pytorch基础(八)- 循环神经网络 RNN&LSTM
目录
- 时间序列表示
-
- word embedding
- one-hot编码和语义相似性编码
- 序列的batch表示
- 循环神经网络
-
- RNN网络结构
- RNN形式化
- RNN网络训练
- RNN layer
-
- nn.RNN
- nn.RNNCell
- 时间序列预测实战
- RNN训练难题
-
- 梯度爆炸
- 梯度弥散
- LSTM
-
- 遗忘门
- 输入门
- 输出门
- 解决梯度弥散
- LSTM使用
-
- nn.LSTM
- nn.LSTMCell
- 情感分类问题实战
时间序列表示
word embedding
pytorch没有办法直接表示文字或语音,pytorch只支持数值类型,不能支持string类型,那必须把string类型表示为数值类型,这种方法就叫做representation或者word embedding。

one-hot编码和语义相似性编码
对于文本信息(单词)的表达可以采用one-hot编码;
假如有3500个单词,那么one-hot编码的长度就为3500;

one-hot是稀疏的,并且一般单词有上万个,因此one-hot的维度比较高;
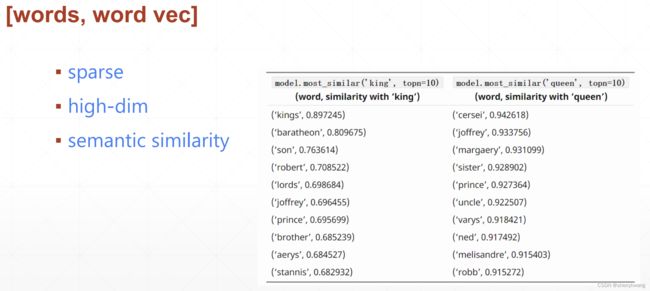
所以one-hot在实际场景中基本上用不了;考虑将word embedding转换为更加密集的编码,并且考虑到单词之间的相似性;常用的方法有word2vec, glove。
word2vec就是查表操作;
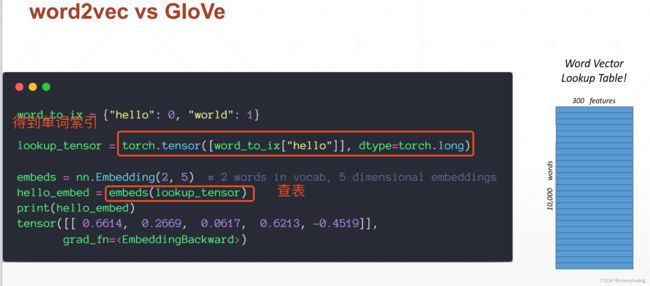
glove也是查表操作;

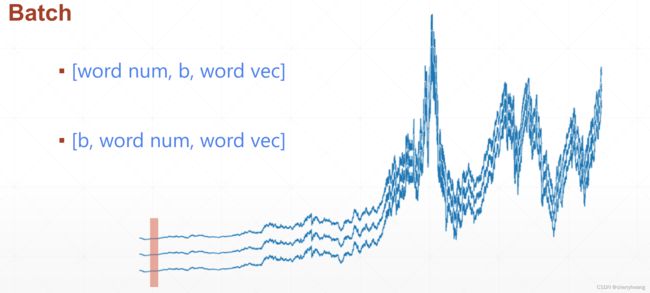
序列的batch表示
[word num, b, word vec] 以时间戳表示;
[b, word num. word vec] 以句子表示;
循环神经网络
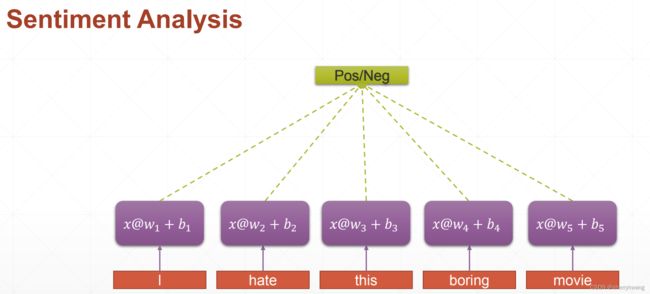
RNN网络结构
如果对于句子的每一个单词都经过线性层处理,处理结果再合并,则对于长句子,就会需要大量的参数;
并且没有上下文语境信息;我们需要一个从头到尾协调一致性的单元,存储语境信息,使得网络将语境信息存储起来;

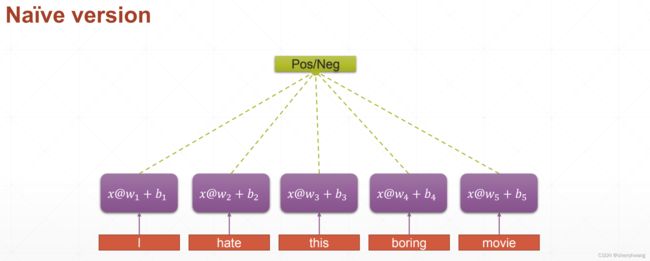
第一个版本改进版本;
所有单词对应的网络的权值共享(weight sharing),从一定程度上解决了长句子所需参数量大,从而处理难的问题。
改进版本;
添加一个语境单元,每一步不仅考虑到当前的输入,还考虑到上一步(上一个时间戳)的输出;
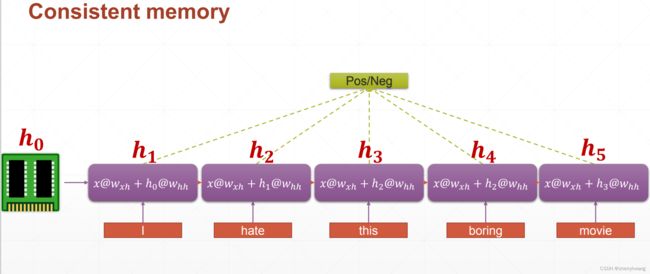
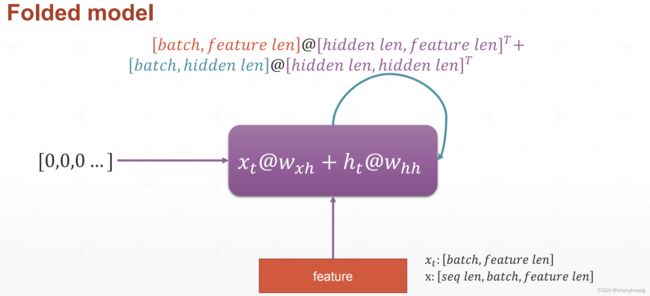
折叠的形式;
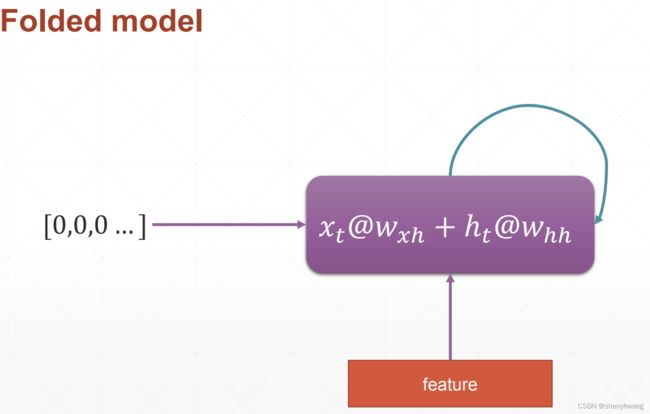
RNN形式化

RNN网络训练
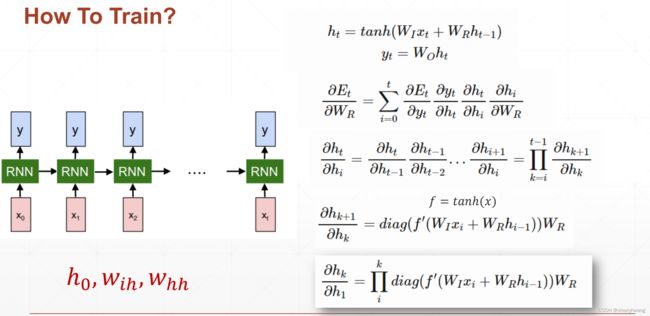
RNN layer
