基于逻辑回归的金融风控贷款违约预测分析(笔记)
一、背景与思路
(一)背景
核心问题:对贷款偿债能力的评估
1. 方法:利用逻辑回归(理解简单,可解释性强)
2. 信用评分卡的构建
| 金融风控 | |
| 定性分析 | 逻辑回归 |
| 定量分析 | 信用评分卡 |
(二)流程
1. 数据获取:包括获取存量客户及潜在客户的数据;
2. 数据预处理:包括数据清洗、缺失值处理;
3. 探索性分析:获取样本总体的大概情况,描述样本总体情况的指标主要包括直方图、箱型图等;
4. 变量选择:主要通过统计学方法,筛选出对违约状态影响最显著的特征;
5. 模型开发:包括变量分段,变量的WOE变换和逻辑回归估计;
6. 模型评估:评估模型的区分能力、预测能力、稳定性,并形成模型评估报告;
7. 信用评分:根据逻辑回归的系数和WOE等确定信用评分方法,将Logistic模型转换为标准评分形式;
8. 建立评分系统:根据信用评分方法,建立自动信用评分系统。
(三)思路
学以致用,解决问题!
第一阶段:基于逻辑回归的贷款违约预测分析(机器学习中的分类学习思路)
第二阶段:基于WOE构建信用评分卡
二、基于逻辑回归的贷款违约预测分析
(一)思路
1. 读取数据,了解数据
2. 数据清洗(缺失、异常、重复值处理)
3. 数据探索分析(变量特征工程)
4. 变量处理与选择
5. 建模分析
(二)案例
1. 读取数据
# 读取数据
import pandas as pd
data = pd.read_csv("cs-training.csv")
data = data.iloc[:,1:] # 去掉第一列,也可以用drop
data.info() # 注意数据类型(int/float)、变量含义
# 简单查看数据
data.head() # 查看数据
data.describe() # 对数据进行简单描述统计2. 数据清洗
(1)缺失值处理——关键点:跟业务结合;没有统一标准
data.isnull().sum() # 缺失值统计
# 创建数据表,分析数据表
def draw_missing_data_table(df):
tatal = df.isnull().sum().sort_value(ascending = True)
percent = (df.isnull().sum()/df.isnull().count().sort_value(ascending = True))
missing_data = pd.concat([total, percent, axis=1, keys=["Total", "Percent"])
return missing_data
# 调用函数,统计缺失值
draw_missing_data_table(data)(1)缺失值处理——步骤
第一步:删除(数量比较少;绝对量和相对量,结合业务问题)
第二步:填充:任意值;均值;关系填充(根据业务问题)
例:人口普查age缺失,显然不能填任意值或均值,但可根据该人身份证、社会关系等业务信息进行填充。
# 填充MonthlyInccom,填充中位数
value = data.MonthlyIncome.median()
data.MonthlyIncome = data.MonthlyIncome.fillna(value)
# 填充NumberofDependents,没有家庭,填充0
data.NumberOfDependents = data.NumberOfDependents.fillna(0)
data.isnull().sum()
# 结果为0(2)重复值处理
data.duplicated().sum()
data = data.drop_duplicates()
data.info()(3)异常值处理——更多的是业务问题
方法:describe、箱线图
data.describe([0.01, 0.05, 0.10, 0.25, 0.50, 0.75, 0.90, 0.95, 0.99]) # 分别查看1%/5%/...99%分位数
# 作图导入库
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.boxplot(data["age"]) # 查看年龄的箱线图,发现有0岁、100多岁的异常值
# 一个一个变量作图过于繁琐,可利用for循环作图
data.colums # 查看变量
features = ["RevolvingUtilizationOfUnsecuredLines","age"...] # 将变量赋值于features
for i in features:
sns.boxplot(data[i])
plt.show()# 进行异常值删除
data = data[data["age"]>18]
data = data[data["age"]<100]
data = data[data["RevolvingUtilizationOfUnsecuredLines"]<1.00]
data = data[data["NumberOfOpenCreditLinesAndLoans"]<24.00]
data = data[data["NumberRealEstateLoansOrLines"]<4.00]
data = data[data["DebtRatio"]<5000.00]
data = data[data["NumberOfTime30-59DaysPastDueNotWorse"]<5000.00]
data.info()
# 保存处理后的数据
data.to_csv("processeddata.csv")3. 数据探索分析
(1)数据分布特征探索
