转载总结一位哥大博士的经验
文章目录
-
- 一、万事开头难
- 二、方向比努力重要
-
- 2.1 PhD选题
- 2.2 单篇Paper选题
- 三、谈谈Presentation
-
- 3.1 做报告
- 3.2 谈谈写paper
- 四、没那么简单的事
-
- 4.1 Project vs. Paper
- 4.2 new dataset和new task不是low-hanging fruit
- 4.3 没那么难
- 参考
一、万事开头难
- 练习英语口语,首先要敢说,然后多跟不同的人聊天练习
- 让老板知道你在干活:周汇报的时候,不会只提项目A之后我想怎么做,会同时准备一页slide总结下我对B的贡献。
- 自己的感受没那么重要,只要身体扛得住,就可以继续学下去
- 上课没那么重要
二、方向比努力重要
2.1 PhD选题
很多时候光努力不够,方向更重要。新手如何选博士几年的topic,有两个问题值得思考:
能不能快速上手?有几个简单的评判标准:
- state-of-the-art的paper有没有开源的代码?目的是你能迅速复现baseline,熟悉整体pipeline(如怎样预处理,后处理),加深对实现和细节的理解
- 有没有对这个topic有hands-on经验的师兄,或者community里面approachable的前辈?目的是,当你遇到实现上的细节问题,可以及时咨询和得到反馈
- 这个topic有没有比赛,或者标准的benchmark?目的是,有大家已经定义好的数据,实验setup,评价标准;这样,你有可以直接比较的baseline,outperform baseline的时候也容易被人认可
能不能有大的impact?这里我指的是博士期间的大方向,由一系列单项的工作或者paper构成。
单篇paper通常有三种类型:
-
First work:开创了一个topic,比如RCNN于object detection
-
Last work:基本解决了一个topic,比如Faster-RCNN,YoLo于object detection
-
Improve类型,介于First和Last之间的。
-
Last很难,Improve常见但影响力不够深远,对于新手而言,博士的早期工作,在有能力做出来和有impact之间的trade-off比较好的,估计是First了,不一定非要是第一篇,只要是某个topic里面开创性工作的那一批之一,都是不错的。这个早期工作之后,你会对这个问题哪里要改进,有很清楚的认识,因为improvement room大,也会有很多ideas。同样,早期的时候怎么选这样一个topic呢:相关的比赛是这一两年新开的吗,相关的benchmark是这一两年出来的吗,上面的结果提升空间大吗(现在是20%还是已经80%了)?
2.2 单篇Paper选题
具体到每一篇paper,选择的principle和重点则不太一样。来Facebook后从马爷爷那知道了一个著名的Heilmeier问题系列,是指导老师们申项目的,我觉得稍微改改,便很适用于我们考虑,某一篇paper的选题,合不合适:
- What are you trying to do? Articulate your objectives using absolutely no jargon.
- How is it done today, and what are the limits of current practice?
- Who cares? [Support other’s research? Shape research landscape? Power applications in industry?]
- What’s new in your approach and why do you think it will be successful?
- If you’re successful, what difference will it make? [e.g. Contributions in theory/modeling? Improve accuracy by 5% on dataset A, B, C…?]
- What are the risks and the payoffs? [Further, how would you mitigate the risks? If your proposed method does not work, what could be alternative design? These can end up as discussions such as ablation studies in your paper.]
- How much will it cost? [e.g. How many GPUs do your experiments require? How long is each training process? How about data storage?]
- How long will it take? [How many hours are you going to work on this per week? When is the submission DDL? Can you make it?]
- What are the midterm and final “exams” to check for success?
三、谈谈Presentation
Presentation分为做报告,还有就是写paper
3.1 做报告
- 如果可能的话,事先了解你的听众背景,是跟你做同一个topic的,还是同一个大领域但不同topic的,还是完全其他专业背景的。需要根据听众背景,定制和调整:比如,需不需要多介绍些背景?需不需要更深入技术细节?等等
- 一页slide尽可能focus在一个点上,不要信息量过大,否则听众很容易lost
- 尽可能多用图片表达,不要大段大段的列文字,A picture is worth a thousand words
上面这两点,其实principle都是尽量让要讲的内容简单明了,因为很多时候我们在听talk,这样被动接受的时候,接受新知识的能力是比主动接受时候(比如看paper)低的。 - 当听众问问题的时候,If you don’t know the answer, just say don’t know.