每一个时间戳上有一个 x t x_t xt,与上一个时刻menmory h t − 1 h_{t-1} ht−1做一个融合(或是特征提取);
nn.RNN
RNN计算单元;
nn.RNN(word dim, hidden dim)

import torch
import torch.nn as nn
rnn = nn.RNN(50, 10)
print(rnn._parameters.keys())
print(rnn.weight_hh_l0.shape)
print(rnn.weight_ih_l0.shape)
print(rnn.bias_hh_l0.shape)
print(rnn.bias_ih_l0.shape)
输出:
odict_keys(['weight_ih_l0', 'weight_hh_l0', 'bias_ih_l0', 'bias_hh_l0'])
torch.Size([10, 10])
torch.Size([10, 50])
torch.Size([10])
torch.Size([10])

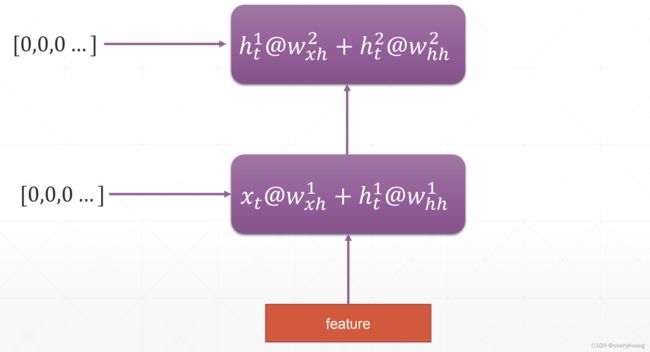
hT是最后一个时间戳的堆叠的所有rnn layer的语境上下文输出(menmory状态),所以包含一个num_layer维度;
out是每一个时间戳的堆叠的最后一个rnn layer的输出;

import torch
import torch.nn as nn
word_dim = 50
hidden_dim = 10
num_layers = 2
rnn = nn.RNN(word_dim, hidden_dim, num_layers)
sequence_len = 20
batch_size = 30
x = torch.rand(sequence_len, batch_size, word_dim)
h0 = torch.zeros(num_layers, batch_size, hidden_dim)
out, hT = rnn(x, h0)
print(out.shape)
print(hT.shape)
输出:
torch.Size([20, 30, 10])
torch.Size([2, 30, 10])
nn.RNNCell
nn.RNNCell完成单个时间戳的单层的数据传递、预测;功能和n n.RNN一样,只是没有堆叠层和stack所有out的功能;


单层cell:
import torch
import torch.nn as nn
cell = nn.RNNCell(100, 50,)
input = torch.randn(3,3,100)
ht = torch.zeros(3,50)
for x_cell in input:
ht = cell(x_cell, ht)
print(ht.shape)
输出:
torch.Size([3, 50])
torch.Size([3, 50])
torch.Size([3, 50])
堆叠两层cell:
import torch
import torch.nn as nn
cell1 = nn.RNNCell(100, 50,)
