逻辑回归模型:信用卡欺诈分析
逻辑回归案例分析——信用卡欺诈
本次案例为信用卡欺诈数据,一共包含31个自变量,其中因变量Class表示用户在交易中是否发生欺诈行为(1表示欺诈交易,0表示正常交易)。由于数据涉及敏感信息,其中V1~V28自变量做了标准化处理。本次案例涉及到分类问题中类别比例严重失调的情况下应该如何应对,当然主要任务是对0-1样本即正常与异常样本的区分。
- 类别比例失调如何处理
- 正负样本的划分
首先是库的导入操作:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
data = pd.read_csv("creditcard.csv")
data.head(5)
| Time | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | ... | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Amount | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | -1.359807 | -0.072781 | 2.536347 | 1.378155 | -0.338321 | 0.462388 | 0.239599 | 0.098698 | 0.363787 | ... | -0.018307 | 0.277838 | -0.110474 | 0.066928 | 0.128539 | -0.189115 | 0.133558 | -0.021053 | 149.62 | 0 |
| 1 | 0.0 | 1.191857 | 0.266151 | 0.166480 | 0.448154 | 0.060018 | -0.082361 | -0.078803 | 0.085102 | -0.255425 | ... | -0.225775 | -0.638672 | 0.101288 | -0.339846 | 0.167170 | 0.125895 | -0.008983 | 0.014724 | 2.69 | 0 |
| 2 | 1.0 | -1.358354 | -1.340163 | 1.773209 | 0.379780 | -0.503198 | 1.800499 | 0.791461 | 0.247676 | -1.514654 | ... | 0.247998 | 0.771679 | 0.909412 | -0.689281 | -0.327642 | -0.139097 | -0.055353 | -0.059752 | 378.66 | 0 |
| 3 | 1.0 | -0.966272 | -0.185226 | 1.792993 | -0.863291 | -0.010309 | 1.247203 | 0.237609 | 0.377436 | -1.387024 | ... | -0.108300 | 0.005274 | -0.190321 | -1.175575 | 0.647376 | -0.221929 | 0.062723 | 0.061458 | 123.50 | 0 |
| 4 | 2.0 | -1.158233 | 0.877737 | 1.548718 | 0.403034 | -0.407193 | 0.095921 | 0.592941 | -0.270533 | 0.817739 | ... | -0.009431 | 0.798278 | -0.137458 | 0.141267 | -0.206010 | 0.502292 | 0.219422 | 0.215153 | 69.99 | 0 |
5 rows × 31 columns
数据集检测
在本案例中是的数据集是是否有信用卡欺诈的数据集,结合实际情况,应该是正常类占绝大多数,出现信用卡欺诈的类别占少数的,首先我们需要对我们的数据进行检验,看是否满足这样的特征
pd.value_counts()对DataFrame的某一列中具有多少重复的值进行统计,并对不同的值进行计数。使用的时候需要对特定的列进行指定,比如下面的使用中指定了Class列,并且进行排序。
#使用注释掉的代码可以直接输出列的情况:
# print(data["Class"].value_counts())
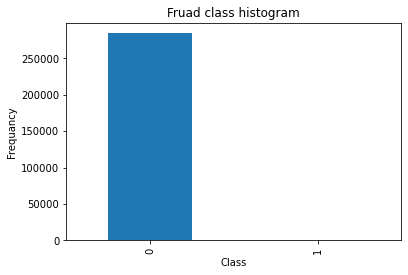
count_classes = pd.value_counts(data["Class"], sort = True).sort_index()
count_classes.plot(kind = "bar")
plt.title("Fruad class histogram")
plt.xlabel("Class")
plt.ylabel("Frequancy")
Text(0, 0.5, 'Frequancy')
样本数量均衡化处理
可以看出正常样本的数量时明显多于异常样本的,即样本的数据是极度不均衡的,需要进行处理。
面对数据不均衡时我们往往采取两种解决方法:
- 过采样:对少数样本进行数据生成,使少数的样本变得与多数样本数量相当
- 下采样:在多数的样本中取出和少数样本规模相同的子样本作为分类的数据对象,这样使得两个样本同样的少
