第四章 Pandas 统计分析基础
第四章 Pandas 统计分析基础
-
Pandas(Python Data Analysis Library)是基于NumPy的数据分析模块,它提供了大量标准数据模型和高效操作大型数据集所需的工具。
-
可以说Pandas是使得Python能够成为高效且强大的数据分析环境的重要因素之一。
-
导入方式:import pandas as pd
4.1 Panndas 中的数据结构
Pandas 有三种数据结构: Series 、 DataFrame 和 Panel 。 Series 类似于一维数组;DataFrame是类似表格的二维数组;Panel可以视为Excel的多表单Sheet。
4.1.1 Series
Series 是一种一维数组对象,包含了一个值序列,并且包含了数据标签,称为索引(index),可通过索引来访问数组中的数据。
1)Series的创建
模板:
pd.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
import pandas as pd
obj = pd.Series([1, -2, 3, -4])
print(obj)
【例4-1】通过列表创建Series

【例4-2】创建Series时指定索引

尽管创建Series指定了index参数,实际Pandas还是有隐藏的index位置信息的。所以Series有两套描述某条数据的手段:位置和标签
【例4-3】Series位置和标签的使用
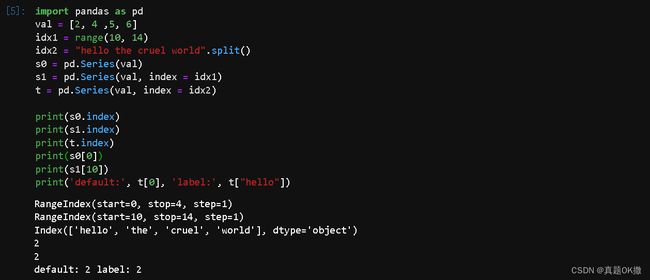
import pandas as pd
val = [2, 4 ,5, 6]
idx1 = range(10, 14)
idx2 = "hello the cruel world".split()
s0 = pd.Series(val)
s1 = pd.Series(val, index = idx1)
t = pd.Series(val, index = idx2)
print(s0.index)
print(s1.index)
print(t.index)
print(s0[0])
print(s1[10])
print('default:', t[0], 'label:', t["hello"])
2)通过字典创建
如果数据被存放在一个Python字典中,也可以直接通过这个字典来创建Series。
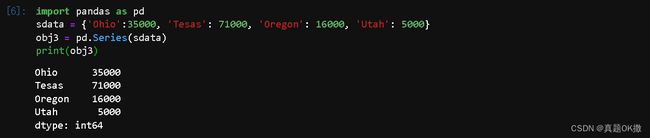
import pandas as pd
sdata = {'Ohio':35000, 'Tesas': 71000, 'Oregon': 16000, 'Utah': 5000}
obj3 = pd.Series(sdata)
print(obj3)
如果只传入一个字典,则结果 Series 中的索引就是原字典的键(有序排列)。
【例4-6】键值和指定的索引不匹配
import pandas as pd
sdata = {"a": 100, "b": 200, "e": 300}
letter = ["a", "b", "c", "e"]
obj = pd.Series(sdata, index = letter)
print(obj)

对于许多应用而言,Series域重要的一个功能是:它在算术运算中会自动对齐不同索引的数据。
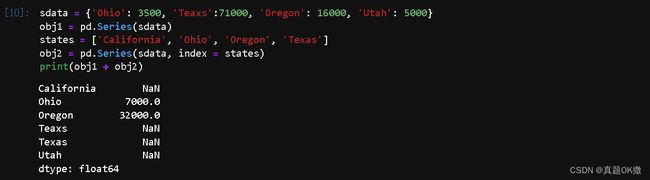
【例4-7】不同索引数据的自动对齐
sdata = {'Ohio': 3500, 'Teaxs':71000, 'Oregon': 16000, 'Utah': 5000}
obj1 = pd.Series(sdata)
states = ['California', 'Ohio', 'Oregon', 'Texas']
obj2 = pd.Series(sdata, index = states)
print(obj1 + obj2)
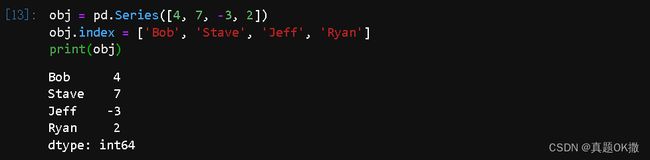
【例4-8】Series索引的修改
obj = pd.Series([4,7,-3,2])
obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan']
print(obj)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wCXSimK9-1665241602155)(D:\文件\大三上\python数据分析与可视化\chapter04\【例4-8】Series索引的修改.png)]
4.1.2 DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。
DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共用同一个索引)。
1)DataFrame的创建
格式:pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
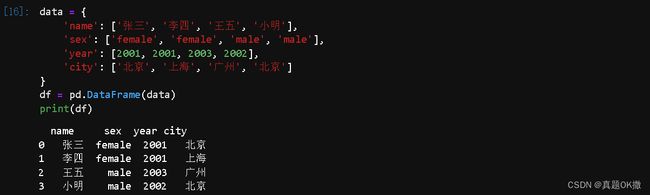
data = {
'name': ['张三', '李四', '王五', '小明'],
'sex': ['female', 'female', 'male', 'male'],
'year': [2001, 2001, 2003, 2002],
'city': ['北京', '上海', '广州', '北京']
}
df = pd.DataFrame(data)
print(df)
【例4-10】DataFrame的索引
df1 = pd.DataFrame(data, columns = ['name', 'year', 'sex', 'city'])
print(df1)