cell2 = nn.RNNCell(50, 30)
input = torch.randn(3,3,100)
ht1 = torch.zeros(3,50)
ht2 = torch.zeros(3,30)
for x_cell in input:
ht1 = cell1(x_cell, ht1)
ht2 = cell2(ht1, ht2)
print(ht1.shape)
print(ht2.shape)
输出:
torch.Size([3, 50])
torch.Size([3, 30])
时间序列预测实战
已知一段曲线,预测其下一段时间的曲线;让模型学习正弦规律;

from cProfile import label
import torch
import torch.nn as nn
import numpy as np
from matplotlib import pyplot as plt
def generate_data():
num_time_steps = 60
#生成一个随机时间点开始的样本
start = np.random.randint(3, size = 1)[0] #随机初始化一个开始点
time_steps = np.linspace(start, start+10, num_time_steps)
data = np.sin(time_steps)
data = data.reshape(num_time_steps, 1) #数据长度为1
x = torch.tensor(data[:-1]).float().view(1, num_time_steps-1, 1) #添加一个batch维度为1
y = torch.tensor(data[1:]).float().view(1, num_time_steps-1, 1)
return x,y,time_steps
class Net(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super().__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first = True)
self.linear = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden_pre):
b = x.size(0)
out, hidden_pre = self.rnn(x, hidden_pre) # out[b, seq, hidden_size] hidden_pre = [b, num_layer, hidden_size]
out = out.view(-1, self.hidden_size) #[b*seq, hidden_size]
out = self.linear(out)#[b*seq, 1]
out = out.view(b, -1, self.output_size) #[b, seq, 1]
return out, hidden_pre
if __name__ == '__main__':
batch_size = 1