后面会针对两种不同的方法分别进行分析
样本特征的归一化处理
此外,在上面的数据中我们也可以发现Amount列的数据的大小浮动是比较大的,有的是几百,有的数据是个位数,amount和前面的V1-V28这些特征在未说明的情况下对结果产生的影响是相当的,如果不进行处理,机器学习算法的结果可能对较大的数予以较大的权重赋值,进入误区。所以在机器学习中我们要保证特征之间的分布差异处于一个相当的范围内。
比如我们可以看到前面的V1-V28这些特征,他们大概分布在-1-1这样的区间内,所以我们最好也要对amount的数值进行归一化处理。
from sklearn.preprocessing import StandardScaler
#生成新的特征
data['normAmount'] = StandardScaler().fit_transform(data['Amount'].values.reshape(-1, 1))
#去除不需要的特征
data = data.drop(["Time", "Amount"], axis=1)
data.head()
| V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | ... | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Class | normAmount | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -1.359807 | -0.072781 | 2.536347 | 1.378155 | -0.338321 | 0.462388 | 0.239599 | 0.098698 | 0.363787 | 0.090794 | ... | -0.018307 | 0.277838 | -0.110474 | 0.066928 | 0.128539 | -0.189115 | 0.133558 | -0.021053 | 0 | 0.244964 |
| 1 | 1.191857 | 0.266151 | 0.166480 | 0.448154 | 0.060018 | -0.082361 | -0.078803 | 0.085102 | -0.255425 | -0.166974 | ... | -0.225775 | -0.638672 | 0.101288 | -0.339846 | 0.167170 | 0.125895 | -0.008983 | 0.014724 | 0 | -0.342475 |
| 2 | -1.358354 | -1.340163 | 1.773209 | 0.379780 | -0.503198 | 1.800499 | 0.791461 | 0.247676 | -1.514654 | 0.207643 | ... | 0.247998 | 0.771679 | 0.909412 | -0.689281 | -0.327642 | -0.139097 | -0.055353 | -0.059752 | 0 | 1.160686 |
| 3 | -0.966272 | -0.185226 | 1.792993 | -0.863291 | -0.010309 | 1.247203 | 0.237609 | 0.377436 | -1.387024 | -0.054952 | ... | -0.108300 | 0.005274 | -0.190321 | -1.175575 | 0.647376 | -0.221929 | 0.062723 | 0.061458 | 0 | 0.140534 |
| 4 | -1.158233 | 0.877737 | 1.548718 | 0.403034 | -0.407193 | 0.095921 | 0.592941 | -0.270533 | 0.817739 | 0.753074 | ... | -0.009431 | 0.798278 | -0.137458 | 0.141267 | -0.206010 | 0.502292 | 0.219422 | 0.215153 | 0 | -0.073403 |
5 rows × 30 columns
下采样处理
减少多数的样本以和少数的样本的数量一样多
#取出特征列
X = data.iloc[:,data.columns != "Class"]
#取出标签列
y = data.iloc[:,data.columns == "Class"]
#Number of data points in the minority class
# 得到不正常样本的索引值和数量
number_records_fraud = len(data[data.Class == 1])
fraud_indices =np.array(data[data.Class == 1].index)
#在正常样本中进行随机选择
normal_indices = data[data.Class == 0].index
#基于我们上一步找出来的那些样本的下标,在这些下标中随机选择出number_records_fraud数量的下标,并转换成ndarray对象