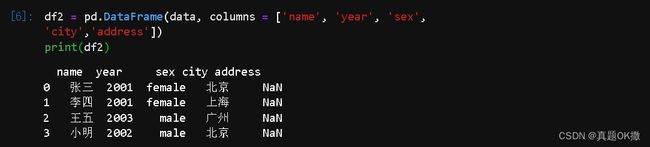
【例4-11】DataFrame创建时的空缺值
df2 = pd.DataFrame(data, columns = ['name', 'year', 'sex',
'city','address'])
print(df2)
【例4-12】DataFrame创建时指定列名
df3 = pd.DataFrame(data, columns = ['name', 'sex', 'year', 'city'], index = ['a', 'b', 'c', 'd'])
print(df3)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-flGJwAyD-1665241602158)(D:\文件\大三上\python数据分析与可视化\chapter04\【例4-12】DataFrame创建时指定列名.png)]

2)DataFrame的属性

4.1.3 索引对象
Pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等)。构建Series或 DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个Index。
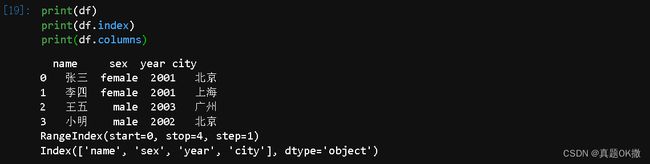
【例4-13】显示DataFrame的索引和列。
print(df)
print(df.index)
print(df.columns)
【例4-14】DataFrame的 index。
print('name' in df.columns)
print('in' in df.index)

每个索引都有一些方法和属性,它们可用于设置逻辑并回答有关该索引所包含的数据的常见问题。Index的常用方法和属性见表4-1。
| 方法 | 说明 |
|---|---|
| append | 连接另一个Index对象,产生一个新的Index |
| diff | 计算差集,并得到一个Index |
| intersection | 计算交集 |
| union | 计算并集 |
| isin | 计算一个指示各值是否都包含在参数集合中的布尔型数组 |
| delete | 删除索引i处的元素,并得到新的Index |
| drop | 删除传入的值,并得到新的Index |
| insert | 将元素插入到索引i处,并得到新的Index |
| is_monotonic | 当各元素均大于等于前一个元素时,返回True |
| is.unique | 当Index没有重复值时,返回True |
| unique | 计算Index中唯一值的数组 |
4.1.4 查看 DaraFrame 的常用属性
DataFrame的基础属性有values、index、columns、dtypes、ndim和shape,分别可以获取DataFrame的元素、索引、列名、类型、维度和形状
4.2.1 重建索引
索引对象是无法修改的,因此,重新索引是指对索引重新排序而不是重新命名,如果某个索引值不存在的话,会引入缺失值。
obj = pd.Series([7.2, -4.3, 4.5, 3.6], index = ['b', 'a', 'd', 'c'])
print(obj)
obj.reindex(['a', 'b', 'c', 'd', 'e'])
对于重建索引引入的缺失值,可以利用fill_value参数填充。
【例4-18】重建索引时填充缺失值。
obj.reindex(['a', 'b', 'c', 'd', 'e'], fill_value = 0)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0QkI36lP-1665241602161)(D:\文件\大三上\python数据分析与可视化\chapter04\【例4-18】重建索引时填充缺失值.png)]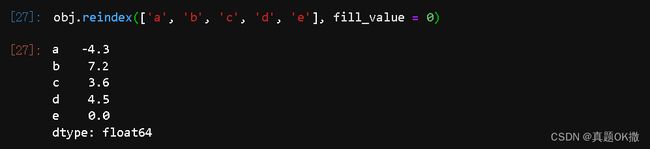
对于顺序数据,比如时间序列,重新索引时可能需要进行插值或填值处理,利用参数method选项可以设置: method = ‘ffill’ 或 ‘pad’,表示前向值填充 method = ‘bfill’ 或 ‘backfill’,表示后向值填充
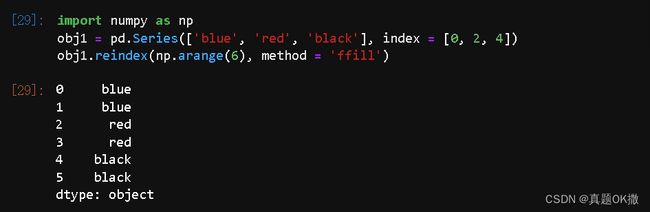
【例4-19】缺失值的前向填充
import numpy as np
obj1 = pd.Series(['blue', 'red', 'black'], index = [0, 2, 4])
obj1.reindex(np.arange(6), method = 'ffill')
4.2.2 更换索引
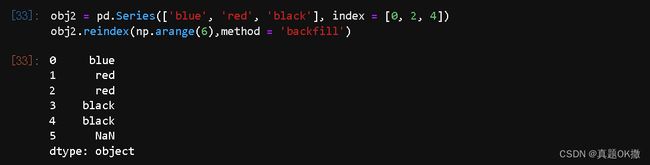
【例4-20】缺失值的后向填充。
obj2 = pd.Series(['blue', 'red', 'black'], index = [0, 2, 4])
obj2.reindex(np.arange(6),method = 'backfill')
对于DataFrame,reindex可以修改(行)索引、列,或两个都修改。如果仅传入一个序列,则结果中的行会重建索引。
【例4-21】DataFrame数据。
df4 = pd.DataFrame(np.arange(9).reshape(3, 3), index = ['a', 'c', 'd'], columns = ['one', 'two', 'four'])
print(df4)