num_layers = 2
hidden_size = 10
model = Net(1, hidden_size, num_layers, 1)
criteron = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr = 0.5e-2)
hidden_pre = torch.zeros(num_layers, batch_size, hidden_size)
for iter in range(6000):
x,y,_ = generate_data()
out, hidden_pre = model(x, hidden_pre)
hidden_pre = hidden_pre.detach()
loss = criteron(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if iter %100 == 0:
print('iteration:{} loss:{}'.format(iter, loss.item()))
x,y,time_steps = generate_data()
input = x[:,0,:].unsqueeze(1) #取所有batch的序列的第一个数据 [b, 1, word_dim]
h = torch.zeros(num_layers, batch_size, hidden_size)
predictions = []
for _ in range(x.shape[1]): #遍历序列
pred, h = model(input, h)
input = pred
predictions.append(pred.detach().numpy().ravel()[0])
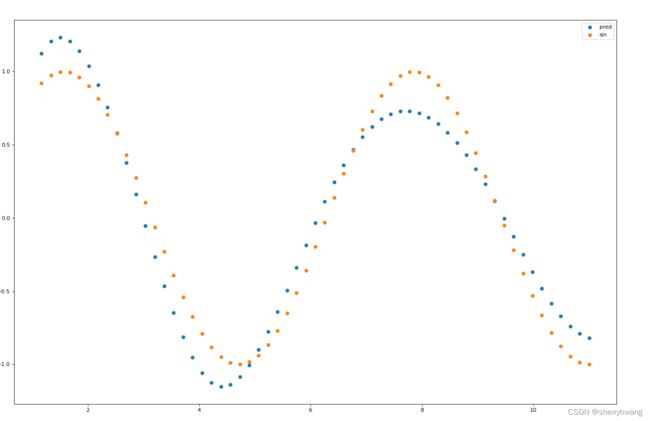
figure = plt.figure(figsize=(20,20), dpi = 80)
plt.scatter(time_steps[1:], predictions, label='pred')
plt.scatter(time_steps[1:], y.view(-1).numpy(), label = 'sin')
plt.legend()
plt.show()
输出:
iteration:0 loss:0.6097927689552307
iteration:100 loss:0.007763191591948271
iteration:200 loss:0.0011507287854328752
iteration:300 loss:0.00087575992802158
iteration:400 loss:0.0005032330518588424
iteration:500 loss:0.0004986028652638197
iteration:600 loss:0.0009817895479500294
iteration:700 loss:0.00040510689723305404
iteration:800 loss:0.0010686117457225919
...