- 如果是跟mentor日常讨论的slides,因为会讨论到很细节的东西,有些图PPT画起来,很花时间,而且通常这样细节的图还挺多,所以可以就ipad上面手画一画,截个图放到PPT里就好了;如果是正式一点的presentation,写slides跟写paper的principle有点像,不要太focus在细节上,更重要的是讲清楚motivation,为什么这样设计,细枝末节的不关键的内容,放在backup slides里面。
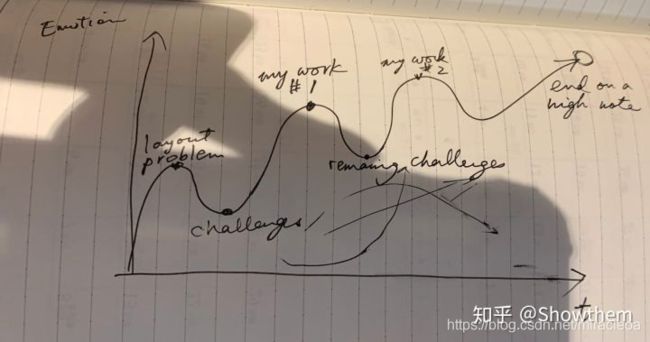
19年CVPR,Doctoral Consortium有幸mentor斯坦福的一位大牛教授,她也提到了presentation的重要性,说她们lab有个开玩笑的说法,一份slides交给她去改,no pixel left……为了分享如何能让报告听起来有兴趣,她画了下面这张图,让听众情感(亦是兴趣高低,注意力程度)随着时间的变化,有三个高潮:首先,介绍你的问题,通常这时候大家都会引发兴趣;但听着听着大家注意力就不集中了,这时候就到了图中第一个低谷,这时候需要指出来这个问题有哪些challenge,大家的兴趣就又被激发了;等大家兴趣来了,精力集中的时候,介绍你的一部分工作work 1;等介绍完第一个工作,大家又疲劳了,这时候指出来,即使有这个work 1,问题还不能被解决,因为有remaining challenge;接着大家又被调动了兴致,可以开始介绍work 2。
3.2 谈谈写paper
在2.2里面讲了对某一篇paper,如何选题和做规划。那真的到了写paper的时候,我自己有几点如何让文章写的更好的体会:
-
先给一个Talk。 写paper最难的是构思storyline,而最好的完成这一步的方法就是先对你的工作做一个slides,给周围的人present一遍。这个过程中,你会梳理好自己的思路,画好文中的figure,准备好实验结果的table,周围的人还可以给你提意见,帮助你完善,等这个talk给完了,后面写paper就会顺畅自然了。其实我现在,如果准备投一个paper,当做了一段时间后,就会按照最终presentation的思路,准备slides,用在每周给老板们report时。开头先快速review一下做的task和提出的方法,remind一下context,然后重点focus在那周做的新东西上,所以每周汇报的slides可能80%都是跟上一周一样的,然后新的方法和实验结果的那几页slides是新的,有比较多的细节。
-
用Google doc做语法检查。 刚写好的paper有typo和语法错误是很难避免的,但常常会被reviewer揪着不放。大家写paper如今大都在overleaf上,但overleaf的查错还是不够好,建议可以写完paper后,贴到Google doc里面。几年前开始,估计是由于deep learning对Google NLP的改进很大,感觉Google自动改的质量已经非常高了。
-
Rationale很重要。 不光是要讲清楚你怎么做的,更要justify你问什么这么做;不光要讲你的结果比baseline好,更要解释为什么好;读者看到的不应是一个“使用手册”。有时候我们写paper,花了很多篇幅写了很多实现细节,但是更重要的是,解释“为什么”,这个背后的逻辑和insights。
-
大部分paper都是提出一个新的方法,这类方法型paper似乎都可以套下面这个框架:
- Introduction:可以分为以下几个部分:
- Problem definition
- Previous methods and their limits
- 简单描述你是提出了什么技术来overcome上面的limits
一个图,非常high-level的解释前人工作的limits和你的工作怎么解决了这些limits,最好让人30秒内完全看懂 - 最后一段如今大都是,In summary, this paper makes three contributions:
- First work to解决什么limits
- 提出了什么novel的技术
- outperform了state-of-the-art多少
- Related Work:一般三五个subsection,分别review下相关的topics,同样不光讲previous work做了啥,更要讲自己的方法跟前人工作有啥不同
- Introduction:可以分为以下几个部分:
-
Method
- 这是文章的主体,按照你觉得最容易让别人看懂的方式来讲
- 可以第一个subsection是overview,formulate一下你的problem给出notation,配一个整体framework的图,图里面的字体不能太大或者太小看不清,要有些细节,让人光看图就能明白你的方法是怎么回事,但不要过于复杂,让人在不超过2分钟的时间看完这张图
- 然后几个subsection具体介绍你的方法或者模型;如果testing跟training不太一样,最后一个subsection介绍inference时候的不同,通常是一些post-processing操作
