Dense Pose FaceBook 3D 三维立体 姿态识别 AI 动作学习模型
实现从 2D 图像到 3D 表面的对应在很多方面都有极具价值的应用前景。近日,FAIR 发布了一篇研究论文,介绍了他们通过人工方式标注的图像到表面密集对应数据集 DensePose-COCO 以及基于此训练的 DensePose-RCNN 架构,得到了一个能实时地得到高准确度结果的系统。该研究发布后得到了广泛的关注,机器之心在此对该论文进行了摘要介绍,更多详情请参阅原论文和项目网站。
-
论文地址:https://arxiv.org/abs/1802.00434
-
项目网站:http://densepose.org
![]()
本研究的目标是通过建立从人体的 2D 图像到基于表面的 3D 表征的密集对应(dense correspondence)来进一步推进人类对图像的理解。我们可以认为这个任务涉及到一些其它问题,比如物体检测、姿态估计、作为特例或前提的部位和实例分割。在图形处理、增强现实或人机交互等不只需要平面关键特征位置标记的问题中,这一任务的解决将能实现很多应用,并且还能助力实现通用型的基于 3D 的物体理解。
建立从图像到基于表面的模型的密集对应的任务已经在可使用深度传感器的设置中基本得到了解决,比如在 [41] 的 Vitruvian 流形中、指标回归森林 [33] 或最近 [44] 提出的密集点云对应。相对而言,我们的情况则是考虑使用单张 RGB 图像作为输入,然后我们基于此来构建表面点和图像像素之间的对应。
最近也有一些其它研究想要以无监督的方式恢复 RGB 图像配对 [3] 或集合 [48,10] 之间的密集对应。最近,[42] 使用了同变性原理(equivariance principle)来将图像集对齐到一个共同坐标系,同时也遵循了分组图像对齐的一般思想,比如 [23,21]。
尽管这些研究都针对的是一般类别,但我们的研究关注的可以说是最重要的视觉类别——人类。对于人类而言,可以通过使用参数可变形表面模型(parametric deformable surface model)来简化这一任务,比如 [2] 的 Skinned Multi-Person Linear(SMPL)模型或最近的 [14] 中通过精心控制 3D 表面获取而得到的 Adam 模型。对于图像到表面映射的任务,[2] 中的作者提出了一种两阶段方法:首先通过一个 CNN 检测人类关键特征位置,然后通过迭代式最小化为该图像拟合一个参数可变形表面模型。与我们的研究同时进行的 [20] 对 [2] 的方法进行了发展,使之能以端到端的方式工作,其在用于恢复 3D 相机姿态和低维身体参数化的深度网络中整合了一个模块——迭代式重投射误差最小化(iterative reprojection error minimization)。
我们的方法与这些研究都不一样,我们采用了一种全面的监督学习方法并收集了人体的图像与详细准确的参数表面模型 [27] 之间的真实对应数据:我们没有在测试时间使用 SMPL 模型,而是将其用作在训练阶段定义我们的问题的一种方法。我们的方法可以被理解成是 [26, 1, 19, 7, 40, 18, 28] 中用于人类的标准的下一步延伸工作。Fashionista [46]、PASCAL-Parts [6] 和 Look-Into-People (LIP) [12] 数据集中已经提供了人体部位分割掩码;这些可以被看作是提供了图像到表面对应的粗糙版本,其中没有连续的坐标,而是可以预测离散的部位标签。在表面层面的监督直到最近才被 [43] 引入合成图像,同时 [22] 中一个包含 8515 张图像的数据集标注上了 3D 模型到图像的关键点和半自动拟合。本研究没有损伤我们的训练集的范围和真实性,而是引入了一种全新的标注流程,让我们可以为 COCO 数据集的 5 万张图像收集真实的对应,进而得到了我们新的 DensePose-COCO 数据集。
我们的工作在思想上最接近于近期的 DenseReg 框架 [13],其中训练的 CNN 能成功构建自然场景中的 3D 模型和图像之间的密集对应关系。那项工作主要关注的是人脸,并且只在姿态变化适中的数据集上评估了他们的结果。但是,由于人体具有更高的复杂度和灵活性,同时姿态也存在更大的变化,所以我们这里还面临着新的难题。我们采用了合适的架构设计来解决这些难题,详见第 3 节;该架构相比于 DenseReg 类型的全卷积架构有显著的提升。通过将我们的方法与近期的 Mask-RCNN 系统 [15] 相结合,我们表明通过鉴别式方法训练的模型能实时地为涉及数十人的复杂场景恢复高准确度的对应场:我们的系统在一个 GTX 1080 GPU 上能以每秒 20-26 帧的速度处理 240×320 图像或以每秒 4-5 帧的速度处理 800×1100 图像。
我们的贡献可以总结为三点。首先,如第 2 节所述,我们通过收集 SMPL 模型 [27] 和 COCO 数据集中的人物外观之间的密集对应而为该任务引入了第一个人工收集的真实数据集。这是通过在标注过程中使用一种利用了 3D 表面信息的全新标注流程实现的。
第二,如第 3 节所述,通过在任何图像像素对人体表面坐标进行回归,我们使用所得到的数据集训练了可以得到自然环境中密集对应的基于 CNN 的系统。我们实验了依赖于 Deeplab [4] 的全卷积架构和依赖于 Mask-RCNN [15] 的基于区域的系统,并观察到了基于区域的模型相比于全卷积网络的优越性。我们还考虑了我们的方法的级联变体,并在已有的架构上实现了进一步提升。
我们探索了利用我们构建的真实信息的不同方法。我们的监督信号是在每个训练样本中随机选择的图像像素子集上定义的。我们使用了这些稀疏对应来训练一个「教师(teacher)」网络,其可以「修补(inpaint)」图像其余区域的监督信号。不管是与稀疏点相比还是与其它任何已有的数据集相比,使用这种修复后的信号能够得到明显更好的表现,第 4 节通过实验证明了这一点。
我们的实验表明密集的人体姿态估计在很大程度上是可以实现的,但仍还有改善的空间。我们使用一些定性结果和表明该方法发展潜力的方向而对我们的论文进行了总结。我们将通过我们的项目网站公开提供代码和数据:http://densepose.org。
COCO-DensePose 数据集