RNN训练难题
对于长序列数据,会出现梯度爆炸,或者梯度弥散的情况;
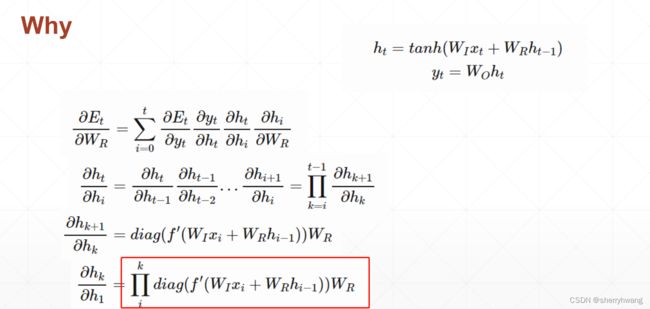
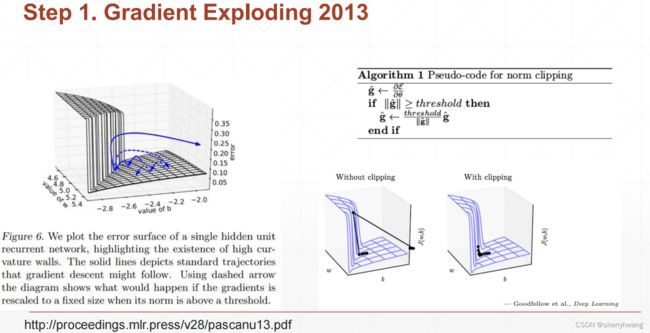
梯度爆炸
对梯度做cliping操作;
梯度大于阈值的时候,除以它自己的范数,使得梯度范数变为1;
for p in model.parameters():
torch.nn.utils.clip_grad_norm(p, 10) #对每个参数的梯度做一个cliping
梯度弥散
LSTM网络;
LSTM
RNN可以记住当前单词的附近的语境;但是对于离得远的单词或者前面的一些单词就给忘记了(short-term menmory)。
LSTM可以记住特别长的时间序列,把RNN能记住的时间序列延长了,所以叫long-short-term menmory。
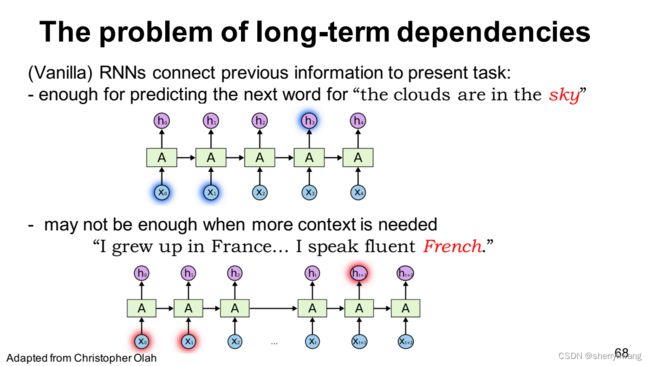
RNN展开形式;
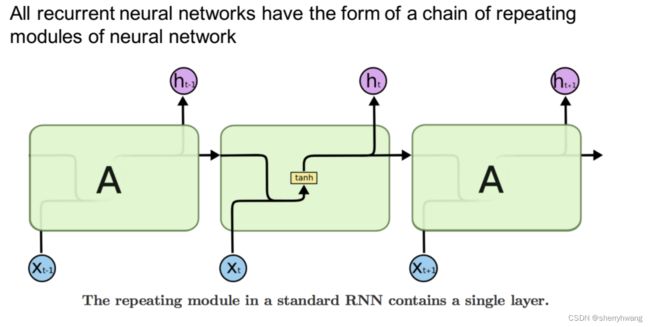
LSTM展开形式;
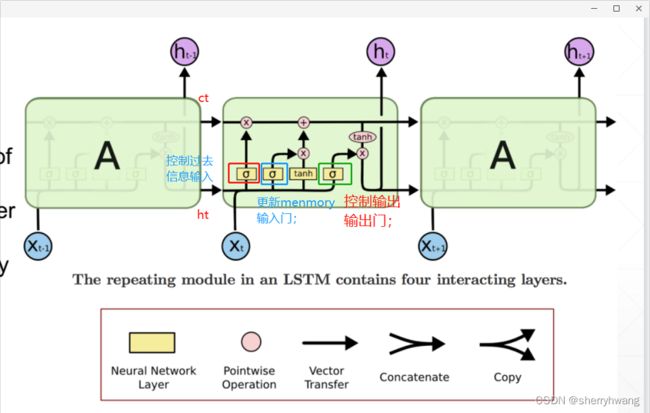