【例4-22】reindex操作。
df4.reindex(index = ['a', 'b', 'c', 'd'], columns = ['one', 'two', 'three', 'four'])
传入fill_value = n用n代替缺失值。
【例4-23】传入fill_value = n填充缺失值。
df4.reindex(index = ['a', 'b', 'c', 'd'], columns = ['one', 'two', 'three', 'four'], fill_value = 100)
表4-2. reindex函数参数
| 参数 | 使用说明 |
|---|---|
| index | 用于索引的新序列 |
| method | 插值(填充)方式 |
| fill_value | 缺失值替换值 |
| limit | 最大填充量 |
| level copy | 在Multiindex的指定级别上匹配简单索引,否则选取其子集 默认为True,无论如何都复制;如果为False,则新旧相等时就不复制 |
4.2.2 更换索引
§ 如果不希望使用默认的行索引,则可以在创建的时候通过Index参数来设置。
§ 在DataFrame数据中,如果希望将列数据作为索引,则可以通过set_index方法来实现。
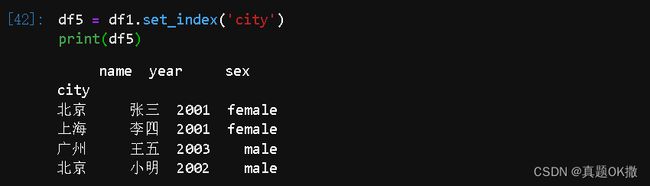
【例4-24】重建索引。
df5 = df1.set_index('city')
print(df5)
与set_index方法相反的方法是reset_index方法。
4.3 DataFrame 数据的查询与编辑
4.3.1 DataFrame 数据的查询
在数据分析中,选取需要的数据进行分析处理是最基本操作。在Pandas中需要通过索引完成数据的选取。
1)选取列:通过列索引或以属性的方式可以单独获取DataFrame的列数据,返回的数据类型为Series。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wj0jKXAd-1665243563750)(D:\文件\大三上\python数据分析与可视化\chapter04\DataFrame 数据的查询_取列.png)]
w1 = df5[['name', 'year']]
display(w1)
display(df5.select_dtypes(exclude = 'int64').head())
df5.select_dtypes(include=['int64', 'object']).head()
2) 选取行
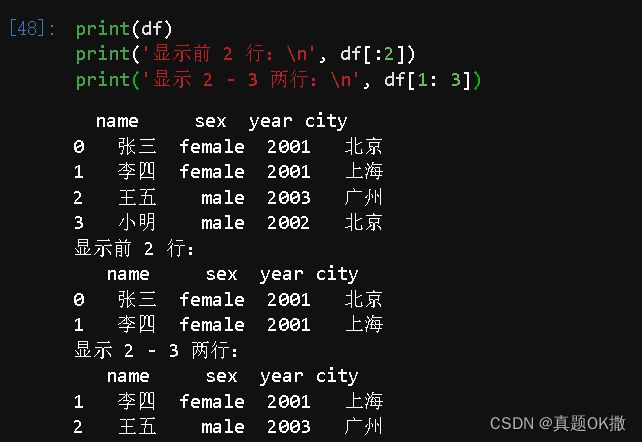
print(df)
print('显示前 2 行:\n', df[:2])
print('显示 2 - 3 两行:\n', df[1: 3])
选取通过DataFrame提供的head和tail方法可以得到多行数据,但是用这两种方法得到的数据都是从开始或者末尾获取连续的数据, 而利用sample可以随机抽取数据并显示。
head() #默认获取前5行
head(n)#获取前n行
tail()#默认获取后5行
tail(n)#获取后n行
sample(n)#随机抽取n行显示
sample(frac=0.6) #随机抽取60%的行
3)选取行和列
ü DataFrame.loc(行索引名称或条件,列索引名称)
ü DataFrame.iloc(行索引位置,列索引位置)
display(df5.loc[:,['name', 'year']])
display(df5.loc[['北京', '上海'], ['name', 'year']])
display(df5.loc[df5['year'] >= 2002, ['name', 'year']])
【例 4 - 28 】利用 iloc 选取行和列
print(df5.iloc[:,2])
print(df5.iloc[[1, 3]])
print(df5.iloc[[1, 3],[1, 2]])
DataFrame 行和列的选取还可以通过 Pandas的query 方法实现。用法:
Pandas.DataFrame.query(self,ecpr, inplace = False, **kwargs) 其中,参数 expr 是评估的查询字符串,kwargs是 dict 关键字参数。
【例 4- 29】 利用 query 查询数据
display(df5.query('year > 2001'))
display(df5.query('year > 2001 & year < 2003'))
4)布尔选择
可以对DataFrame中的数据进行布尔方式选择。
【例 4 - 30】布尔选择
df5[df5['year'] == 2001]

4.3.2 DataFrame 数据的编辑
1)增加数据
增加一行直接通过append方法传入字典结构数据即可。
【例 - 31】DataFrame_增加数据
data1 = {'city':'兰州', 'name': '李红', 'year': 2005, 'sex': 'female'}
df.append(data1, ignore_index = True)
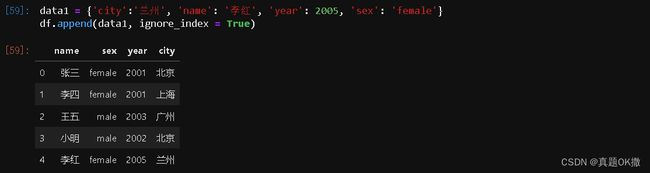
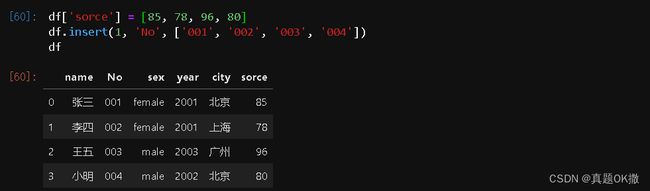
增加列时,只需为要增加的列赋值即可创建一个新的列。若要指定新增列的位置,可以用insert函数。
【例 4 - 32】 增加一列并赋值
df['sorce'] = [85, 78, 96, 80]
df.insert(1, 'No', ['001', '002', '003', '004'])
df
2)删除数据
删除数据直接用drop方法,通过axis参数确定是删除的是行还是列。默认数据删除不修改原数据,需要在原数据删除行列需要设置参数inplace = True。
【例 4 - 33】删除数据行
print(df5.drop('广州'))