random_normal_indices = np.random.choice(normal_indices, number_records_fraud, replace = False)
# replace = False 形成的数据不能有重复的
random_normal_indices = np.array(random_normal_indices)
#将两部分的下标粘合在一起,形成整体的新的样本的下标
under_sample_indices = np.concatenate([fraud_indices,random_normal_indices])
# 根据索引,得到下采样的数据集(根据下标取行)
under_sample_data = data.iloc[under_sample_indices,:]
#选取最终的特征列和标签列
X_undersample = under_sample_data.iloc[:,under_sample_data.columns != "Class"]
y_undersample = under_sample_data.iloc[:,under_sample_data.columns == "Class"]
# 展示下采样样本比例
print("正常样本占下采样样本的比例:",len(under_sample_data[under_sample_data.Class == 0]) / len(under_sample_data))
print("异常样本占下采样样本的比例:",len(under_sample_data[under_sample_data.Class == 1]) / len(under_sample_data))
print("下采样样本总数:",len(under_sample_data))
正常样本占下采样样本的比例: 0.5
异常样本占下采样样本的比例: 0.5
下采样样本总数: 984
训练集和测试集的划分以及交叉验证
训练集和测试集划分
经过上面的操作我们已经得到了需要处理的一系列的数据,下面我们要做的就是数据集和测试集的划分的过程了。
所谓的划分就是要把样本分为数据集和测试集两个部分
- 数据集:用来建立我们的回归模型
- 测试集:用来验证建立模型的准确性
注意的是数据集和测试集的选择要随机且采用同一选择的算法。
交叉验证
交叉验证是指我们要将数据集进行进一步的划分,这样进一步的划分内进行互相组合,记录结果以更好地选择模型中的参数。
具体的操作见下面的过程:
原始测试集进行测试
from sklearn.model_selection import train_test_split
#导入原始数据集进行一个切分的操作,这种切分是经过洗牌的切分的
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state = 0)
print("原始训练集包含样本数量:", len(X_train))
print("原始测试集包含样本数量:", len(X_test))
print("原始样本总数:",len(X_train)+len(X_test))
#导入下采样数据集进行切分操作
X_train_undersample, X_test_undersample, y_train_undersample, y_test_undersample = train_test_split(X_undersample, y_undersample,
test_size=0.3, random_state = 0)
print("")
print("下采样训练集包含样本数量:", len(X_train_undersample))
print("下采样测试集包含样本数量:", len(X_test_undersample))
print("下采样样本总数:",len(X_train_undersample)+len(X_test_undersample))
原始训练集包含样本数量: 199364
原始测试集包含样本数量: 85443
原始样本总数: 284807
下采样训练集包含样本数量: 688
下采样测试集包含样本数量: 296
下采样样本总数: 984
模型的评估
召回率:recall
如何评价我们建立模型的好坏,直接的想法是使用精度来判断。下面我们举一个例子说明精度判断的局限性,
有上面的例子可以知道精度评估具有一定的欺骗性,所以这里我们引入“召回率”:recall的概念,来对我们模型的好坏进行评估
R e c a l l = T P ( T P + F N ) Recall =\frac{ TP}{ (TP + FN)} Recall=(TP+FN)TP
正则化惩罚
假如我们得到了模型A( θ 1 , θ 2 , θ 3 , . . . , θ 10 \theta_1,\theta_2,\theta_3,...,\theta_{10} θ1,θ2,θ3,...,θ10)和模型B( θ 1 , θ 2 , θ 3 , . . . , θ 10 \theta_1,\theta_2,\theta_3,...,\theta_{10} θ1,θ2,θ3,...,θ10)两个模型,两个模型经过召回率的评估结果是一样的,那么我们在选择的时候是不是在A和B两个模型中随意选择一个就可以了呢?