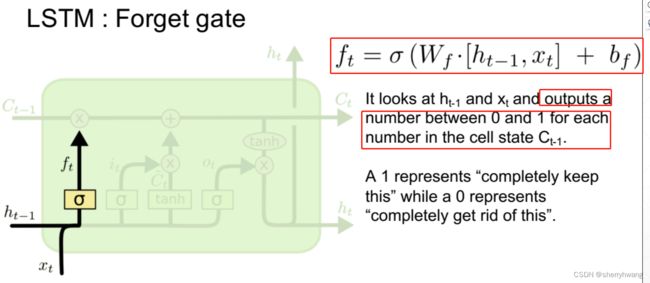
遗忘门
输入门
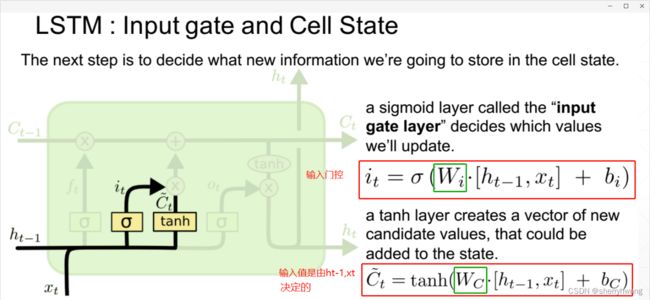
新的记忆单元;
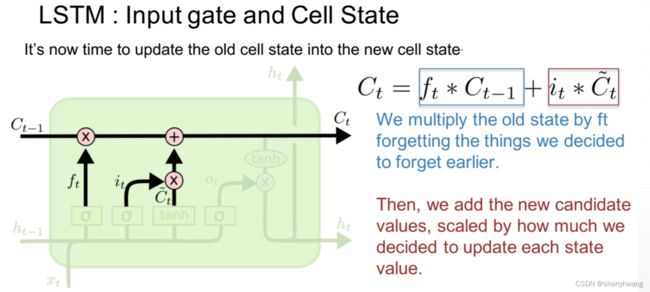
输出门
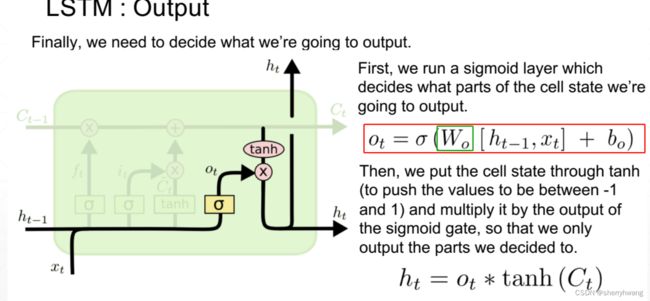
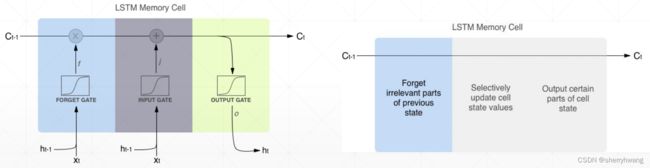
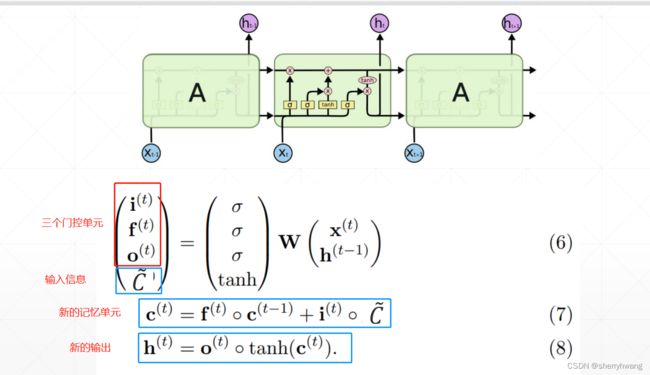
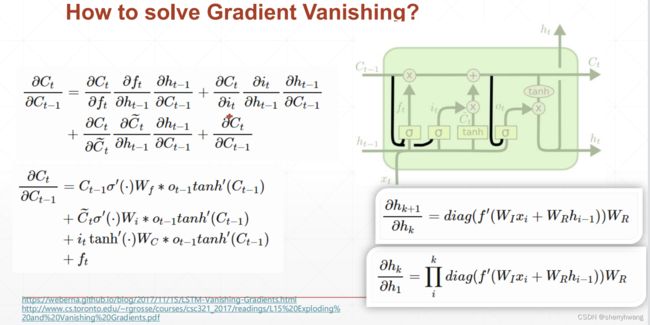
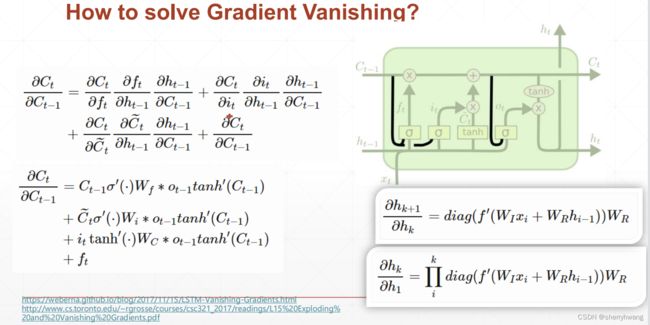
解决梯度弥散
梯度更计算的时候不会出现 w k w^k wk的情况,并且梯度计算是几项累加,并且这几项相互制约,不会同时出现都很小,或者都很大的情况,所以避免了梯度等于0,也就是梯度弥散;
LSTM使用
nn.LSTM


lstm = nn.LSTM(100, 20, 4)
c = torch.zeros(4, 30, 20)
h = torch.zeros(4, 30, 20)
x = torch.rand(80, 30, 100)