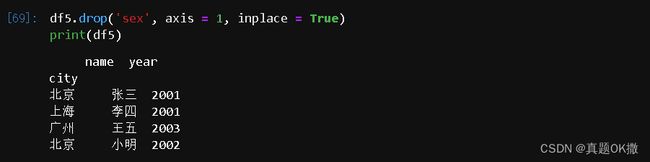
【例 4 - 34】 删除数据的列
df5.drop('sex', axis = 1, inplace = True)
print(df5)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jkDXrYVs-1665241602168)(D:\文件\大三上\python数据分析与可视化\chapter04\【例 4 - 34】 删除数据的列.png)]
3)修改数据
修改数据时直接对选择的数据赋值即可。需要注意的是,数据修改是直接对 DataFrame 数据修改,操作无法撤销,因
此更改数据时要做好数据备份。
val = np.arange(10, 60).reshape(10, 5)
col = ["ax", "bx", "cx", "dx", "ex"]
idx = list("abcdefghij")
df1 = pd.DataFrame(val, columns = col, index = idx)
print('df1:\n', df1)
print(df1[df1 > 30])
df1[df1 > 30] = 100
还可以使用replace进行数据的替换,用法如下:
DataFrame.replace(to_replace=None,value=None,inplace=False,limit=None,regex=False,method='pad')
其中主要参数to_replace表示被替换的值,value表示替换后的值。同时替换多个值时使用字典数据,如DataFrame.replace({‘B’:‘E’,‘C’:‘F’})表示将表中的B替换为E,C替换为F。
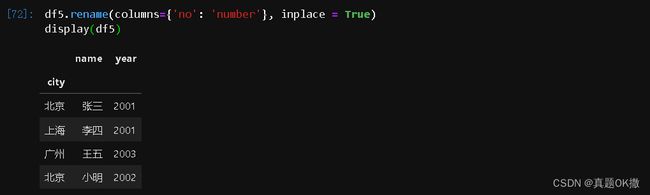
4)修改列名
Pandas通过DataFrame.rename()函数,传入需要修改列名的字典形式来修改列名。
df5.rename(columns={'no': 'number'}, inplace = True)
display(df5)
4.4 Pandas 数据运算
4.4.1 算术运算
Pandas的数据对象在进行算术运算时,如果有相同索引则进行算术运算,如果没有,则会自动进行数据对齐,但会引入缺失值。
【例 4 - 35】 Series 相加
obj1 = pd.Series([5.1 , -2.6, 7.8, 10], index = ['a', 'c', 'g', 'f'])
print('obj1:\n', obj1)
obj2 = pd.Series([2.6, -2.8, 3.7, -1.9], index = ['a', 'b', 'g', 'h'])
print('obj2:\n', obj2)
print(obj1 + obj2)
【例4-36】DataFrame类型的数据相加
a = np.arange(6).reshape(2, 3)
b = np.arange(4).reshape(2, 2)
df1 = pd.DataFrame(a, columns = ['a', 'b', 'e'], index = ['A', 'C'])
print('df1:\n', df1)
df2 = pd.DataFrame(b, columns = ['a', 'b'], index = ['A', 'D'])
print('df2:\n', df2)
print('df1 + df2:\n', df1 +df2)
4.4.2 函数应用哈映射
已定义好的函数可以通过以下三种方法应用到数据:
§ 1. map函数:将函数套用到Series的每个元素中;
§ 2. apply函数,将函数套用到DataFrame的行或列上,行与列通过axis参数设置;
§ 3. applymap函数,将函数套用到DataFrame的每个元素上。
【例4-37】将水果价格表中的“元”去掉。
data = {'fruit': ['apple', 'grap', 'banana'], 'price': ['30元', '43元', '28元']}
df1 = pd.DataFrame(data)
print(df1)
def f(x):
return x.split('元')[0]
df1['price'] = df1['price'].map(f)
print('修改后的数据表:\n', df1)
【例4-38】apply函数的使用方法。
df2 = pd.DataFrame(np.random.randn(3, 3), columns = ['a', 'b', 'c'], index = ['app', 'win', 'mac'])
print(df2)
df2.apply(np.mean)
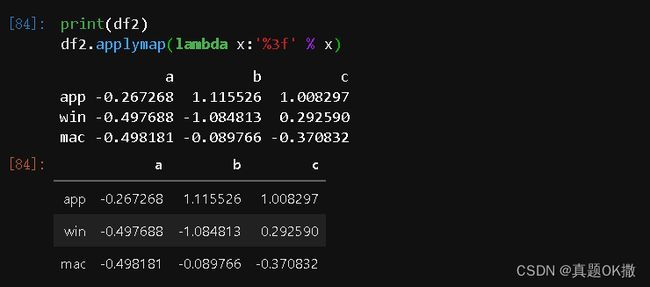
【例4-39】applymap函数的用法
print(df2)
df2.applymap(lambda x:'%3f' % x)
4.4.3 排序
sort_index方法:对索引进行排序,默认为升序,降序排序时加参数ascending=False。
sort_values方法:对数值进行排序。by参数设置待排序的列名
【例 4 - 40】Series 的排序
wy = pd.Series([1, -2, 4, -4], index = ['e', 'b', 'a', 'd'])
print(wy)
print('排完序后的:\n', wy.sort_index())
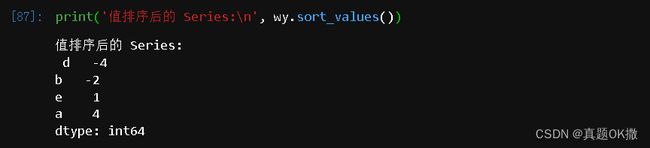
【例 4 - 41】 排序
print('值排序后的 Series:\n', wy.sort_values())
对于DataFrame数据排序,通过指定轴方向,使用sort_index函数对行或列索引
进行排序。如果要进行列排序,则通过sort_values函数把列名传给by参数即可。
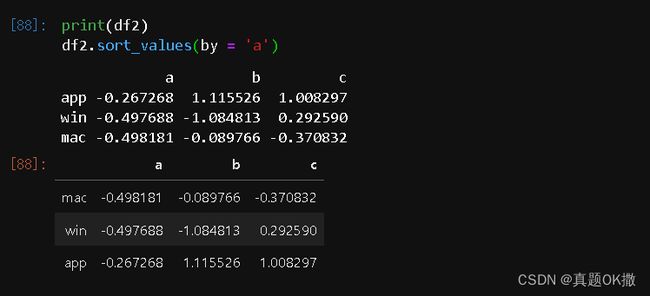
【例4-42】DataFrame排序。
print(df2)
df2.sort_values(by = 'a')
4.4.4 汇总与统计
1)数据汇总
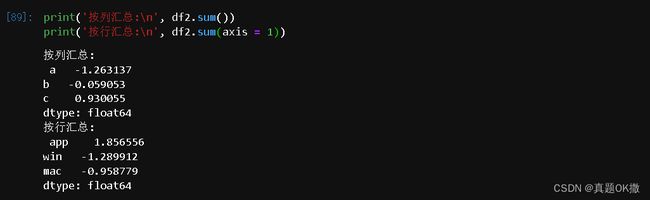
在 DataFrame 中,可以通过 sum 方法对每列进行求和汇总,与 Excel 中的 sum函数类似。如果设置axis = 1指定轴方向,可以实现按行汇总。
【例 4 - 43】 DataFrame中的汇总
print('按列汇总:\n', df2.sum())
print('按行汇总:\n', df2.sum(axis = 1))
2)数据描述与统计
利用describe方法会对每个数值型的列数据进行统计。
【例 4 - 44】describe示例