这里我们还要考虑A和B得到的参数( θ 1 , θ 2 , θ 3 , . . . , θ 10 \theta_1,\theta_2,\theta_3,...,\theta_{10} θ1,θ2,θ3,...,θ10)的正则化问题,要考虑这组参数的波动程度。一般情况下我们认为波动程度更小的参数组合的模型更好,因为这样的模型泛化程度更高,能过减小过拟合的现象。
所谓的过拟合是指我们的模型在训练集上的发挥是很好的,但是在测试集上的效果不是很好,过拟合现象在机器学习的算法中经常出现,需要避免。
对于正则化惩罚的方法这里介绍一种 L 2 L_2 L2惩罚法。在未引入这个概念之前我们我们对于模型的建立的过程是要经过梯度下降的过程,使损失函数loss达到最小值,而现在我们引入了正交惩罚这个概念,在损失函数loss的基础上添加了 1 2 ω 2 \frac{1}{2}\omega^2 21ω2,即添加了正则系数。我们现在的目标不是仅仅使损失函数 l o s s loss loss达到最小值了,我们的目标是要经过梯度下降使 l o s s + 1 2 ω 2 loss+\frac{1}{2}\omega^2 loss+21ω2达到最小值,这就是正则化惩罚的过程。
此外还有一种 L 1 L_1 L1正则化惩罚的方式,是加上 ∣ ω ∣ |\omega| ∣ω∣
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold, cross_val_score
from sklearn.metrics import confusion_matrix, recall_score, classification_report
def printing_Kfold_scores(x_train_data, y_train_data):
#表示进行k折的交叉验证
fold = KFold(5, shuffle = False)
#惩罚项的不同的权重
c_param_range = [0.01, 0.1, 1, 10, 100]
#展示结果所用的表格,5行2列,来存储不同的参数进行交叉验证的召回率
result_table = pd.DataFrame(index = range(len(c_param_range), 2), columns = ["C_parameter","Mean recall score"])
result_table["C_parameter"] = c_param_range
j = 0
# 外层循环:寻找最佳的惩罚项的权重:
for c_param in c_param_range:
print("-------------------------------------------")
print("C parameter:", c_param)
print("-------------------------------------------")
print(" ")
recall_accs = []
#内层循环:进行交叉验证
for iteration, indices in enumerate(fold.split(x_train_data),start=1):
#iteration:i值,第i次交叉验证;indices:两个索引集合,训练集 = indices[0],验证集 = indices[1]
#enumerate():用于将一个可比案例的数据对象组合为一个索引序列,将fold和下标组合成一个索引序列
#【建立逻辑回归模型】,传入惩罚项权重和惩罚方式,这里选择L1惩罚
lr = LogisticRegression(C = c_param, penalty = "l1", solver="liblinear")
#使用训练集(索引是0)【训练模型】
lr.fit(x_train_data.iloc[indices[0],:], y_train_data.iloc[indices[0],:].values.ravel())
#建立好模型后用测试集去预测模型结果
y_pred_undersample = lr.predict(x_train_data.iloc[indices[1],:].values)
#评估分类结果,计算召回率
recall_acc = recall_score(y_train_data.iloc[indices[1],:].values, y_pred_undersample)#计算一次召回率
recall_accs.append(recall_acc)#把五次的召回率的结果和在一起,以便后续求平均值
print("Iteration ", iteration,":召回率=", recall_acc)
#当执行完所有的交叉验证后,计算每个参数c对应的平均召回率并打印
result_table.loc[j,"Mean recall score"] = np.mean(recall_accs)
j +=1
print("")
print("平均召回率:",np.mean(recall_accs))
print("")
best_c = result_table.loc[result_table["Mean recall score"].astype(float).idxmax()]["C_parameter"]
#打印出最好的结果:
print("*********************************************************************************")
print("效果最好的模型所选的惩罚参数C是:", best_c)
print("*********************************************************************************")
return best_c
best_c = printing_Kfold_scores(X_train_undersample, y_train_undersample)
-------------------------------------------
