Layout系列模型(LayoutLM,LayoutLMv2,LayoutXLM)
LAYOUT LM
联合建模文档的layout信息和text信息,预训练文档理解模型。
模型架构
使用BERT作为backbone,加入2-D绝对位置信息,图像信息,分别捕获token在文档中的相对位置以及字体、文字方向、颜色等视觉信息。

2D位置嵌入
文档页面视为坐标系统(左上为原点), 使用2张embedding table构造4种位置嵌入,横纵轴各使用1张嵌入表;
图像嵌入
将文档页面图像分割成小图片序列,基于Faster R-CNN建模整张图片特征丰富[CLS]token表征;
预训练数据集及任务
预训练集 IIT-CDIP Test Collection 1.0(600万扫描件,含1200万扫描图片,含信件、邮件、表单、发票等)。
- MVLM, Masker Visual-Language Model: 随机掩盖输入tokens,保留2-D信息,预测被掩盖token分布;
- MDC, Multi-label Document Classification: 监督预训练多标签文档分类,促使模型聚类不同文档特征,增强文档级特征表示;
模型预训练细节
- 除2-D positional embeddings之外,其余参数使用bert base初始化;
- 预测15%的token,选其中80%替换为
[MASK],10%随机替换,余下10%不变; - 标准化所有坐标点为0~1000;
- 使用ResNet-101作为Fatser R-CNN的backbone;
源码解析
9种embeddings相加,再经layer norm后作为第1层输入:
embeddings = (
words_embeddings
+ position_embeddings
+ left_position_embeddings
+ upper_position_embeddings
+ right_position_embeddings
+ lower_position_embeddings
+ h_position_embeddings
+ w_position_embeddings
+ token_type_embeddings
)
余下结构与BERT一致。
LAYOUT LM V2
与Layout LM的区别:
- 预训练阶段,使用Transformer建模文本、布局、图像多模态信息,而Layout LM是在微调阶段利用图像信息;
- 使用空间相对注意力机制,表征token对,而Layout LM使用绝对2-D位置;
- 新增引入文本、图像对齐策略,文本、图像匹配策略,学习文本与图像是否相关;
模型架构
以文本、布局、图像作为输入,建模交叉模态:

文本嵌入
与BERT一致,
t i = TokEmb ( w i ) + PosEmb1D ( i ) + SegEmb ( s i ) \bm t_i=\text{TokEmb}(w_i) + \text{PosEmb1D}(i) + \text{SegEmb}(s_i) ti=TokEmb(wi)+PosEmb1D(i)+SegEmb(si)
视觉嵌入
将图像缩放至224x224,喂入ResNeXt-FPN编码(参数在预训练时更新),平均池化为 W × H W×H W×H的特征图(3维),展开为2维序列;
v i = Proj ( VisTokEmb ( I ) i ) + PosEmb1D ( i ) + SegEmb ( [ C ] ) , 0 ≤ i ≤ W H = L \bm v_i=\text{Proj}(\text{VisTokEmb}(I)_i) + \text{PosEmb1D}(i) + \text{SegEmb}([\text{C}]),\quad 0\leq i \leq WH=L vi=Proj(VisTokEmb(I)i)+PosEmb1D(i)+SegEmb([C]),0≤i≤WH=L
版面嵌入
标准化点位至 [ 0 , 10000 ] [0, 10000] [0,10000], x , y x, y x,y点位各使用一个嵌入层,对于边界框 box i = ( x m i n , x m a x , y m i n , y m a x , w , h ) \text{box}_i=(x_{min},x_{max},y_{min},y_{max},w,h) boxi=(xmin,xmax,ymin,ymax,w,h),
l i = Concat ( PosEmb2D x ( x m i n , x m a x , w ) , PosEmb2D y ( y m i n , y m a x , h ) ) \bm l_i=\text{Concat}(\text{PosEmb2D}_x(x_{min},x_{max},w),\text{PosEmb2D}_y(y_{min},y_{max},h)) li=Concat(PosEmb2Dx(xmin,xmax,w),PosEmb2Dy(ymin,ymax,h))
使用 box PAD = ( 0 , 0 , 0 , 0 , 0 , 0 ) \text{box}_\text{PAD}=(0,0,0,0,0,0) boxPAD=(0,0,0,0,0,0),表示特殊token[CLS]、[SEP]和[PAD]。
空间感知多模态编码器
拼接视觉嵌入和文本嵌入,并加上版面嵌入,生成第一层输入
x i ( 0 ) = X i + l i , X = { v 0 , . . . , v W H − 1 , t 0 , . . . , t L − 1 } \bm x_i^{(0)}=X_i+\bm l_i,\quad X=\{\bm v_0,...,\bm v_{WH-1}, \bm t_0, ...,\bm t_{L-1}\} xi(0)=Xi+li,X={v0,...,vWH−1,t0,...,tL−1}
第一层输入只考虑到绝对位置,为建模版面局部不变性,引入空间感知相对注意力,
α i j = 1 d h e a d ( x i W Q ) ( x j W K ) ⊤ , α i , j ′ = α i j + b j − i 1 D + b x j − x i 2 D x + b y j − y i 2 D y , h i = ∑ j exp α i j ′ ∑ k exp α i k ′ x j W V \alpha_{ij}=\frac{1}{\sqrt{d_{head}}}(\bm x_i\bm W^Q)(\bm x_j\bm W^K)^{\top},\quad \alpha_{i,j}'=\alpha_{ij}+\bm b_{j-i}^{1D}+\bm b_{x_j-x_i}^{2D_x}+\bm b_{y_j-y_i}^{2D_y}, \quad \bm h_i=\sum_j\frac{\exp\alpha_{ij}'}{\sum_k\exp\alpha_{ik}'}\bm x_j\bm W^V αij=dhead1(xiWQ)(xjWK)⊤,αi,j′=αij+bj−i1D+bxj−xi2Dx+byj−yi2Dy,hi=j∑∑kexpαik′expαij′xjWV
预训练任务
数据集与LayoutLM使用的一致
- MVLM, Masker Visual-Language Model: 随机一些掩盖文本tokens,促使模型利用版面信息对其复原,为避免模型利用视觉线索,掩盖tokens对应的图像区域也应该掩盖;
- TIA, Text-Image Alignment: 随机选择一些文本行,覆盖对应的图像区域,使模型预测token对应的图像区域是否被掩盖,即
[Covered]或[Not Covered],促使模型学习边界框坐标与图像之间的关系; - TIM, Text-Image Matching: 粗粒度的模态对齐任务,预测文本和图像的来源是否一致(当前文本是否来自于当前图像)。通用随机替换或删除图像构造负样本,负样本对应TIA任务的所有标签均为
[Covered]
TIA任务为什么要整行覆盖?
文档中某些元素(signs, bars)看起来很像是覆盖区域,图像中寻找词级别的覆盖区域噪音较大,整行覆盖可避免噪音。
实验细节
- 使用UniLMv2模型初始化网络参数;
- ResNeXt-FPN的backbone: MaskRCNN,基于PubLayNet训练;
- 使用随机滑窗的方法随机截取长文本中的512个token;
- 视觉编码器平局池化层输出维度W×H=7×7,即总共有49个视觉token;
- MVLM,token mask的概率及方式与LayoutLM一致;
- TIA,15%替换图像;
- TIM,15%替换图像,5%删除图像;
LayoutXLM
文章简介
- 作为LayoutLMv2的扩展,适用于多语言任务;
- 与LayoutLMv2架构相同,参数基于SOTA多语言模型
InfoXLM初始化参数; - 使用IIT-CDIP数据集和开源多语言PDF文件作为数据集;
- 开源多语言(中文、日文、西班牙语、意大利语、德语)信息抽取数据集XFUND
不使用LayoutLMv2初始化参数的原因?
LayoutLMv2不覆盖多语言,词典不一致。
模型架构
与LayoutLMv2一致。
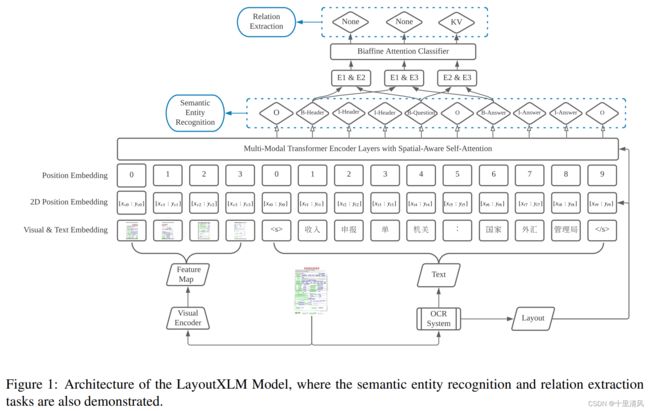
模型预训练
使用与LayoutLMv2一致的三个任务:MVLM、TIA、TIM。
预训练数据
- 含53种语言文件;
- 使用PyMuPDF解析、清洗数据集,获取页面文字、布局、图像;
- 使用BlingFire检测文件语言;
- 以 ( n l / n ) α (n_l/n)^\alpha (nl/n)α概率采样某一种语言文件, α = 0.7 \alpha=0.7 α=0.7,共获得2200w富文档;