-
Experiment
- Datasets
- Implementation details such as pre-processing process, training recipe
- Evaluation metrics
- Comparisons with state-of-the-art
- Detailed analysis
- Alternative design choice exploration
- Ablation studies
- Visualization examples
-
Conclusion (and Future Work)
-
Abstract:是全文的精简版,建议在paper写完第一稿差不多成型了,有定下来的成熟的storyline了,再去写abstract;大概就是用一两句话分别概括paper里面每个section,然后串起来
另外paper提交时候,可以交supplementary materials,虽然reviewer并不被要求强制看这个,但其实给我们机会,去include更多文章技术细节、实验结果的好地方;在后面rebuttal阶段,通常篇幅有限制,但如果你已经在supp里面未雨绸缪,可以省很多空间,refer reviewer去看你supp里面的内容就好了。
插上另一位作者 熊风 的rebuttal经验
我这次投的ICCV,给weak reject的那个reviewer就是这种情况。提的一些问题根本不在点上,基本没有评论我的方法本身,净挑一些dataset, evaluation metrics的问题,尽管我们用的dataset, evaluation metrics是大家普遍都在用的。这个reviewer到最后也没修改意见,还是给了weak reject.但其他两个给borderline的reviewer,提的一些问题就靠谱了很多。有的确实是我们论文的问题。而且从一些话里也可以感受到他们的态度也是摇摆不定的,比如“some issues in the paper should be fixed before being fully accepted”. 遇到这种情况,就要果断争取。我们rebuttal主要就是尽可能地把这两个reviewer的concerns解释清楚。最后这两个reviewer也修改了意见。如果是论文没写好,比如遗漏了一些关键细节。大方承认,并且在rebuttal里面把这些细节展现出来,承诺在论文之后的版本会加上。如果是reviewer对你的论文理解有问题,那就在rebuttal里面更加详细地解释。如果确实指出了自己模型/实验的一些瑕疵,可以强调自己论文的亮点和contribution. 比如有个reviewer说"the proposed method cannot beat other state of the arts", 我们可以强调我们并没有像其他论文那样用ensemble的方法来提升performance,我们的focus是XXX. 比起performance的一些细微提升,XXX更重要。
四、没那么简单的事
4.1 Project vs. Paper
刚入学时,我单纯的觉得,好好做research就好了;但事实上,能够专心做research的时间其实是没有想象的那么多的,是要挤出来的,甚至去开会回来,报销填表准备材料这种杂事,小事,都得折腾掉好几个小时……
但更tricky的是平衡project和paper之间的关系。如果你比较幸运,有国家的Fellowship/Scholarship,或者系里的Fellowship/Scholarship(有的是以TA的形式),不用做所谓的RA,再或者sponsor你的project是纯以发paper为KPI的,而且并不care你做的是什么topic,那你可能没有这方面的苦恼。
但是,通常老师们申请grant,很多grant,尤其是金额大的project,通常甲方心里都有一个确定的想解决的问题,向老师征求proposal,即问题的解决方案,proposal里面会规划好每个半年甚至每个季度做什么task。当然,这里说的project不包括那种纯粹是给外面公司做工程的project,倒还都是research project。经常项目开始的时候,因为proposal是以前定好的,如今环境、state-of-the-art都不一样了,跟当下情况不符;或者甲方想解决的问题比较practical,是个没有formulate好的research problem,或者不是community关心的偏基础的research task。