C parameter: 0.01
-------------------------------------------
Iteration 1 :召回率= 0.9315068493150684
Iteration 2 :召回率= 0.9178082191780822
Iteration 3 :召回率= 1.0
Iteration 4 :召回率= 0.9594594594594594
Iteration 5 :召回率= 0.9545454545454546
平均召回率: 0.9526639964996129
-------------------------------------------
C parameter: 0.1
-------------------------------------------
Iteration 1 :召回率= 0.8493150684931506
Iteration 2 :召回率= 0.863013698630137
Iteration 3 :召回率= 0.9491525423728814
Iteration 4 :召回率= 0.9324324324324325
Iteration 5 :召回率= 0.8939393939393939
平均召回率: 0.897570627173599
-------------------------------------------
C parameter: 1
-------------------------------------------
Iteration 1 :召回率= 0.863013698630137
Iteration 2 :召回率= 0.9041095890410958
Iteration 3 :召回率= 0.9491525423728814
Iteration 4 :召回率= 0.9459459459459459
Iteration 5 :召回率= 0.9090909090909091
平均召回率: 0.9142625370161939
-------------------------------------------
C parameter: 10
-------------------------------------------
Iteration 1 :召回率= 0.863013698630137
Iteration 2 :召回率= 0.9041095890410958
Iteration 3 :召回率= 0.9661016949152542
Iteration 4 :召回率= 0.9459459459459459
Iteration 5 :召回率= 0.9090909090909091
平均召回率: 0.9176523675246685
-------------------------------------------
C parameter: 100
-------------------------------------------
Iteration 1 :召回率= 0.863013698630137
Iteration 2 :召回率= 0.9041095890410958
Iteration 3 :召回率= 0.9661016949152542
Iteration 4 :召回率= 0.9459459459459459
Iteration 5 :召回率= 0.9090909090909091
平均召回率: 0.9176523675246685
*********************************************************************************
效果最好的模型所选的惩罚参数C是: 0.01
*********************************************************************************
模型的测试
绘制混淆矩阵
#绘制混淆矩阵函数(cm:计算出的混淆矩阵的值,classes:标签分类, title:标题,cmp:绘图样式)
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
plt.imshow(cm,cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
使用下采样数据集测试下采样方案
上述的探索已经得出了最佳的惩罚权重值,best_c,这里直接使用best_c作为惩罚项的权重系数,进行回归预测,并用混淆矩阵进行结果展示
import itertools
lr = LogisticRegression(C = best_c, penalty = 'l1', solver = "liblinear")
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
y_pred_undersample = lr.predict(X_test_undersample.values)
cnf_matrix = confusion_matrix(y_test_undersample, y_pred_undersample)#计算混淆矩阵所需值
np.set_printoptions(precision=2)#设置精度为小数点后两位
#使用公式进行召回率的计算
print("测试集中的召回率为:",cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
#绘图
class_names = [0,1]
plt.figure()#画图前先设置好画布
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
测试集中的召回率为: 0.9387755102040817
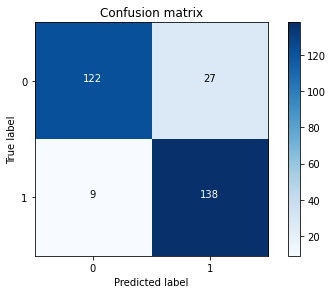
上面的情况是对下采样样本的测试集进行测试的结果,是理想情况下的判断结果。而实际我们应该是用整个样本的测试集对模型进行测试,下面我们进行用整个模型的测试集测试,检验一下下采样模型的可靠性:
用原始测试集测试下采样
lr = LogisticRegression(C = best_c, penalty = 'l1',solver = "liblinear")
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
y_pred = lr.predict(X_test.values)
# Compute confusion matrix
cnf_matrix = confusion_matrix(y_test,y_pred)
np.set_printoptions(precision=2)
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
Recall metric in the testing dataset: 0.9115646258503401
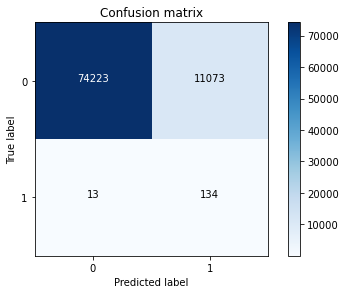
根据上述的结果,可以看出在下采样的处理方法下,在测试集数据量增大的情况下,召回率的结果并没有太大的变化,但是可以看到正常数据被误判成异常数据的比例较高,即假阳性太多,需要做出改进。
下采样方法的改进
①不进行采样,直接使用原数据集进行模型的建立与预测
best_c = printing_Kfold_scores(X_train,y_train)
-------------------------------------------
C parameter: 0.01
-------------------------------------------
Iteration 1 :召回率= 0.4925373134328358
Iteration 2 :召回率= 0.6027397260273972
Iteration 3 :召回率= 0.6833333333333333
Iteration 4 :召回率= 0.5692307692307692
Iteration 5 :召回率= 0.45
平均召回率: 0.5595682284048672
-------------------------------------------
C parameter: 0.1
-------------------------------------------
Iteration 1 :召回率= 0.5671641791044776
Iteration 2 :召回率= 0.6164383561643836
Iteration 3 :召回率= 0.6833333333333333
Iteration 4 :召回率= 0.5846153846153846
Iteration 5 :召回率= 0.525
平均召回率: 0.5953102506435158
-------------------------------------------
C parameter: 1
-------------------------------------------
Iteration 1 :召回率= 0.5522388059701493
Iteration 2 :召回率= 0.6164383561643836
Iteration 3 :召回率= 0.7166666666666667
Iteration 4 :召回率= 0.6153846153846154
Iteration 5 :召回率= 0.5625
平均召回率: 0.612645688837163
-------------------------------------------
C parameter: 10
-------------------------------------------
Iteration 1 :召回率= 0.5522388059701493
Iteration 2 :召回率= 0.6164383561643836
Iteration 3 :召回率= 0.7333333333333333
Iteration 4 :召回率= 0.6153846153846154
Iteration 5 :召回率= 0.575
平均召回率: 0.6184790221704963
-------------------------------------------
C parameter: 100
-------------------------------------------
Iteration 1 :召回率= 0.5522388059701493
Iteration 2 :召回率= 0.6164383561643836
Iteration 3 :召回率= 0.7333333333333333
Iteration 4 :召回率= 0.6153846153846154
Iteration 5 :召回率= 0.575
平均召回率: 0.6184790221704963
*********************************************************************************
效果最好的模型所选的惩罚参数C是: 10.0
*********************************************************************************
可以看出由于原始数据严重的不平衡,所以召回率较低,由此,对于数据进行下采样处理,进行平衡化是很有必要的。
下面我们通过混淆矩阵来观察直接用原数据集处理的效果。
lr = LogisticRegression(C = best_c, penalty = 'l1',solver = "liblinear")
lr.fit(X_train,y_train.values.ravel())
y_pred = lr.predict(X_test.values)
# Compute confusion matrix
cnf_matrix = confusion_matrix(y_test,y_pred)