图 1:密集姿态估计的目标是将 RGB 图像上的所有人类像素映射成 3D 的人体表面。我们引入了一个大规模真实数据集 DensePose-COCO,其中包含人工标注的 5 万张 COCO 图像的图像到表面对应数据;我们还训练了 DensePose-RCNN,能以每秒多帧的速度在每个人体区域内密集回归特定部位的 UV 坐标。左图:图像及通过 DensePose-RCNN 所得到的回归后的对应。中图:DensePose-COCO 数据集标注。右图:身体表面的分割和 UV 参数化。
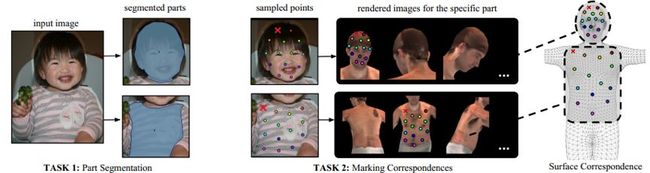
图 2:通过让标注者将图像分割成形义区域然后再在任何渲染的部位图像上为每个被采样的点定位其对应的表面点,我们标注了图像和 3D 表面模型的密集对应关系。红色叉号表示当前被标注的点。渲染后视图的表面坐标在 3D 模型上定位收集到的 2D 点。

图 3:用于收集每个部位的对应标注的用户界面:我们向标注者提供了人体部位的 6 个预渲染的视角,这样整个部位表面都是可见的。一旦标注了目标点,该点就会同时显示在所有渲染过的图像上。