df2.describe()
表4-3.Pandas中常用的描述性统计量
| 函数 | 使用说明 |
|---|---|
| count | 计数 |
| sum | 求和 |
| mean | 求平均值 |
| median | 求中位数 |
| std、var | 无偏标准差和方差 |
| min、max | 求最小值最大值 |
| prod | 求积 |
| first、last | 第一个和最后一个值 |
对于类别型特征的描述性统计,可以使用频数统计表。Pandas库中通过unique方法获取不重复的数组,利用value_counts方法实现频数统计。
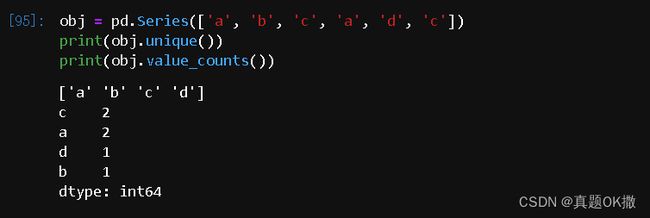
【例 4 - 45】 数据的频数统计
obj = pd.Series(['a', 'b', 'c', 'a', 'd', 'c'])
print(obj.unique())
print(obj.value_counts())
4.5 数据分组与聚合
4.5.1 数据分组
Pandas提供了一个高效的groupby方法,配合agg或apply方法实现数据分组聚合的操作。
1)groupby方法
groupby方法可以根据索引或字段对数据进行分组。
格式为:
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, **group_keys=True, squeeze=False, kwargs)
表4-4. groupby方法的参数及其说明
| 参数名称 | 参数说明 |
|---|---|
| by | 可以传入函数、字典、Series等,用于确定分组的依据 |
| axis | 接收int,表示操作的轴方向,默认为0 |
| level | 接收int或索引名,代表标签所在级别,默认为None |
| as_index | 接收boolean,表示聚合后的标签是否以DataFrame索引输出 |
| sort | 接收boolean,表示对分组依据和分组标签排序,默认为True |
| group_keys | 接收boolean,表示是否显示分组标签的名称,默认为True |
| squeeze | 接收boolean,表示是否在允许情况下对返回数据降维,默认False |
【例 4 - 46】groupby 基本用法
import pandas as py
import numpy as np
df = pd.DataFrame({'key1': ['a', 'a', 'b', 'b', 'a'],
'key2': ['yes', 'no', 'yes', 'yes', 'no'],
'data1': np.random.randn(5),
'data2': np.random.randn(5)})
grouped = df['data1'].groupby(df['key1'])
print(grouped.size())
print(grouped.mean())
2)按列名分组
DataFrame 数据的列索引名可以作为分组键,但需要注意的是用于分组的对象必须是DataFrame数据本身,否则搜索不到索引名称会报错。
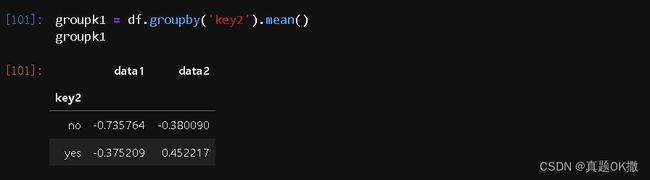
【例 4 - 47】列索引名称作为分组键
groupk1 = df.groupby('key2').mean()
groupk1
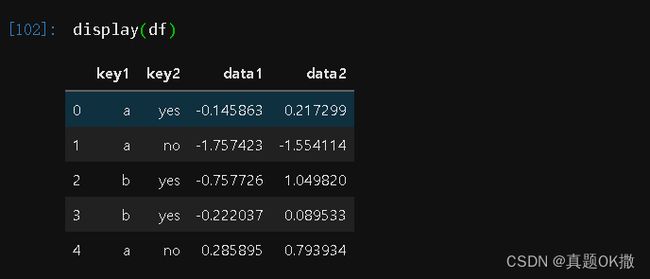
3)按列表或元组分组
分组键还可以是长度和DataFrame行数相同的列表或元组,相当于将列表或元组看做DataFrame的一列,然后将其分组。
【例4-48】按列表或元组分组。
display(df)
4)按字典分组
如果原始的DataFrame中的分组信息很难确定或不存在,可以通过字典结构,定义分组信息。
【例4-49】通过字典作为分组键,分组时各字母不区分大小写
df = pd.DataFrame(np.random.normal(size = (6,5)),index = ['a','b','c','A','B','c'])
print("数据为:\n",df)
wdict = {'a':'one','A':'one','b':'two','B':'two','c':'three'}
print("分组汇总后的结果为:\n",df.groupby(wdict).sum())
5)按函数分组
函数作为分组键的原理类似于字典,通过映射关系进行分组,但是函数更加灵活。
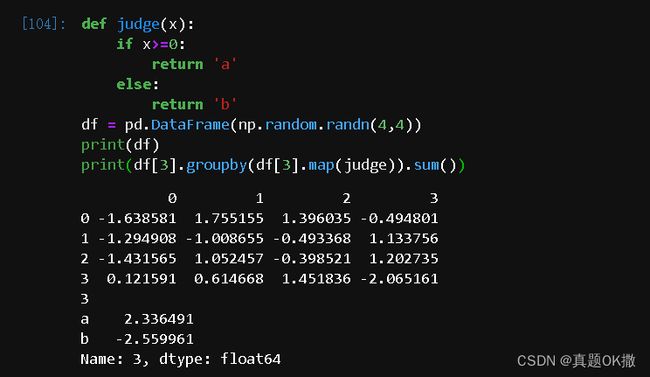
【例4-50】通过DataFrame最后一列的数值进行正负分组。
def judge(x):
if x>=0:
return 'a'
else:
return 'b'
df = pd.DataFrame(np.random.randn(4,4))
print(df)
print(df[3].groupby(df[3].map(judge)).sum())
4.5.2 数据聚合
1)聚合函数
除了之前示例中的mean函数外,常用的聚合运算还有count和sum等
表4-5. 聚合运算方法
| 函数 | 使用说明 |
|---|---|
| count | 计数 |
| sum | 求和 |
| mean | 求平均值 |
| median | 求中位数 |
| std、var | 无偏标准差和方差 |
| min、max | 求最小值最大值 |
| prod | 求积 |
| first、last | 第一个和最后一个值 |
2)使用agg方法聚合数据
agg、aggregate方法都支持对每个分组应用某个函数,包括Python内置函数或自定义函数。同时,这两个方法也能够直接对DataFrame进行函数应用操作。在正常使用过程中,agg和aggregate函数对DataFrame对象操作的功能基本相同,因此只需掌握一个即可。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gEqR6cM4-1665241602179)(D:\文件\大三上\python数据分析与可视化\chapter04\【例4 - 51】表.png)]
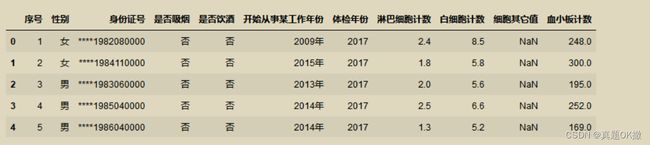
【例4-51】使用agg求出当前数据对应的统计量。
import pandas as pd
data = pd.read_excel('C:\\Users\\86152\\testdata.xls')
data.head()
data.info()
data[['淋巴细胞计数','白细胞计数']].agg([np.sum,np.mean])
【例4-52】利用agg分别求字段的不同统计量。
data.agg({'淋巴细胞计数':np.mean,'血小板计数':np.std})