out, (h,c) = lstm(x, (h,c))
print(out.shape)
print(h.shape)
print(c.shape)
输出:
torch.Size([80, 30, 20])
torch.Size([4, 30, 20])
torch.Size([4, 30, 20])
nn.LSTMCell


单层cell:
lstm_cell = nn.LSTMCell(100, 20)
c = torch.zeros(30, 20)
h = torch.zeros(30, 20)
x = torch.rand(80, 30, 100)
input = x[0]
h,c = lstm_cell(x[0], (h,c))
print(h.shape)
print(c.shape)
输出:
torch.Size([30, 20])
torch.Size([30, 20])
多层cell:
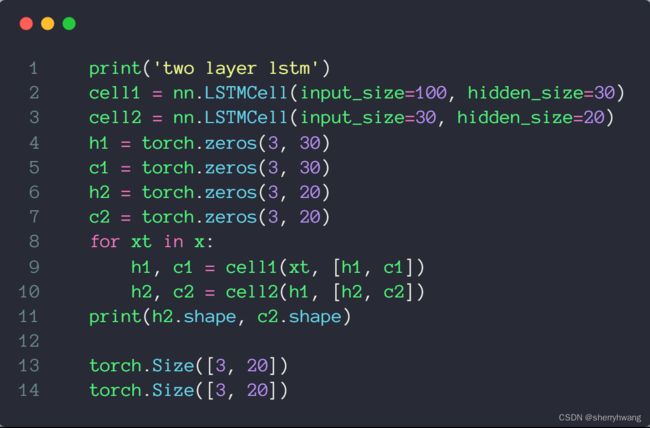
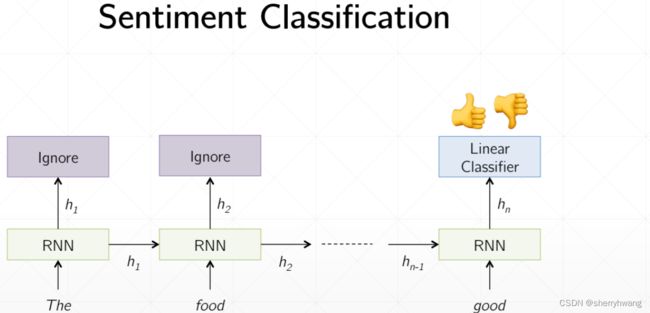
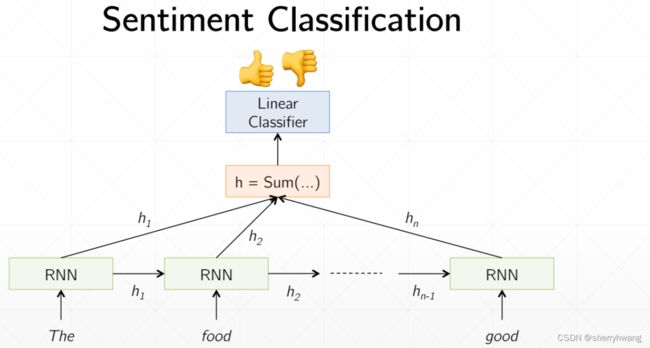
情感分类问题实战