1024程序员节?我们整点AI绘图玩玩吧,一文教你配置stable-diffusion
1024程序员节?我们整点AI绘图玩玩吧,一文教你配置stable-diffusion
需提前准备:一台高性能的电脑(尤其是显存)、python、Git、梯子。
其实Github上有很多关于Stable diffusion的库,综合对比之后,我选取的是比较全面的AUTOMATIC1111这个,源码链接:Stable-diffusion(Github)
![]()
找到安装那块的教程,此教程以windows为例。
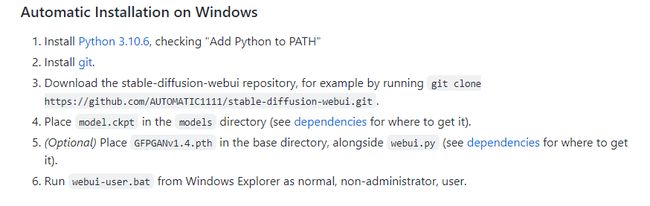
ps:如果你电脑上已经有了python和git,可以直接跳至第3步。
1.安装python
网址:python.download
过于基础内容,安装过程就略过了。推荐安装py3.8/3.9
(如果你没有计算机基础的话,可以去浏览器搜一下教程,有非常多可以看。)
记得添加环境变量。
验证安装可以在cmd命令行中键入 python

能看到py的版本,就表示安装好了。
2.安装Git
网址:Git.download
安装位置没啥说的,C盘有位置默认就行,装D盘也可以。
安装组件(如下图),建议添加桌面快捷方式(默认没勾选),其它的按照默认勾选即可。

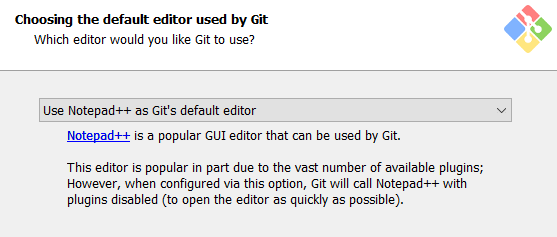
其中有一步是选择Git的默认编辑器,默认是Vim。如果你电脑上有Notepad++(一款轻量级编辑文本的软件,非常好用。Notepad++),可以选这个;如果没有,可以选Notepad,也就是我们常说的记事本~
其它的地方基本是一路Next,完成安装。
3.下载Repo
打开Git Bash,键入以下代码。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
(需注意Git不能ctrl+v,只能右键paste;且复制后如果出现“~、[”等多余的符号,需要手动删除,且只能通过键盘选择位置,不能用鼠标。有点蠢)
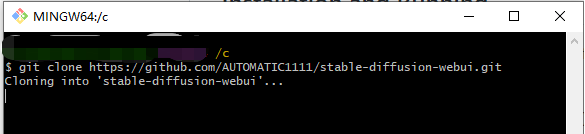
如果失败的话,大概率是SSL校验问题。
在Git Bash中键入以下代码跳过SSL校验。
git config --global http.sslVerify false
git config --global https.sslVerify false
(ps:如果到时候要再开启ssl的话,把上面代码中的false改成true,复制到Git中即可。)

看到100%就完成了,然后记一下下载文件夹的路径。
4.下载依赖
Dependencies

有三种下载方式,官方下载/文件/种子,(推荐直接迅雷下种子链接,直接下载到下边这个文件夹下。)
找到你git stable-diffusion的目录,找到models→stable-diffusion,把这个ckpt文件下载过来。(时间会比较久,等待过程中可以并行第5步)

5.配置webui-user.bat
5.1 镜像源
找到你下载的stable-diffusion-web文件夹,双击进去找到一个叫webui-user.bat的文件,双击打开,等待安装。(先双击打开,让其自动创建一个venv的文件夹)
大概率会进行不下去,这个时候需要用到镜像,详情可看这个教程:pip.ini
下载pip,然后在你电脑用户User的目录下,直接右键创建新文件夹“pip”,在pip文件夹里创建记事本txt文件,命名为pip.ini,连同txt的后缀文件格式一起改掉。

打开这个pip.ini文件,复制以下代码进去,如下图所示。
[global]
index-url = http://pypi.doubanio.com/simple/
[install]
trusted-host=pypi.doubanio.com
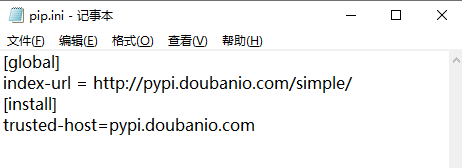
这里用的是豆瓣源,用清华源、阿里的都是可以的,都是镜像。