3)计算不同字段的不同数目的统计量
【例4-53】不同字段统计不同数目的统计量。
data.agg({'淋巴细胞计数':np.mean,'血小板计数':[np.mean,np.std]})

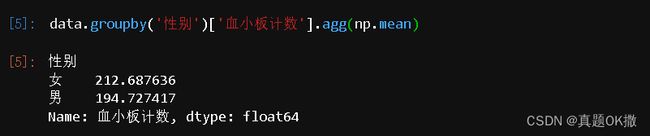
【例4-54】统计不同性别人群的血小板计数
data.groupby('性别')['血小板计数'].agg(np.mean)
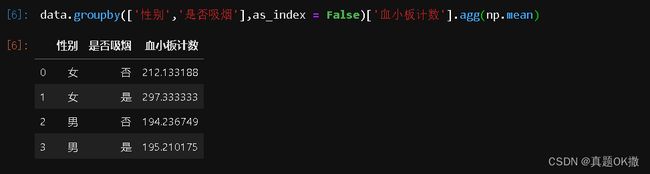
【例4-55】as_index参数的用法。
data.groupby(['性别','是否吸烟'],as_index = False)['血小板计数'].agg(np.mean)
4.5.3 分组运算
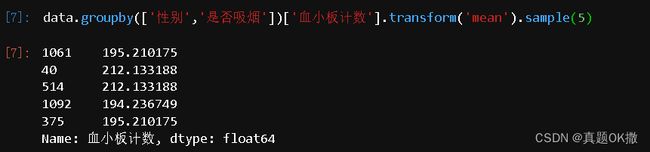
1)transform方法
通过transform方法可以将运算分布到每一行。
data.groupby(['性别','是否吸烟'])['血小板计数'].transform('mean').sample(5)
【例4-56】transform方法.png)]
2)使用apply方法聚合数据
apply方法类似于agg方法,能够将函数应用于每一列。
【例4-57】数据分组后应用apply统计。
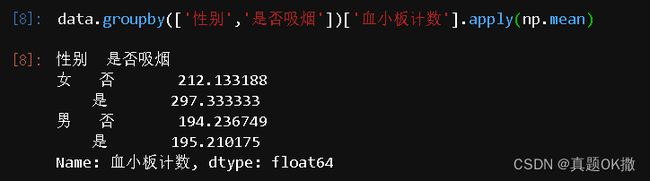
data.groupby(['性别','是否吸烟'])['血小板计数'].apply(np.mean)
4.6 数据透视表
4.6.1 透视表
数据透视表( Pivot Table ) 是数据分析中常见的工具之一,根据一个或多个键值对数据进行聚合,根据列或行的分组键将数据划分到各个区域。
表4-5. pivot_table函数主要参数及其说明
| 参数 | 使用说明 |
|---|---|
| data | 接收DataFrame,表示创建表的数据 |
| values | 接收string,指定要聚合的数据字段,默认全部数据 |
| index | 接收string或list,表示行分组键 |
| columns | 接收string或list,表示列分组键 |
| aggfunc | 接收functions,表示聚合函数,默认为mean |
| margins | 接收boolean,表示汇总功能的开关 |
| dropna | 接收boolean,表示是否删掉全为NaN的列,默认False |
【例4-58】pivot_table默认计算均值。
import pandas as pd
import numpy as np
data = pd.DataFrame({'k1':['a','b','a','a','c','c','b','a','c','a','b','c'],'k2':['one',
'two','three','two','one','one','three','one','two','three','one','two'],
'w':np.random.rand(12),'y':np.random.randn(12)})
print(data)
print("------------------------------------------------")
print(data.pivot_table(index = 'k1',columns = 'k2'))
【例4-59】分类汇总并求和。
data.pivot_table(index = 'k1',columns = 'k2',aggfunc = 'sum')