sns.distplot(data["age"]) # 绘制分布图
sns.distplot(data["MonthlyIncome"]<10000) # 分布很离散,可以加个限定条件“<10000”查看分布情况(2)各个变量跟Y关系
count_classes = pd.value_counts(data["SeriousDlqin2yrs"], sort=True).sort_index()
count_classes
count_classes.plot(kind="bar")
# 查看age跟y关系
sns.boxplot(x="SeriousDlqin2yrs", y="age", data=data)
# 直接使用前面的features循环,查看所有变量与y的关系
for i in features:
sns.boxplot(x="SeriousDlqin2yrs", y=i, data=data)
plt.show()4. 特征工程(变量选择)
特征工程包括:虚拟化、标准化、变量生成、变量降维等。
下面使用相关系数进行变量选择。
data.corr() # 计算变量相关系数矩阵,查看各变量与y的相关系数
# 为了更好展示,可以做相关系数热力图
cor = data.corr()
plt.figure(figsize=(10,10)) # 调整图的大小
sns.heatmap(cor, annot=True, cmap="YlCnBu") # annot在每块上标上系数数值方便读,cmap调整颜色
# 根据相关系数>0.05,选择变量1,2,3,7,9;考虑变量自相关与过拟合问题,最终选择变量1,2,35. 建模分析
(1)划分X和Y,划分样本集
Y = data["SeriousDlqin2ys"]
X = data.iloc[:,[1,2,3]]
Y # 查看Y
X.head() # 查看Xfrom sklearn.model_selsction import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=0) # 设置random_state=0保证每次相同地方开始划分(2)模型建立
from sklearn.linear_model import LogisticRegression
lrmodel = LogisticRegression()
lrmodel.fit(X_train, Y_train) # 使用训练集数据拟合模型
lrmodel.coef_ # 查看各变量系数
lrmodel.intercept_ # 查看截距项系数(3)模型评估
Y_predict = lrmodel.predict(X_test) # 进行预测
Y_predict[0:20] # 查看前20个预测值
# 生成报告,查看模型效果
from sklearn.metrics import classification_report
report = classification_report(Y_test, Y_predict)
print(report)
# 查看ROC/AUC
from sklearn.metrics import accuracy_score, roc_auc_score
print(accuracy_score(Y_test, Y_predict))
print(roc_auc_score(Y_test, Y_predict))小结
后续问题:模型调整(1. 数据处理:WOE和IV变量选择建模;2. 参数调整)
三、基于WOE信用评分的逻辑回归模型建立信用评分卡
(一)步骤
1. 导入数据
2. 数据清洗
3. 数据探索分析
4. 特征工程(变量选择)【数据分箱——woe-iv-变量选择】
5. 建立逻辑回归模型
5.1 划分数据
5.2 数据转化【新增】
5.3 建立模型
5.4 评估模型
5.5 建立信用评分卡【新增】
(二)举例进行woe和iv值计算
| 变量 | 全称 | 含义 |
| WOE | Weight of Evidence | 自变量取某个值时对违约比例的一种影响 |
| IV | Information Value | 信息价值 |
1. 读取数据
import pandas as pd
data = pd.read_csv("processeddata.csv")
data.info()
# 读取发现多了一个Unamed,下面删去
data = data.iloc[:,1:]
data.info()2. 举例说明woe和iv值的计算
| 分箱方法 | |
| 等距分箱 | 距离相等,样本不相等 |
| 等深分箱 | 距离不相等,样本相等 |
分箱后得到:总数,好样本数,坏样本数,根据分箱后的结果计算woe,woe公式如下:
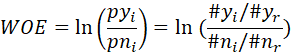
WOE数值有什么问题? 1. 有正有负; 2. 不好理解
因此下面计算IV值:
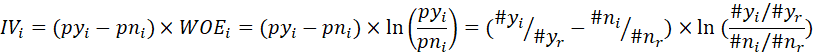

IV值有什么好处:1. 都是正数; 2. 好理解,越大越好
(1)数据分箱
data["age"].head()
data_cut = pd.cut(data["age"],10) # 等距分箱,分4类
data_cut(2)数据分箱后计算样本数/坏样本数/好样本数
# 统计总样本数
cut_group_all = data["SeriousDlqin2yrs"].groupby(data_cut).count()
# 统计坏样本数
cut_y = data["SeriousDlqin2yrs"].groupby(data_cut).sum() # 坏的就是违约了“yes”,即“y”;违约了是“1”,没违约的是“0”,直接用sum加总就可以得到
