matplotlib绘制关联图
相关性矩阵图
相关性矩阵存在的必要性
相关性矩阵,又叫做热力图,是关联图中最重要的一张图像,它能够为我们展现多个变量凉凉之间的相关性。
惯量图的目标是探索两个事件之间的关系,它为我们展示出一个事物随着另一事物的变化如何变化,但我们之前描述的关联图,折线图或散点图都只能够分析两个变量之间的相关性。在实际统计学和机器学习应用当中,我们往往需要探求多个变量两两之间的相关性。
一个最典型的例子是:在统计建模中,能够使用最小二乘法求解线性回归模型的充分必要条件是特征之间没有相关性(在统计学当中标准的术语应该叫做共线性),否则模型就会出现偏移,因此我们往往要先探索相关性,排除相关性,然后再建模。
要探求众多变量两两之间的相关性,我们不太可能对每一组变量都绘制散点图,这样的非常低效。
除此之外,即便我们绘制出了图像,我们也无法判断出相关性的强弱,即如果相关,那到底有多相关?
所以我们要选择更加有效也更加直接的方式:
1、引入衡量相关性的数学指标:相关系数(Correlation Coefficient)
相关系数是某种类型相关性等额数值度量,通常是有界的数字。最为人所知的就是皮尔逊相关系数,这个系数在-1~1之间波动,0表示完全无关,1表示完全正相关,-1表示完全负相关。
2、绘制相关系数矩阵图,一次性查看所有变量两两之间的相关性
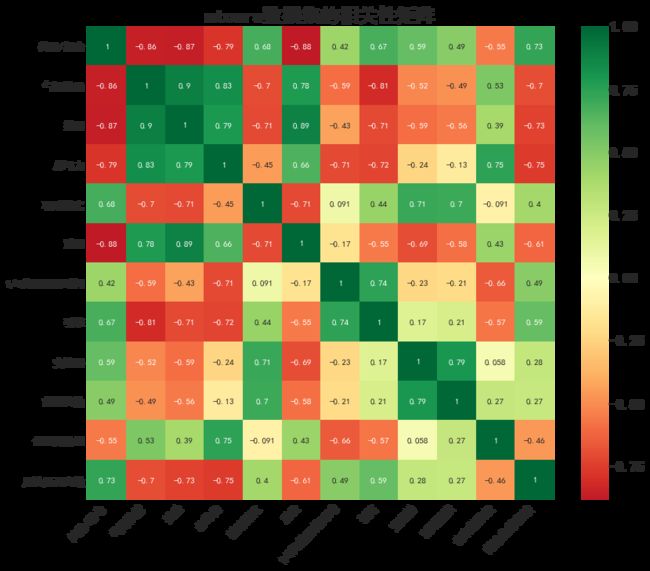
这就是本节要绘制的图像。这张图实际是相关性矩阵和热力图一起构建,热力图(heapmap)就是用颜色深浅来表示数值大小的图像

横坐标是:一个数据集中的所有变量(可能包括特征或标签)
纵坐标:一个数据集中的所有变量(可能包括特征或标签)
颜色:颜色越接近红和绿,相关性越强,绿色代表正相关,红色代表负相关,浅黄色代表不想关系
1、导入需要的绘图库&导入数据
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
large = 22; med = 16; small = 12
params = {'axes.titlesize': large,
'legend.fontsize': med,
'figure.figsize': (16, 10),
'axes.labelsize': med,
'axes.titlesize': med,
'xtick.labelsize': med,
'ytick.labelsize': med,
'figure.titlesize': large}
plt.rcParams.update(params)
plt.style.use('seaborn-whitegrid')
sns.set_style("white")
%matplotlib inline
#导入数据
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")
#所用数据集mtcars 记录了32种不同品牌的轿车的11个属性
name = ["英里/加仑","气缸数量","排量","总马力","驱动轴比","重量"
,"1/4英里所用时间","引擎","变速器","前进档数","化油器数量","用油是否高效"
,"汽车","汽车名称"]
df.columns = name #替换掉英文的列名
#英里/加仑:每加仑油耗可以跑的英里数,这个数值越大代表汽车越节能