4.6.2 交叉表
交叉表是一种特殊的透视表,主要用于计算分组频率。
crosstab的格式:
crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, dropna=True, normalize=False)
表4-6. crosstab主要参数及其说明
| 参数 | 使用说明 |
|---|---|
| index | 接收 string或list,表示行索引键,无默认 |
| columns | 接收string或list,表示列索引键 |
| values | 接收array,表示聚合数据,默认为None |
| rownames | 表示行分组键名,无默认 |
| colnames | 表示列分组键名,无默认 |
| aggfunc | 接收functions,表示聚合函数,默认为None |
| margins | 接收boolean,表示汇总功能的开关 |
| dropna | 接收boolean,表示是否删掉全为NaN的列,默认False |
| normalize | 接收boolean,表示是否对值进行标准化,默认为False |
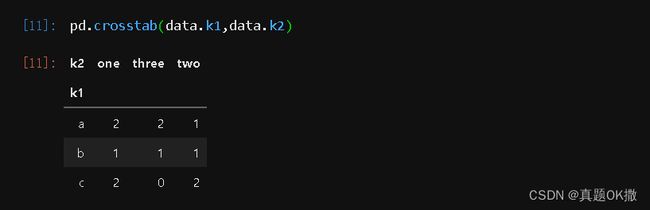
【例4-60】交叉表示例。
pd.crosstab(data.k1,data.k2)
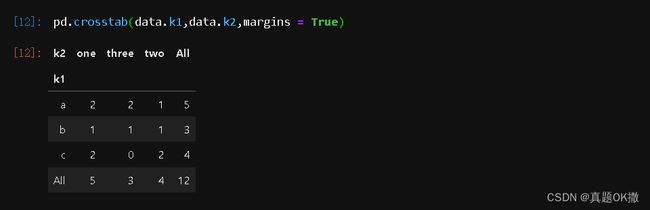
【例4-61】带参数margin。
pd.crosstab(data.k1,data.k2,margins = True)
4.7 Pandas 可视化
Pandas中集成了Matplotlib中的基础组件,让绘图更加便捷。
表 4 - 8 Series.plot 的主要参数及其说明