# 统计好样本数
cut_n = cut_group_all-cut_y # normal正常,好的就是总的减去坏的
# 汇总数据
df = pd.DateFrame()
df["总数"] = cut_group_all
df["坏样本数"] = cut_y
df["好样本数"] = cut_n
df(3)数据分箱以后计算坏样本比率和好样本比率(并非比例)
df["坏样本比率"] = df["坏样本数"]/df["坏样本数"].sum()
df["好样本比率"] = df["好样本数"]/df["好样本数"].sum()
df(4)计算WOE值
import numpy as np
df["WOE的值"] = np.log(df["坏样本比率"]/df["好样本比率"])
df
# 注意一个问题:如果出现∞,需要以0进行替换
df = df.replace(["WOE的值":[np.inf:0, -inf:0]])(5)计算IV的值
df["IV的值"] = df["WOE的值"]*(df["坏样本比率"]-df["好样本比率"])
dfage_IV = df["IV的值"].sum()
age_IV(三)根据woe和iv值进行变量选择
1. 构建函数进行woe和iv值计算
from sklearn.model_selsction import train_test_split
Y = data["SeriousDlqin2ys"]
X = data,iloc[:,1:]
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=0) # 设置random_state=0保证每次相同地方开始划分
train = pd.concat([Y_train, X_train], axis=1)
test = pd.concaat([Y_test, X_test], axis=1)
train.to_csv("TrainData.csv", index=False)
test.to_csv("TestData.csv", index=False)from sklearn.model_selsction import train_test_split
Y = data["SeriousDlqin2ys"]
X = data,iloc[:,1:]
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=0) # 设置random_state=0保证每次相同地方开始划分
train = pd.concat([Y_train, X_train], axis=1)
test = pd.concaat([Y_test, X_test], axis=1)
train.to_csv("TrainData.csv", index=False)
test.to_csv("TestData.csv", index=False)import scipy.stats as stats
import numpy as np
# 根据r,p划分
def mono_bin(Y,X,n=20):
bad = Y.sum()
good = Y.count()-bad
r = 0
while np.abs(r) < 1:
d1 = pd.DataFrame(['X':X, 'Y':Y, 'Bucket':pd.cut(X, n, duplicate="drop")])
d2 = d1.groupby(['Bucket'], as_index=True)
r,p = stats.spearmanr(d2['X'].mean(), d2['Y'].mean()) # spearman秩相关系数是度量两个变量之间的统计相关性的指标
n = n-1
d3 = pd.DataFrame(d2['X'].min(), columns=['min']) # 为什么是空表
d3['min'] = d2['X'].min()
d3['max'] = d2['X'].max()
d3['sum'] = d2['Y'].sum()
d3['total'] = d2['Y'].count()
d3['rate'] = d2['Y'].mean()
d3['badattribute'] = d3['sum'] / bad
d3['goodattribute'] = (d3['total'] - d3['sum']) / good
d3['woe'] = np.log(d3['badattribute'] / d3['goodattribute'])
iv = ((d3['badattribute'] - d3['goodattribute']) * d3['woe']).sum()
d4 = (d3.sort_values(by = 'min'))
woe = list(d4['voe'].value)
print(d4)
print('-' * 30)
# 根据分位数进行切分
cut = []
cut.append(float('-inf'))
for i in range(1,n+1):
qua = X.quantile(i/(n+1)) # quantile求分位数,pos = (n+1)*p,n为数据的总个数,p为0-1之间的值
cut.append(round(qua,4)) # round()方法返回浮点数x的四舍五入值
cut.append(float('inf'))
return d4,iv,woe,cutdfx1, ivx1, woex1, cutx1 = mono_bin(train['SeriousDlqin2yrs'], train['RevolvingUtilizationOfUnsecuredLines'], n=10)