5.2 pip版本问题
如果你不是下载的最新的pip,像我一样是之前就下载好的,这块会提示你安装最新版本,截至我写作时,最新版本为22.3。(接下来很重要,请仔细看教程。)

(1)还是先找到你下载“stable-diffusion-webui”的文件位置,双击进入我们刚才自动生成的“venv”这个文件夹,双击进入“Scripts”这个文件夹,复制路径
![]()
(2)打开cmd命令行,cd到这个路径。(就是输入cd,然后空格,粘贴路径,回车)
再输入“activate”。

回车键,进入虚拟环境。

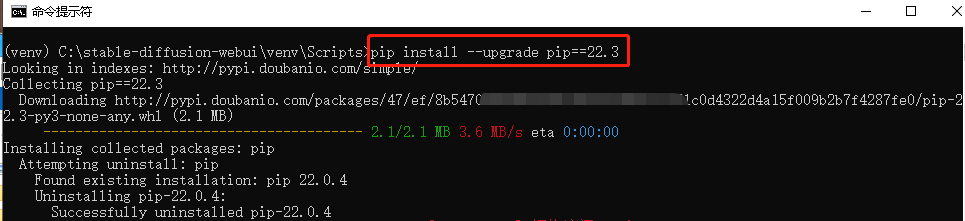
(3)python已经安装好包需要升级的指定版本,命令如下:
pip install --upgrade 包名称==版本号
例如:pip install --upgrade pip==22.3(根据提示你的最新版本输入版本号即可)
5.3 查漏补缺
再次打开stable-diffusion-webui文件夹下的web-user.bat文件,安装所需。
(如果还提示你缺什么东西,按照命令行提示你的输入下载安装即可。缺啥补啥。每台电脑可能会出现不同的问题,这里就不过多陈述所有情况,因为我也没法预知你们会出现什么问题。)

等待所有安装完毕。(也需要比较长的时间)
5.4 webui.bat
最后,打开stable-diffusion-webui文件夹下的webui.bat,等待。

看到URL就表示完成了,就可以复制上面的网址到浏览器,进行AI绘图了。
6. UI页面介绍
打开UI界面后,如下图所示
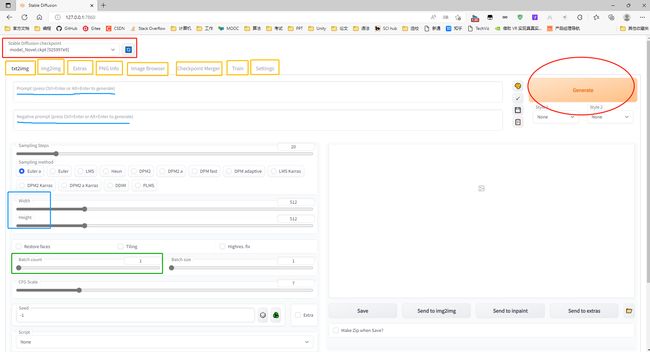
简单介绍下:
红色框框是选择train好的模型,按照之前的步骤会只有默认的模型,想要探索更多也可以寻找其它模型的资源文件。
黄色框框,txt2img,文字生成图片;img2img,以图生图;Extras,优化图像;PNG info 图像信息;Checkpoint Merger,模型合并;Train,训练;Settings,修改参 数设置。
用得比较多的肯定是 文字生图 & 以图生图,(所以下面只介绍这两个part,其它可自行了解。)
蓝色横线,Prompt,文字描述;Negative prompt,不想要什么。
Sampling steps可以调的高一些。(默认是20,推荐50以上。)
蓝色框框,Width,Height,图像长宽,这个可以根据你电脑算力来设定,不建议设的很大,我一般用640×640。
Restore faces 优化脸部,这个需要装额外的依赖,这里就不过多讲述了。
绿色框框,生成图的数量,(默认是1张,建议设3-8张左右。)
红色圆圈,生成,点击一下我们就可以等待AI绘图啦。
接下来我们示范一下,结果如下图所示。

7.结语
(关于这个stable-diffusion的环境配置问题,每台电脑会碰到不同的问题;遇到报错,就找命令行中的error找找错误所在,一般都会告诉你该怎么做,缺什么东西下载补齐即可。)
还有很多训练的模型等待大家去发掘,此项目也有很多的功能等待大家探索,你甚至可以直接用手机访问本地的这个网址。
该stable-diffusion的源码也在不断的更新中,大家有Github号的可以去给原作者点个⭐star。
最后希望大家使用愉快,玩的开心!
都看到这里了,点个赞再走吧觉得有用可以分享一下哦✨
写稿不易,您的支持是我更新最大的动力~