np.set_printoptions(precision=2)
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
Recall metric in the testing dataset: 0.6190476190476191
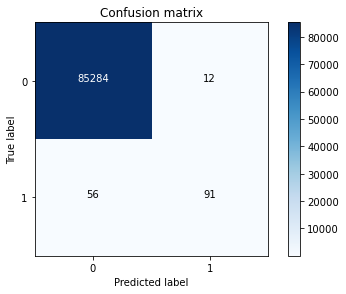
由上述结果可以看出,直接使用原数据集进行模型的训练,测试结果中的假阳性变少,但是对应的召回率较低,其实很多的异常数据没有找到,模型仍需改进。
下面使用过采样的方式对模型进行训练分析。
法②改变判断的阈值的方式
在模型的默认参数中,我们认为概率大于0.5为A类,概率小于0.5为B类。这个0.5被称为阈值,但是他是可以手动进行调整的,所以下面我们对模型的阈值thresh进行人为地设定,再分别进行模型的召回率计算和检验
#建模
lr = LogisticRegression(C = 0.01, penalty = 'l1', solver = "liblinear")
lr.fit(X_train_undersample,y_train_undersample.values.ravel())#仍采用下采样的数据进行模型训练
y_pred_undersample_proba = lr.predict_proba(X_test_undersample.values)#利用predict_prob得到预测结果的概率值
#之前的predict()函数是会直接得到0-1的类别的,现在我们得到的是一个概率值,用这个得到的概率与thresholds作比较
#设置不同的阈值
thresholds = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
plt.figure(figsize=(10,10)) #设置画布大小
j=1
for i in thresholds:
y_test_predictions_high_recall = y_pred_undersample_proba[:,1] > i#将概率值转化,判断(以0.5为例),大于0.5是异常,小于0.5是正常
plt.subplot(3,3,j) #3*3的子图, j表示第几个图,每张图对应一个阈值
j +=1
#计算混淆矩阵所需值
cnf_matrix = confusion_matrix(y_test_undersample,y_test_predictions_high_recall)
np.set_printoptions(precision=2)
print("测试集的召回率:",cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
#绘图
class_names = [0,1]
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Thresholds >= %s'%i)
测试集的召回率: 1.0
测试集的召回率: 1.0
测试集的召回率: 1.0
测试集的召回率: 0.9727891156462585
测试集的召回率: 0.9387755102040817
测试集的召回率: 0.8775510204081632
测试集的召回率: 0.8163265306122449
测试集的召回率: 0.7755102040816326
测试集的召回率: 0.5918367346938775
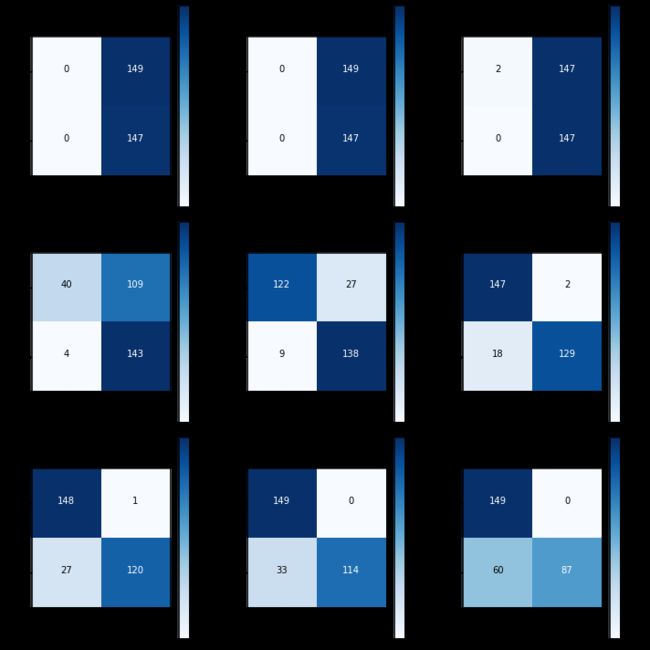
从上面的结果可以看出,随着阈值的增大,因为判断异常的标准升高,召回率降低。当阈值为0.1-0.3时,召回率为1,但是将所有的样本都当成了异常样本,这样的模型失去了意义。而当阈值为0.4时,召回率高但是假阳性太高,不适合。当阈值为0.6时,对比0.5时,检漏变多,但是假阳性变少,具体使用哪个阈值要看需求。当模型的阈值大于等于0.7时,召回率过低,模型不适合。
下采样模型具有假阳性高的缺点,下面使用过采样方案。
过采样方案
过采样方案主要是要生成更多的异常样本,使异常样本变得和正常样本一样多,即将异常样本规模扩大n倍。
异常样本的生成主要是使用SMOTE算法:
首先我们要选择出少数类样本,选择出其中的一个样本,对其他的样本点进行欧式距离计算,并且从小到大排列,只取出最小的1/n*样本数个,然后使用一定的随机数进行填充,其他的样本也进行,直至完成扩大n倍数。
import pandas as pd
#引入SOMTE算法模块
from imblearn.over_sampling import SMOTE
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
读取数据,划分特征值和标签
credit_cards=pd.read_csv("creditcard.csv")
columns=credit_cards.columns
features_columns=columns.delete(len(columns)-1)#删除最后一列:Class列
features=credit_cards[features_columns]
labels=credit_cards['Class']
数据集切分,将数据集切分为训练集和测试集
features_train, features_test, labels_train, labels_test = train_test_split(features,
labels,
test_size=0.2,
random_state=0)
基于SMOTE算法进行样本的生成,创造新的数据集,这样正负样本的数量就一致了。
oversampler=SMOTE(random_state=0)
#获得一个对象
os_features,os_labels=oversampler.fit_sample(features_train,labels_train)
#只对train集进行数据的生成,测试集一定是不动的,会使两个label的自动平衡