dfx2, ivx2, woex2, cutx2 = mono_bin(train['SeriousDlqin2yrs'], train['age'], n=20)
dfx4, ivx4, woex4, cutx4 = mono_bin(train['SeriousDlqin2yrs'], train['DebtRatio'], n=10)
dfx5, ivx5, woex5, cutx5 = mono_bin(train['SeriousDlqin2yrs'], train['MonthlyIncome'], n=10)# 剩下的几个变量不连续,人工定义
# 针对不能最优分箱的变量
def self_bin(Y, X, cat):
bad = Y.sum()
good = Y.count() - bad
d1 = pd.DataFrame(['X':X, 'Y':Y, 'Bucket':pd.cut(X, cat)])
d2 = d1.groupby(['Bucket'], as_index=True)
d3 = pd.DataFrame(d2['X'].min(), columns=['min'])
d3['min'] = d2['X'].min()
d3['max'] = d2['X'].max()
d3['sum'] = d2['Y'].sum()
d3['total'] = d2['Y'].count()
d3['rate'] = d2['Y'].mean()
d3['badattribute'] = d3['sum'] / bad
d3['goodattribute'] = (d3['total'] - d3['sum']) / good
# d3['woe'] = np.log((d3['rate'] / (1 - d3['rate'])) / (bad / good))
d3['woe'] = np.log(d3['badattribute'] / d3['goodattribute'])
iv = ((d3['badattribute'] - d3['goodattribute']) * d3['woe']).sum()
d4 = (d3.sort_values(by = 'min'))
woe = list(d4['voe'].value)
print(d4)
print('-' * 30)
woe = list(d3['woe'].values)
return d4, iv, woe
# 自己定义cut
ninf = float('-inf')
pinf = float('inf')
cutx3 = [ninf, 0, 1, 3, 5, pinf]
cutx6 = [ninf, 1, 2, 3, 5, pinf]
cutx7 = [ninf, 0, 1, 3, 5, pinf]
cutx8 = [ninf, 0, 1, 2, 3, pinf]
cutx9 = [ninf, 0, 1, 3, pinf]
cutx10 = [ninf, 0, 1, 2, 3, 5, pinf]
dfx3, ivx3, woex3 = self_bin(train['SeriousDlqin2yrs'], train['NumberOfTime30-59DaysPastDueNotWorse'], cutx3)
dfx6, ivx6, woex6 = self_bin(train['SeriousDlqin2yrs'], train['NumberOfOpenCreditLinesAndLoans'], cutx6)
dfx7, ivx7, woex7 = self_bin(train['SeriousDlqin2yrs'], train['NumberOfTimes90DayLate'], cutx7)
dfx8, ivx8, woex8 = self_bin(train['SeriousDlqin2yrs'], train['NumberRealEstateLoansOrLines'], cutx8)
dfx9, ivx9, woex9 = self_bin(train['SeriousDlqin2yrs'], train['NumberOfTime60-89DaysPastDueNotWorse'], cutx9)
dfx10, ivx10, woex10 = self_bin(train['SeriousDlqin2yrs'], train['NumberOfDependents'], cutx10)2. 变量选择
import matplotlib.pyplot as plt
%matplotlib inline
ivall = pd.Series([ivx1, ivx2, ivx3, ivx4, ivx5, ivx6, ivx7, ivx8, ivx9, ivx10])
ivall.plot(kind = "bar")
plt.show()根据IV值选择变量1,2,3,7,9
3. 建模分析
(1)划分数据集(已完成)
(2)WOE转换
# WOE转换函数
from pandas import Series
def replace_woe(series, cut, woe):
list = []
i = ()
while i < len(series):
value = series[i]
j = len(cut) - 2
m = len(cut) - 2
while j >= 0:
if value >=cut[j]
j = -1
else:
j -= 1
m -= 1