表 4 - 9 DataFrame.plot 的主要参数及其说明

4.7.1 线行图
Pandas库中的Series和DataFrame中都有绘制各类图表的plot方法,默认绘制的都是线形图。通过DataFrame对象的plot方法可以为各列绘制一条线,并创建图例。
【例4-62】Series的plot方法绘图。
import matplotlib.pyplot as plt
%matplotlib inline
s = pd.Series(np.random.normal(size = 10))
s.plot()
【例4-63】DataFrame的plot方法绘图。
df = pd.DataFrame({'normal':np.random.normal(size = 50),'gamma':np.
random.gamma(1,size = 50)})
df.plot()
4.7.2 柱状图
在Pandas中绘制柱状图只需在plot函数中加参数kind = ‘bar’,如果类别较多,可以绘制水平柱状图(kind = ‘barh’)。
【例4-64】DataFrame中绘制柱状图。
stu = {'name':['小明','王芳','赵平','李红','李涵'],
'sex':['male','female','female','female','male'],
'year':[1996,1997,1994,1999,1996]}
data = pd.DataFrame(stu)
print(data['sex'].value_counts())
print(data['sex'].value_counts().plot(kind = 'bar',rot = 30))
【例4-65】DataFrame数据对象的柱状图。
df = pd.DataFrame(np.random.randint(1,100,size = (3,3)),index =
{'one','two','three'},columns = ['I1','I2','I3'])
df.plot(kind = 'barh')
4.7.3 直方图和密度图
直方图用于频率分布,y轴为数值或比率。绘制直方图,可以观察数据值的大致分布规律。pandas中的直方图可以通过hist方法绘制。核密度估计是对真实密度的估计,其过程是将数据的分布近似为一组核(如正态分布)。通过plot函数的kind = ‘kde’可以进行绘制。
【例4-66】pandas中直方图绘制。
wy = pd.Series(np.random.normal(size = 80))
s.hist(bins = 15,grid = False)
直方图用于频率分布, y 轴为数值或比率。绘制直方图,可以观察数据值的大致分布规律。pandas中的直方图可以通过hist方法绘制。
核密度估计是对真实密度的估计,其过程是将数据的分布近似为一组核(如正态分布)。通过plot函数的kind = ‘kde’可以进行绘制。
【例4-67】panas中密度图的绘制。
wy = pd.Series(np.random.normal(size = 80))
s.plot(kind = 'kde')
4.7.4 散点图
散点图主要用来表现数据之间的规律。通过plot函数的kind = 'scatter’可以进行绘制。
【例4-68】pandas绘制散点图。
wd = pd.DataFrame(np.arange(10),columns = ['A'])
wd['B'] = 2*wd['A']+4
wd.plot(kind = 'scatter',x = 'A',y = 'B')
(1)导入模块
import numpy as np
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
%matplotlib inline
(2)获取数据
导入待处理的数据 tips.xls,并显示前 5 行
fdata=pd.read_excel('C:\\Users\\86152\\tips.xls')
fdata
(3)查看数据
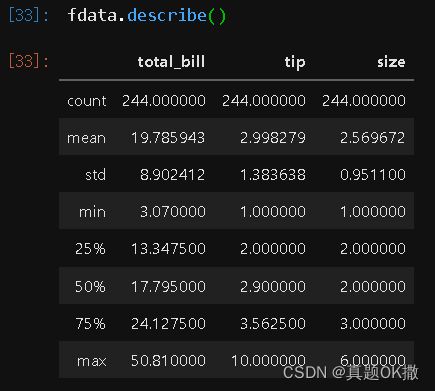
1)查看数据的描述信息
fdata.describe()
2)修改列名为汉字,并显示前 5 行数据
3)人居消费
fdata['人均消费']=round(fdata['消费总额']/fdata['人数'],2)
fdata.head()

4)查询抽烟男性中人均消费大于 15 的数据
# 方法1:
fdata[(fdata['是否抽烟']=='Yes') &(fdata['性别']=='Male') & (fdata['人均消费']> 15) ]
# 方法2:
# fdata[(fdata.是否抽烟=='Yes') &(fdata.性别=='Male') & (fdata.人均消费> 15) ]
# 方法3:
# fdata.query( '是否抽烟=="Yes" & 性别=="Male" & 人均消费>15')
5)分析小费和总金额的关系,散点图
#分析小费和总金额的关系,散点图
fdata.plot(kind='scatter',x='消费总额',y='小费')
#正相关关系
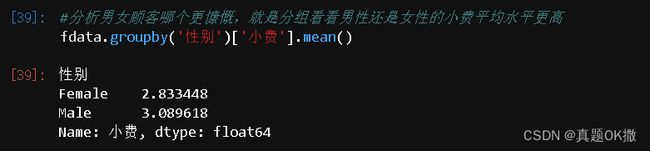
· 6)分析男女顾客哪个更慷慨,就是分组看看男性还是女性的小费平均水平更高
#分析男女顾客哪个更慷慨,就是分组看看男性还是女性的小费平均水平更高
fdata.groupby('性别')['小费'].mean()
7)分析日期和小费的关系
#分析日期和小费的关系,直方图
print(fdata['星期'].unique())
r=fdata.groupby('星期')['小费'].mean()
fig=r.plot(kind='bar',x='星期',y='小费',fontsize=12,rot=36)
# fig.axes.title.set_size(16)
8)性别+抽烟书对慷慨度的影响
#性别+抽烟书对慷慨度的影响
r=fdata.groupby(['性别','是否抽烟'])['小费'].mean()
fig=r.plot(kind='bar',x=['性别','是否抽烟'],y='小费',fontsize=12,rot=30)
fig.axes.title.set_size(16)
9)聚餐时间与小费数额的关系
#聚餐时间与小费数额的关系
r=fdata.groupby('聚餐时间段')['小费'].mean()
fig=r.plot(kind='bar',x='聚餐时间',y='小费')
fig.axes.title.set_size(16)