#用油是否高效:不难注意到,其实这个特征中的0和1是根据特征英里/加仑来决定的,如果英里/加仑大于4,则用油高效(1),否则用油不高效(0)
#引擎:分为V(V型)和S(直型)两种,其中1为V型,0为直型
#其中cars和carname是一模一样的数据
(df["汽车"] != df["汽车名称"]).sum()
3、先实现相关性矩阵,再实现热力图
df.corr():实现相关性矩阵
参数method:填写相关系数类型的参数,可以选择”Pearson“,”kendall“,”spearman“。
什么时候用相关系数?变量相关时:
| 分类型变量vs分类型变量 | 分类型变量vs连续型变量 | 连续型变量vs连续型变量 |
|---|---|---|
| 列联表分析,卡方检验(Chi-squared) | 二分类:点双列相关(皮尔逊相关系数的一种特殊情况);多分类:Kruskal-Wallis H检验(如t检验或方差分析) | 线性相关:皮尔逊相关系数 ;非线性相关:以斯皮尔曼相关系数为代表的一系列等级相关系数 |
比较特别的是kendall这个相关系数,它对比的是两个变量按数量排序时(从小到大,或者从大到小),数据排序的相似性。其他相关系数,可以在scipy,numpy库中找到(百度和谷歌将会是你的好帮手)
sns.heatmap:把相关性矩阵放到热力图里去
参数:
data:输入的相关性矩阵
cmap:使用的光谱
center:绘制有色数据时,位于光谱中心的颜色所对应的值,注意:则一定是一个控制颜色的参数。如果没有指定cmap,使用此参数将更改默认的cmap参数。因此,我们一般在center中填写0。
annot:如果为True,则在热力图的每个单元格中写入数据值。如果时一个类似于data形状的数组,那么使用它来注释恶徒而不是原始数据。
#确保正常显示中文+负号
plt.rcParams['font.sans-serif']=['Simhei']
plt.rcParams['axes.unicode_minus']=False
#绘制图像
plt.figure(figsize=(12,10), dpi= 70)
sns.heatmap(df.corr() #需要输入的相关性矩阵
, xticklabels=coef.columns #横坐标标签
, yticklabels=coef.columns #纵坐标标签
, cmap='RdYlGn' #使用的光谱,一般来说都会使用由浅至深,或两头颜色差距较大的光谱
# , cmap='winter' #不太适合做热力图的光谱
, center=0 #填写数据的中值,注意观察此时的颜色条,大于0的是越来越靠近绿色,小于0的越来越靠近红色
# , center= -1 #填写数据中的最大值/最小值,则最大值/最小值是最浅或最深的颜色,数据离该极值越远,颜色越浅/颜色越深
, annot=True
)
#装饰图像
plt.title('mtcars数据集的相关性矩阵', fontsize=22)
plt.xticks(fontsize=12 #字体大小
,rotation=45 #字体是否进行旋转
,horizontalalignment='right' #刻度的相对位置
)
plt.yticks(fontsize=12)
plt.show()
成对分析图
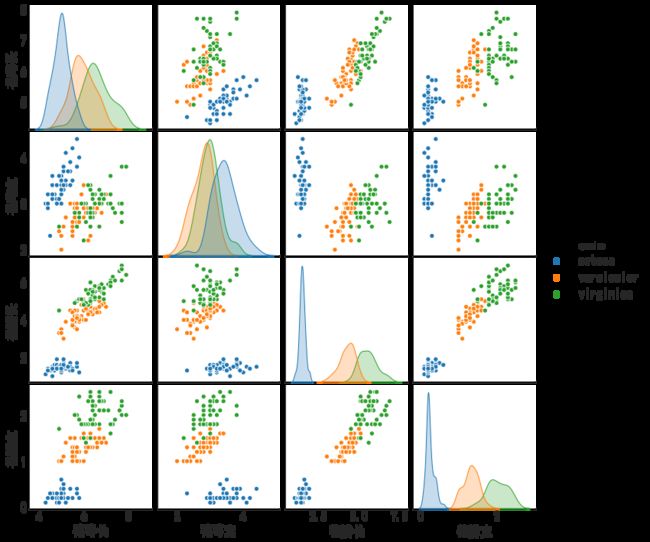
成对分析图是以图像形式分析多个变量之间相关性的图像,是矩阵图的具象化。