list.append(woe[m])
i += 1
return listtrain = pd.read_csv("TrainData.csv")
train['RevolvingUtilizationOfUnsecuredLines'] = Series(replace_woe(train['RevolvingUtilizationOfUnsecuredLines'], cutx1, woex1))
train['age'] = Series(replace_woe(train['age'], cutx2, woex2))
train['NumberOfTime30-59DaysPastDueNotWorse'] = Series(replace_woe(train['NumberOfTime30-59DaysPastDueNotWorse'], cutx3, woex3))
train['DebtRatio'] = Series(replace_woe(train['DebtRatio'], cutx4, woex4))
train['MonthlyIncome'] = Series(replace_woe(train['MonthlyIncome'], cutx5, woex5))
train['NumberOfOpenCreditLinesAndLoans'] = Series(replace_woe(train['NumberOfOpenCreditLinesAndLoans'], cutx6, woex6))
train['NumberOfTimes90DaysLate'] = Series(replace_woe(train['NumberOfTimes90DaysLate'], cutx7, woex7))
train['NumberRealEstateLoansOrLines'] = Series(replace_woe(train['NumberRealEstateLoansOrLines'], cutx8, woex8))
train['NumberOfTime60-89DaysPastDueNotWorse'] = Series(replace_woe(train['NumberOfTime60-89DaysPastDueNotWorse'], cutx9, woex9))
train['NumberOfDependents'] = Series(replace_woe(train['NumberOfDependents'], cutx10, woex10))
train.info()test = pd.read_csv("TestData.csv")
test['RevolvingUtilizationOfUnsecuredLines'] = Series(replace_woe(test['RevolvingUtilizationOfUnsecuredLines'], cutx1, woex1))
test['age'] = Series(replace_woe(test['age'], cutx2, woex2))
test['NumberOfTime30-59DaysPastDueNotWorse'] = Series(replace_woe(test['NumberOfTime30-59DaysPastDueNotWorse'], cutx3, woex3))
test['DebtRatio'] = Series(replace_woe(test['DebtRatio'], cutx4, woex4))
test['MonthlyIncome'] = Series(replace_woe(test['MonthlyIncome'], cutx5, woex5))
test['NumberOfOpenCreditLinesAndLoans'] = Series(replace_woe(test['NumberOfOpenCreditLinesAndLoans'], cutx6, woex6))
test['NumberOfTimes90DaysLate'] = Series(replace_woe(test['NumberOfTimes90DaysLate'], cutx7, woex7))
test['NumberRealEstateLoansOrLines'] = Series(replace_woe(test['NumberRealEstateLoansOrLines'], cutx8, woex8))
test['NumberOfTime60-89DaysPastDueNotWorse'] = Series(replace_woe(test['NumberOfTime60-89DaysPastDueNotWorse'], cutx9, woex9))
test['NumberOfDependents'] = Series(replace_woe(test['NumberOfDependents'], cutx10, woex10))
test.info()
3. 建模分析
Y_train = train["SeriousDlqin2ys"]
X_train = train.iloc[:,[1,2,3,7,9]]
Y_test = test["SeriousDlqin2ys"]
X_test = test.iloc[:,[1,2,3,7,9]]from sklearn.linear_model import LogisticRegression
woelr = LogisticRegression()
woelr.fit(X_train, Y_train) # 使用训练集数据拟合模型woelr.coef_ # 查看各变量系数