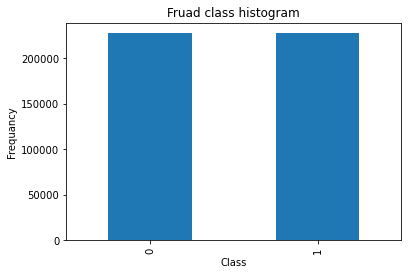
此时我们查看训练集的样本数据,可以发现是1:1的了
count_classes = pd.value_counts(os_labels, sort = True).sort_index()
count_classes.plot(kind = "bar")
plt.title("Fruad class histogram")
plt.xlabel("Class")
plt.ylabel("Frequancy")
Text(0, 0.5, 'Frequancy')
#进行惩罚参数权重的选择
os_features = pd.DataFrame(os_features)
os_labels = pd.DataFrame(os_labels)
best_c = printing_Kfold_scores(os_features,os_labels)
-------------------------------------------
C parameter: 0.01
-------------------------------------------
Iteration 1 :召回率= 0.8903225806451613
Iteration 2 :召回率= 0.8947368421052632
Iteration 3 :召回率= 0.968861347792409
Iteration 4 :召回率= 0.9578593332673855
Iteration 5 :召回率= 0.958408898561238
平均召回率: 0.9340378004742915
-------------------------------------------
C parameter: 0.1
-------------------------------------------
Iteration 1 :召回率= 0.8903225806451613
Iteration 2 :召回率= 0.8947368421052632
Iteration 3 :召回率= 0.9704769281841319
Iteration 4 :召回率= 0.9599256987722712
Iteration 5 :召回率= 0.9603323770897221
平均召回率: 0.93515888535931
-------------------------------------------
C parameter: 1
-------------------------------------------
Iteration 1 :召回率= 0.8903225806451613
Iteration 2 :召回率= 0.8947368421052632
Iteration 3 :召回率= 0.9705433218988603
Iteration 4 :召回率= 0.960321385783845
Iteration 5 :召回率= 0.954517976280762
平均召回率: 0.9340884213427783
-------------------------------------------
C parameter: 10
-------------------------------------------
Iteration 1 :召回率= 0.8903225806451613
Iteration 2 :召回率= 0.8947368421052632
Iteration 3 :召回率= 0.9705211906606175
Iteration 4 :召回率= 0.957529594091074
Iteration 5 :召回率= 0.9605082379837548
平均召回率: 0.9347236890971743
-------------------------------------------
C parameter: 100
-------------------------------------------
Iteration 1 :召回率= 0.8903225806451613
Iteration 2 :召回率= 0.8947368421052632
Iteration 3 :召回率= 0.9700121721810335
Iteration 4 :召回率= 0.9603433683955991
Iteration 5 :召回率= 0.960761038018927
平均召回率: 0.9352352002691969
*********************************************************************************
效果最好的模型所选的惩罚参数C是: 100.0
*********************************************************************************
#s使用最佳的惩罚系数进行模型的训练和验证
lr = LogisticRegression(C = best_c, penalty = 'l1',solver='liblinear')
lr.fit(os_features,os_labels.values.ravel())
y_pred = lr.predict(features_test.values)
cnf_matrix = confusion_matrix(labels_test,y_pred)
np.set_printoptions(precision=2)
print("测试集中的召回率: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
测试集中的召回率: 0.9108910891089109
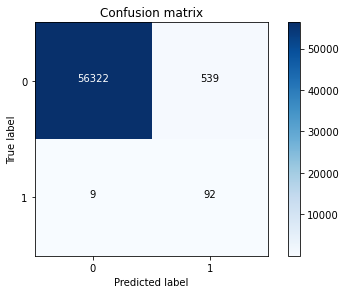
观察混淆矩阵可知,在召回率较高的情况下,此时我们的误判数由原来的8000+降低到了500+,误判的数量大大降低了,即假阳性降低,故采用过采样的方案效果更好。