如我们前面提及的,我们可以使用散点图,或者带最佳拟合的散点图来描述变量两两之间的关系。当我们有着探索多个特征两两之间关系的需求时,——绘制图像的效率比较地下,因此我们才引入成对分析图,一种类矩阵的而绘图那个是,一次性绘制出所有特征之间的相关性图像。
成对分析图的横坐标是所有特征,纵坐标也是所有特征。横坐标为不同的特征时,显示两个特征之间的相关性图像,当横纵坐标为同一个特征时,显示这个特征自身的分布图。
1、导入需要的绘图库
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
import warnings; warnings.filterwarnings(action='once')
large = 22; med = 16; small = 12
params = {'axes.titlesize': large,
'legend.fontsize': med,
'figure.figsize': (16, 10),
'axes.labelsize': med,
'axes.titlesize': med,
'xtick.labelsize': med,
'ytick.labelsize': med,
'figure.titlesize': large}
plt.rcParams.update(params)
plt.style.use('seaborn-whitegrid')
sns.set_style("white")
%matplotlib inline
2、导入数据
#seaborn中自带数据库,可以从中导入著名的鸢尾花
df = sns.load_dataset('iris')
3、代码解读,图像解读
sns.pairplot()
重要参数:
hue:类别所在的列(和带拟合线的散点图一致),取出数据集的子集,对数据集进行分类,其实单词"hue"是色调的意思,我们可以将这个参数与我们之前类中的参数c来进行比对,在这个参数中输入不同的类别,可以让不同的数据集展示不同的颜色。。
kind:绘制的相关性图像类型,可以选择"scatter”散点图或者“reg"带拟合线的散点图。
#绘制图像 - 散点图
plt.figure(figsize=(10,8), dpi = 80) #设置画布
plt.rcParams['font.sans-serif']=['Simhei'] #中文能够显示
sns.pairplot(df #数据,各个特征和标签
, kind="scatter" #要绘制的图像类型
, hue="species" #类别所在的列(标签)
, plot_kws=dict(s=40, edgecolor="white", linewidth=1) #散点图的一些详细设置
);
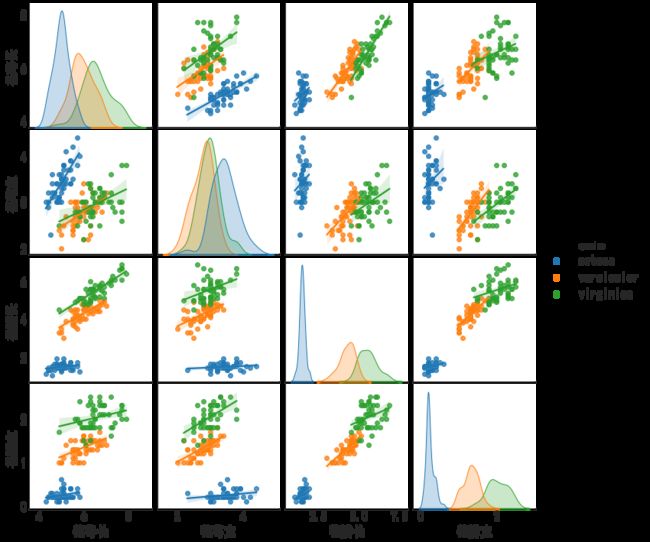
#绘制图像 - 带拟合线的散点图
plt.figure(figsize=(10,8), dpi= 80)
plt.rcParams['font.sans-serif']=['Simhei']
sns.pairplot(df, kind="reg", hue="species");
什么时候用相关性矩阵,什么时候用成对分析图呢?
当我们希望探求不同分类下的特征之间的相关性的时候,用成对分析图
当特征很多的时候,使用相关性矩阵,当特征只有少数的几个的是偶,使用成对分析图;当在意特征本身的分布时候,使用成对分析图;当数据较少时,使用成对分析图。