋂ r a ∣ ∣ r t ⋃ r a ∣ S=\dfrac{| \ r_t \bigcap r_a \ |}{| \ r_t \bigcup r_a \ |} S=∣ rt⋃ra ∣∣ rt⋂ra ∣。
其中 r t r_t rt 是预测框, r a r_a ra 是真值框。 ⋂ \bigcap ⋂ 是相交, ⋃ \bigcup ⋃ 是相并。 ∣ ⋅ ∣ | \; \cdot\; | ∣⋅∣ 表示该区域的像素数量。
我们计算每一个视频序列中,有多少帧的 S S S 大于指定阈值 t o t_o to,把这个占比(成功率)记下来。最后求一个平均。
t o t_o to 每取一次值,都能算出一个占比。 t o t_o to 从 0 0 0 取到 1 1 1,把对应的成功率画成图,大概像这样子:
如果我们在指定的阈值下(例如取 t o = 0.5 t_o=0.5 to=0.5)进行比较,可能不够全面,不具代表性。要把每个 t o t_o to 的结果都比一比。
因此我们常用 AUC \textbf{AUC} AUC(area under curve)对跟踪器进行排名。也就是计算这个成功率曲线下面的面积。
Robustness Evaluation,鲁棒性评估
评价跟踪器的传统方法是,在第一帧的时候用真值框来对目标位置进行初始化,后面的帧从该位置开始跟踪。
跑完整段视频后,报告平均精度(average percision) 或 成功率(success rate)。
我们把这种方法称为一次评估:one-pass evaluation(OPE)。
然而,跟踪器可能对初始化很敏感,在不同的起始帧做不同的初始化,性能会变好或者变坏。
于是我们提出了两种方法来分析跟踪器对于初始化的鲁棒性。
即在时间上(从不同帧开始)和在空间上(从不同的包围框开始)对初始化进行扰动。这些试验分别称为:
时间稳健性评价(temporal robustness evalution,TRE) 和 空间稳健性评价(spatial robustness evalution,SRE)。
∙ \bullet ∙ TRE (Temporal Robustness Evaluation )
时间稳健性评价。
给定初始帧和真值框,用它对跟踪器进行初始化,然后跑到序列的末尾。
可以从视频序列中拿某一段来跑,也可以整个都跑。
评价每一段的跟踪结果,并统计总体数据。
∙ \bullet ∙ SRE (Spatial Robustness Evaluation )
空间稳健性评价。
我们在第一帧对真值框进行平移或者缩放,然后再用来初始化跟踪器。
我们用 4 4 4 种中心点的位移, 4 4 4 种角点的位移, 4 4 4 种尺度变化。
位移量为真值框尺寸的 10 % 10\% 10%,尺度变化是原来的 0.8 0.8 0.8 或 0.9 0.9 0.9 或 1.1 1.1 1.1 或 1.2 1.2 1.2。
所以每个跟踪器评估 12 12 12 次。