举个例子,你想做的topic是object detection,community关心的dataset是VOC,COCO,但你的甲方关心的可能是某个领域的object detection,比如detect某种野生动物,比如detect不同微生物。经常遇到的是,你提出的方法在VOC,COCO上面很work,但在微生物的dataset上面效果不佳,这样虽然可以发paper,但是project却没有进展。有些项目,在开始的时候会fund好几个team,然后让大家比赛,比如在项目内部有个detect微生物的benchmark,让你们PK,第一年结束,淘汰掉最差的那个team,第二年继续PK,再末端淘汰。你要是project没有进展,导致你导师的项目被砍了,就问你怕不怕……因此,很多同学就走了另一个极端,花很多精力做项目,hack这些project的上的number,很多时候涨点最快的方法是,collect更好的training data,用更复杂的网络,渐渐变成了解决工程问题,开发了个很牛的系统,但是没有novelty发paper。
这种情况下,人的本性,会觉得麻烦,就偏颇一方。但这其实是偷懒,千万不可。要align双方的兴趣,要注意平衡,trade-off,一方面要project有进展,对sponsor负责,另一方面更要对自己负责,发paper做有impact的工作。 比如,尽量focus在模型本身,找到有novelty,在project benchmark和学术界standard benchmark上效果都好的方法。以及,通常一个project开始的时候有很多engineering的活儿,可以暂时放一放纯paper research,等system搭起来了,后面就是不断improve核心算法,这个时候精力更多放在paper这边。
拿我自己举例子,15年底,我开始take charge of一个新的项目,于是16年上半年,基本都在为这个项目搭初步的system,从前端网站到后台数据库,从设备采购到system infra,从object detection到multi-modal;等系统差不多搭起来了,我在项目工程上就可以花很少的时间,也有progress去每月report,于是16年下半年,基本在做paper,当然topic做的技术是将来能improve项目system一个核心模块的;到了17年上半年,系统要开发新的模块,又是花了三个月在项目工程上;再之后直到博士毕业,都是尽量找到common interest,一个新的模型,对project的system效果有帮助,亦有大的paper research价值。
4.2 new dataset和new task不是low-hanging fruit
刚读博时候,受周围人影响,很多人都说release一个新的dataset没有什么技术含量,轻轻松松发paper还能赚一票引用,是个low-hanging fruit。但当我参与到一个新的dataset的创建过程后,才发现这是一个非常tedious的工作,有很多的脏活累活,很多细节的地方需要考虑。之前v1版本data,可能因为一个细节没考虑好,需要重新collect或者annotate,费时又费钱,经常要迭代好几个版本。所以create new dataset一点也不简单,可能比提出一种新方法的paper,花的时间还要长。
同样,以前以为提出一个新的task(所谓挖坑)是个low-hanging fruit,但真正做过之后才知道,也没那么容易的。17年底,导师让我做live detection,也就是,只根据过去和当下,监测当下发生了什么事件。我发现之前的工作都没有很好地evaluate这个问题,formulation上有问题,实际做的是per-frame labeling或者early classification,于是决定提出一个新的task,专门evaluate detection本身。投完paper信誓满满,结果被CVPR拒了。reviewer们一方面指出了一个我之前忽略的点,另一方面指出对于有的application,per-frame就可以够用,不能直接说per-frame用来detection有问题,而仅仅是对于有的应用场景,per-frame用来detection有问题。为此,要大改paper的定位。过程是痛苦的,但正因这个痛苦让工作更加完善,我们才能成长升华,最后这个工作重投ECCV被大家认可了。
对于new dataset或者new task的工作,怎么样才能做的尽量完善,减少迭代次数呢?我的一个经验是,这种项目,尽可能involve多的experienced experts参与讨论,及时跟大家沟通,collect不同人的想法。 每个人看问题角度不同,放在一起就会比较完善,群众的智慧是大智慧。
4.3 没那么难
说了没那么简单的事,再说说没那么难的事。
万事开头难,难在迈出第一步。当开始做survey入门时,发现这么多文献要看,会觉得难;当想好idea准备去实现,发现要准备data,要实现的东西一步又一步,会觉得难;当开始写paper,构思完每个section,发现这么多内容要写,会觉得难……
但实际上,当我们一点一点去完成的时候,会发现完成的速度远比我们想象的快,文献一个星期可以看完经典从而入门,paper一个星期可以有个初稿,idea实现起来一个星期可以coding完,甚至跑出实验结果……其实没那么难,就是耐下性子,脚踏实地,干就完了。
参考
原文链接