woelr.intercept_ # 查看截距项系数4. 模型评估
Y_pred = woelr.predict(X_test) # 进行预测
Y_pred[0:20] # 查看前20个预测值
# 生成报告,查看模型效果
from sklearn.metrics import classification_report
report = classification_report(Y_test, Y_pred)
print(report)
# 查看ROC/AUC
from sklearn.metrics import accuracy_score, roc_auc_score
print(accuracy_score(Y_test, Y_pred))
print(roc_auc_score(Y_test, Y_pred))5. 建立信用评分卡
Logistics模型转换为标准评分卡,根据相关论文理论:
每个属性对应的分值可以通过下面的公式计算;WOE乘该变量的回归系数,加上回归截距,再乘上比例因子,最后加上偏移量:
![]()
对于评分卡的分值,我们可以这样计算:

即:a = log(p_good/p_bad) Score = offset + factor*log(odds)

建立标准评分卡之前需要选取几个评分卡参数:基础分值、PDO(比率翻倍的分值)和好坏比。此处,基础分值取600分,PDO为20(每高20分好坏比翻一倍),好坏比取20。
个人总评分 = 基础分 + 各部分得分
import numpy as np
factor = 20 / np.log(2)
# 计算分数函数
def get_score(coe, woe, factor):
score = []
for w in woe:
score = round(coe*w*factor, 0)
scores.append(score)
return scores
# coe 即前面计算的 woelr.coef()
coe = [0.66005628, 0.54226153, 1.05903419, 1.93717555, 1.20941815]
# 计算每个变量得分
x1 = get_score(coe[0], woex1, factor)
x2 = get_score(coe[1], woex2, factor)
x3 = get_score(coe[2], woex3, factor)
x7 = get_score(coe[3], woex7, factor)
x9 = get_score(coe[4], woex9, factor)
# 打印出每个特征对应的分数
print("可用额度比值对应的分数:[]", format(x1))
print("年龄对应的分数:[]", format(x2))
print("逾期30-59天笔数对应的分数:[]", format(x3))
print("逾期90天笔数对应的分数:[]", format(x7))
print("逾期60-89天笔数对应的分数:[]", format(x9))
# 定义函数,根据变量计算分数
def compute_score(series, cut, scores):
i = 0
list = []
while i < len(series)
value = series[i]
j = len(cut) - 2
m = len(cut) - 2
while j >= 0:
if value >= cut[j]
j = -1
else:
j = j-1
m = m-1
list.append(score[m])
i = i+1
return list
# 对测试集进行得分判断
test1 = pd.read_csv('TestData.csv')
test1['BaseScore'] = 600
test1['x1'] = Series(compute_score(test1['RevolvingUtilizationOfUnsecuredLines'], cutx1, x1))
test1['x2'] = Series(compute_score(test1['age'], cutx2, x2))
test1['x3'] = Series(compute_score(test1['NumberOfTime30-59DaysPastDueNotWorse'], cutx3, x3))
test1['x7'] = Series(compute_score(test1['NumberOfTimes90DaysLate'], cutx7, x7))
test1['x9'] = Series(compute_score(test1['NumberOfTime60-89DaysPastDueNotWorse'], cutx9, x9))
test1['score'] = test1['x1'] + test1['x2'] + test1['x3'] + test1['x7'] + test1['x9'] + test1['BaseScore']
test1.to_csv("ScoreData.csv", index=False)
test2 = test1.iloc[:,[0,11,12,13,14,15,16,17]]
test2.head()四、总结
(一)重点
1. 逻辑回归的思路;
2. 基于WOE逻辑回归建立信用评分卡的思路;
3. 过程中结合思路,对相关知识点进行掌握,重在操作。
(二)改进
1. 数据处理和样本处理、参数调整等较少;
2. 没有对测试数据进行分析,思路三部曲(训练模型,用有Y的测试数据进行测试然后不断完善模型,实战应用cs-test.csv)。