XFUND: 多语言票据理解基准数据集
扩充FUNSD至7种语言。

任务描述
语义实体识别任务, 关系抽取任务。
| Semantic Entity Recognition | Relation Extraction |
 |
 |
Baselines
Semantic Entity Recognition
基于BIO标注模式,构建特定任务层建模LayoutXLM的文本部分。
Relation Extraction
识别所有关系候选实体,对任一实体对,拼接头尾实体第一个token的语义向量,经投影变换、双仿射层,获得关系分类。
实验
- 预训练base和large模型;
- 微调XFUND,验证不同语言迁移学习、零样本学习、多任务微调,并与两种多语言预训练模型(XLM-R、InfoXLM)作对比;
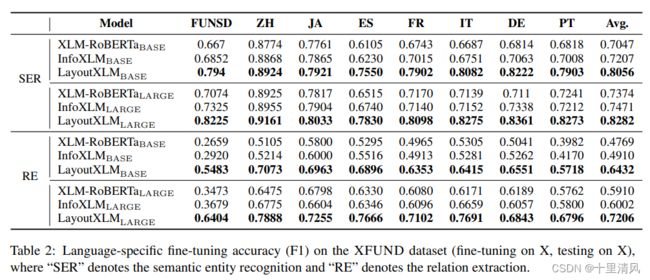
1️⃣language-specific fine-tuning: 语言X上微调,语言X上测试;
2️⃣Zero-shot transfer learning: 英文上微调,其他语言上测试;
3️⃣Multitask fine-tuning: 所有语言上训练模型
特定语言微调
零样本微调

多任务微调

LAYOUTLMV3: Pre-training for Document AI with Unified Text and Image Masking
现有方法
- DocFormer: 通过CNN解码器学习重建图像像素,任务倾向于学习噪声细节,而不是学习文档布局这种高层级特征;
- SelfDoc: 回归掩盖的区域特征,任务噪声大,相比于小词表的离散特征分类任务更难;
The different granularities of image (e.g., dense image pixels or contiguous region features) and text (i.e., discrete tokens) objectives further add difficulty to cross-modal alignment learning.

LAYOUTLMV3特点
- 不依赖于预训练的CNN或者Faster R-CNN提取视觉特征,降低了网络参数和区域监督标注;
- 实用MLM、MIM任务降低了文本和视觉模态特征差异,使用WPA任务对齐交叉模态;
- 可同时应用到文本(MLM任务)和图像任务(MIM任务)的通用预训练模型;
LayouLMv3 is pre-trained with a word-patch alignment objective to learn cross-modal alignment by predicting whether the corresponding image patch of a text word is masked.
https://blog.csdn.net/sinat_34072381/article/details/106993856
模型架构

Text Embeddings
- word embeddings: from a pre-trained model RoBERTa.
- position embeddings:
- 1D position: the index of tokens within the text sequence.
- 2D position: the bounding box cordinates of the text sequence (like LayouLM, using x-axis, y-axis, width and height), but adopt segment-level layout positions that words in a segment share the same 2D-position since the words usually express the same semantic meaning.
Image Embedding
Represent document images with linear projection features of image patches, as following steps:
- resize image to H × W H\times W H×W and denote image with I ∈ R C × H × W \pmb I\in \R^{C\times H \times W} III∈RC×H×W
- split image to a sequence of uniform P × P P\times P P×P patches
- linear project the patches to D D D dimensions and flatten them into a sequence of vectors, which length is M = H W / P 2 M=HW/P^2 M=HW/P2
- add standard learnable 1D position embeddings to eatch patch.
We insert semantic 1D relative position and spatial 2D relative position as bias term in self-attention networds for text and imga modalities following LayoutLMv2.
预训练任务
LayoutLMv3 learns to reconstruct masked word tokens of the text modality and symmetrically reconstruct masked patch tokens of the image modality.
I. Masked Language Modeling (MLM)
Inspired BERT, mask 30% of text tokens with a span masking strategy with span lengths drawn from a Possion distribution ( λ = 3 \lambda=3 λ=3).
利用布局信息和掩盖的文本、图像上下文序列,预测被掩盖的token,从而建模布局、文本、图像模态之间的相关性。
II. Maksed Image Modeling (MIM)
Making 40% of image tokens randomly with blockwise masking strategy that is a symmetry to the MLM objective.
MIM objective can transform dense image pixels into discrete tokens according to a visual vocabulary, that facilitates learning high-level layout structures rather than low-level noisy details.
引理 Image Tokenizer
基于discrete VAE训练,含固定图像词表,将图像转换为定长的离散tokens序列。
image tokens by discrete VAE (DALL-E、BEiT)
III. Word-Patch Alignment (WPA)
The WPA objective is to predict whether the corresponding image patch of a text word is masked.
具体地,对于未掩盖文本token,若其对应的image patch被掩盖,则标签为1,否则标签为0,不考虑掩盖文本token.