图 4:标注的可视化:图像(左)、收集到的点的 U 值(中)和 V 值(右)
学习密集人体姿态估计
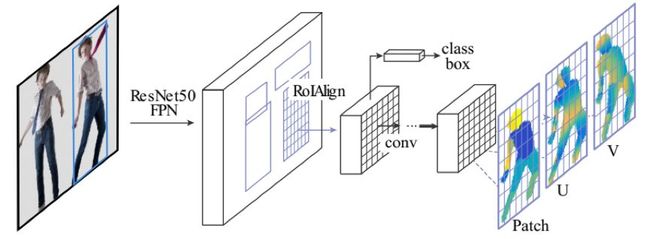
图 7:DensePose-RCNN 架构:我们使用了区域提议生成和特征池化的级联,之后跟着一个全卷积网络,用于密集地预测离散部位标签和连续表面坐标。
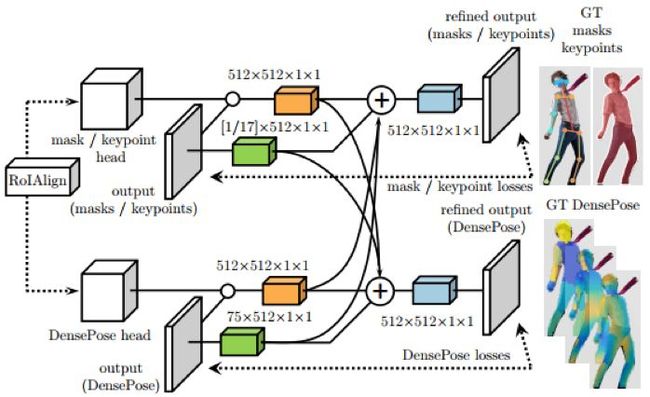
图 8:交叉级联架构:图 7 中 RoIAlign 模块的输出送入 DensePose 网络以及用于其它任务(掩码、关键点)的辅助网络。一旦从所有任务获得了第一阶段的预测,它们就将被组合起来送入每个分支的第二阶段细化。
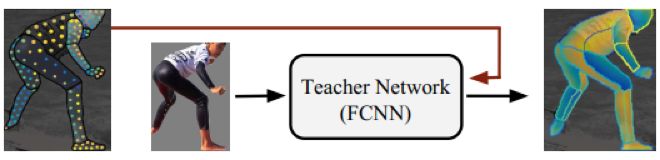
图 9:我们首先使用我们的稀疏的、人工收集的监督信号训练一个「教师网络」,然后使用该网络来「修补」用于训练我们的基于区域的系统的密集监督信号。
实验
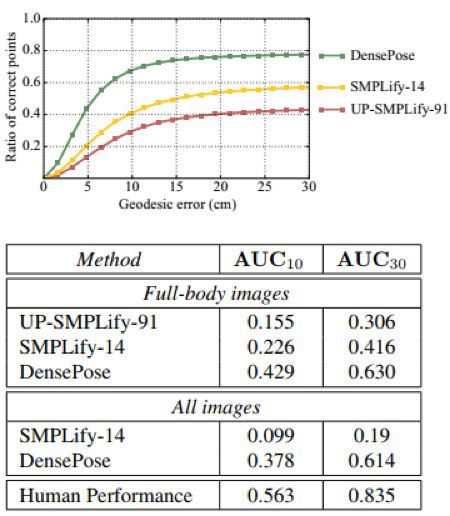
图 10:SMPLify [2] 的基于模型的单人姿态估计和我们的基于 FCN 的结果的定性比较,包含了具有遮挡(「All images」)和不含遮挡(「Full-body images」)的情况。
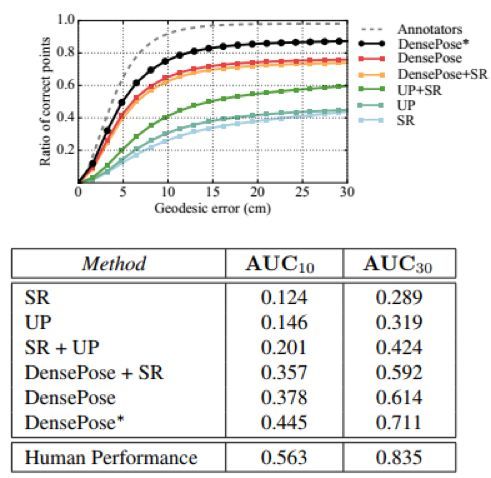
图 11:使用不同类型的监督信号进行训练的单人表现:DensePose 得到了比其它数据集显著更准确的结果。DensePose∗在训练和测试时都使用了 figure-ground oracle

图 12:多人密集对应标注的结果。这里我们在包含多人的真实 COCO 数据集图像上比较了我们提出的 DensePose-RCNN 系统与全卷积方法的表现,其中这些图像在尺寸、姿态和背景上具有较高的多样性。

图 14:用于纹理迁移的定性结果:在上面一行中所提供的纹理根据估计的对应映射成了图像像素。完整视频请访问:http://densepose.org。
论文:DensePose:自然环境中的密集人体姿态估计(DensePose: Dense Human Pose Estimation In The Wild)

摘要:在本研究中,我们构建了人体的 RGB 图像与基于表面的表征之间的密集对应,我们将这个任务称为密集人体姿态估计。首先,我们通过引入一种有效的标注流程而收集了 COCO 数据集中 5 万张人类外观的密集对应。然后我们使用我们的数据集训练了能够在自然环境中(in the wild)得到密集对应的基于 CNN 系统,也就是说环境中存在背景、遮挡和尺度变化等情况。通过训练一个可以填补缺失真实值的「修补」网络,我们提升了我们的训练集的有效性;并且相比于过去所能实现的最好结果有明显的提升。我们使用全卷积网络和基于区域的模型进行了实验,并观察到了后者的优越性;我们通过级联进一步提升了准确度,得到了一个能实时地得到高准确度结果的系统。我们的项目网站还提供了补充材料和视频:http: //densepose.org