编译原理之词法分析器随笔和简单实现
借鉴: 编译原理之美. 极客时间上
什么是词法分析
编译原理:词法分析简单的来说就是在字符串中提取一系列的word单词. 编译器的眼里, 我们的一切输入都是什么? 都是一个一个的字符串. 所以编译器干的就是字符串解析工作.
词法分析:自然就是解析出来一个一个的单词的. word单词
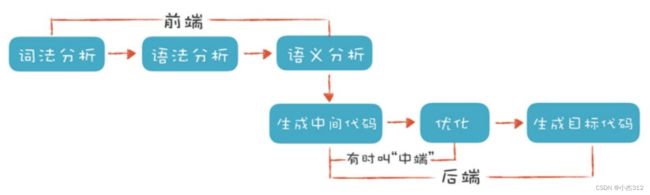
如何做词法分析
首先:明确的第一点, 单词(词法记号)是存在类型的. 解析出来的单词是不同的类型, 我们后序将其标记为Token结构体:{text + type(代码中用的status)}两个字段. 一个是单词内容, 另外一个就是单词类型. 类型赋予不同的分类. 不同的状态。
思考一下: Parse("ab2 345 34.56 87. 3ab 45.0 098 4 6."); 这样一个字符串解析操作
先看词法分析规矩:

ab2 345 34.56 87. 3ab 45.0 098 4 6.
ab2 合法, 是标识符类型. identifier.
345 合法, 是整数类型.
34.56 合法, 是实数类型
3ab 这种, 不合法, 是错误类型 (错误状态, 标记)

针对上述的这些不同的类型, 状态,一般都是用枚举类型来枚举一下不同的状态的
然后接下来:就是把握状态迁移的时机了. 状态是如何迁移的, 以及什么时候应该进行状态迁移, 这些都是我们需要关心的问题.
思考状态迁移的时机:当一个单词分析完成的时候。需要解析下一个单词了, 状态可能需要迁移. 相同状态就一直循环提取,直到这个单词提取完成,再从初始状态继续提取下一个单词.
INIT初始状态,就是为了做一个缓冲状态, 中间状态. 标记的新的单词提取的开始. 新的词法记号提取的开始.
画出来一个状态迁移的图:
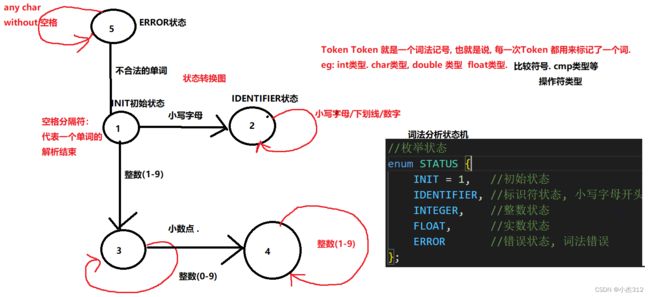
其实上述这个规则,那是相当的简单, 随便一说,大家都能懂是啥意思,哎呀,就是说,按照一定的不同类型的数据的限制规则来提取出合法不合法的单词, 提取完全之后,单词只是一个字符串,不具备一个特殊的含义, 所以我们需要为其添加类型,让其区别含义. 于是我们就加上一个status状态字段, 或者说是Type类型字段也OK
接下来看代码
前置数据声明: tokens用来保存我们解析字符串过程中提取出来的诸多的token词法标记. STATUS标记的是当前单词的提取状态, 也可以说是类型。
#include
#include
#include
#include
#include
#include
#include
#include
using namespace std;
//枚举状态
enum STATUS {
INIT = 1, //初始状态
IDENTIFIER, //标识符状态, 小写字母开头 + 后序小写字母||下划线
INTEGER, //整数状态
FLOAT, //实数状态
ERROR //错误状态, 词法错误
};
//Token:表示的是词法记号
struct Token {
string text;
STATUS status;
};
vector> tokens;//保存所有的词法记号
InitToken: 创建Token, 按照单词的首字母,确定单词的Type类型(STATUS状态)
//根据词法记号首个字符来初始化Token
Token* InitToken(char ch) {
Token* token = new Token;
assert(token != NULL);
if ((isalpha(ch) && islower(ch)) || ch == '_') {//是小写字母开头||下划线
token->status = IDENTIFIER;
} else if (isdigit(ch) && ch != '0') {
token->status = INTEGER;
} else if (ch == '.') {
token->status = FLOAT;
} else {
token->status = ERROR;
}
token->text = "";//初始化为空字符串
token->text += ch;//加上初始字符串
}然后就是Parse函数了, 用于解析字符串,初始化以及提取Token操作,时间紧张,没有做内存管理, 有心之人可以对内存资源加上智能指针, 培养习惯
首先: 提取每一个单词过程中,遇到空格, 表示这个单词提取完成,应该接着提取下一个单词, 所以修改一下当前状态status为INIT状态. 让其自动转换为INIT来完成新的Token的创建. 进入下一个新的单词的解析. 自动进入,核心关键在于自动进入。我们只是需要修改当前的status状态就能自动进入新的下一个单词状态的处理,所以这个玩也也叫做自动机。
在计算机网络的协议封装中,也存在这样类似的状态机。自动的进行状态转移. 连接建立状态, 数据交互状态,连接断开状态. 所以对于这个自动机(状态机的深入理解)是有一定必要的,所以我才写了这篇博客
void Parse(const string& s) {
int i = 0;
char ch = s[i];
STATUS status = INIT;//枚举当前状态
Token* token = nullptr;//记录token
while (ch) {
switch(status) {
case INIT: {//初始化状态, 创建ch即可
while (isspace(ch)) {
ch = s[++i];//跳过多余的空格
}
token = InitToken(ch);
status = token->status;//更新status
ch = s[++i];//更新ch
} break;
case IDENTIFIER: {
if ((isalpha(ch)&&islower(ch)) || (ch == '_') || isdigit(ch)) {
token->text += ch;
ch = s[++i];
} else {
if (ch == ' ') {
status = INIT;//是新的单词
tokens.push_back(shared_ptr(token));
} else {//词法错误
token->status = ERROR;
token->text += ch;
ch = s[++i];
}
}
} break;
case INTEGER: {
if (isdigit(ch)) {
token->text += ch;
ch = s[++i];//更新ch
} else {//结束或者跳跃到实数
if (ch == '.') {
token->status = FLOAT;
token->text += ch;
ch = s[++i];//更新ch
} else if (ch == ' ') {//是新的单词
status = INIT;
tokens.push_back(shared_ptr(token));
} else {//词法错误
token->status = ERROR;
token->text += ch;
ch = s[++i];
}
}
} break;
case FLOAT: {
if (isdigit(ch) && ch != '0') {
token->text += ch;
ch = s[++i];
} else if (ch == ' ') {//是新的单词
status = INIT;
tokens.push_back(shared_ptr(token));
} else {//词法错误
token->status = ERROR;
token->text += ch;
ch = s[++i];
}
} break;
case ERROR: {
if (ch == ' ') {//是新的单词
status = INIT;
tokens.push_back(shared_ptr(token));
} else {
token->text += ch;
ch = s[++i];
}
} break;
}
}
if (token != nullptr)
tokens.push_back(shared_ptr(token));
}
- 感谢兄弟们的阅读,要是对某些开设这门课的兄弟有所帮助。 希望来电收藏点赞,以资鼓励小杰创作,蟹蟹