详细实现yolov5测试丶自己数据集训练测试丶Tensorrt加速优化(完 结 !)
参考文献:【yolov5系列】yolov5 v6.0 环境配置、图片视频测试、模型可视化、v6.0的更新内容
Jeston AGX Orin安装Pytorch1.11.0+torchvision0.12.0_beautifulback的博客
https://github.com/ultralytics/yolov5(README.md)
yolov5测试和训练自己的数据集
YOLOv5训练自己的数据集(超详细完整版)
Train Custom Data · ultralytics/yolov5 Wiki · GitHu
零基础YOLOv5的详细使用教程
YOLOv5超详细的入门级教程(训练篇)
一.下载yolov5工程文件测试
(1)下载工程文件
GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite
(2)创建虚拟环境
conda create -n yolov5 python==3.8 -y(3)安装Pytorch(我的设备是Jetson AGX Orin)
conda activate yolov5Jeston AGX Orin安装Pytorch1.11.0+torchvision0.12.0_beautifulback的博客-CSDN博客
(4)配置环境(前面安装了pytorch和torchvision,这里可以把requirements.txt中相应部分注释)
pip install -r requirements.txt


(5)测试图片
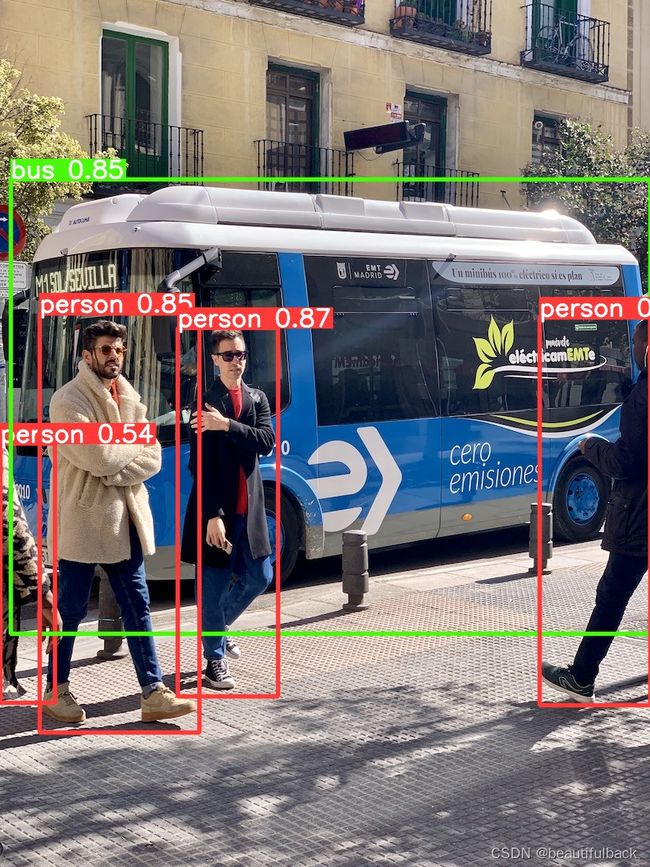
① 测试默认文件(yolov5/images/bus.jpg和zidane.jpg)中的图片
下载工程文件默认下载了yolov5s.pt模型,其他模型可在这里下载:Releases · GitHub
python detect.py --weight yolov5s.pt
检测会生成一个runs文件夹,结果保留在yolov5/runs/detect/exp文件中
图片检测结果:

②测试任意的自己的图片
首先将图片放在 yolov5/data/images/文件夹下面,然后运行下面代码检测:
python detect.py --weight yolov5s.pt --source data/images/2.jpg结果保留在yolov5/runs/detect/exp2文件中 (每运行一次结果保留在新的exp..中)

 ③检测视频
③检测视频
同理将视频格式为.mp4的文件放在 yolov5/data/images/文件夹下面,然后运行下面代码检测:
python detect.py --weight yolov5s.pt --source data/images/1.mp4
(6)训练
python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt val_batch2_labels.jpg
val_batch2_labels.jpg
(7)导出onnx模型及测试
①安装onnx库
pip install -U coremltools onnx scikit-learn==0.19.2②导出模型
python export.py --weights yolov5s.pt --include onnx --dynamic③用onnx模型测试
python detect.py --weights yolov5s.onnx
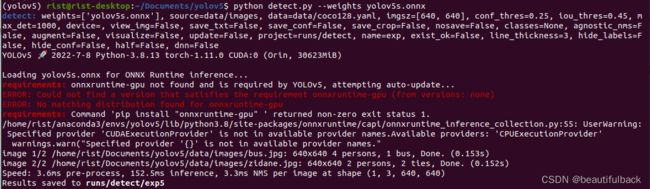


这里可以看到onnxruntime还有一点问题,但不影响检测(可能是因为版本问题)
(8)可视化
下载可视化工具netron
pip install netron
使用时直接在终端中输入:netron 可视化yolov5.onnx(网络中的一部分)
可视化yolov5.onnx(网络中的一部分)
二.训练及测试自己的数据集
(1)准备数据集ours_data文件夹
①Annotations存放.xml文件
②ImageSets/Main/存放train.txt,val.txt,test.txt和trainval.txt
③JPEGImages存放.jpg文件
④准备生成train.txt,val.txt,test.txt和trainval.txt的执行文件:split_train_val.py
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='ours_data/Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ours_data/ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.9
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()(2)准备labels
把数据集格式转换成yolo_txt格式,即将每个xml标注提取bbox信息为txt格式(这种数据集格式成为yolo_txt格式),每个图像对应一个txt文件,文件每一行为一个目标的信息,包括class, x_center, y_center, width, height格式;创建voc_label.py文件,将训练集、验证集、测试集生成label标签(训练中要用到),同时将数据集路径导入txt文件中
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = [
"truck gun",
"uav",
"ball",
"plane",
"person",
"tank",
"carrier",
"car",
"airplane",
"ship"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('/home/rist/Documents/yolov5/ours_data/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('/home/rist/Documents/yolov5/ours_data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
# difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('/home/rist/Documents/yolov5/ours_data/labels/'):
os.makedirs('/home/rist/Documents/yolov5/ours_data/labels/')
image_ids = open('/home/rist/Documents/yolov5/ours_data/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('ours_data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/ours_data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
运行后会生成如下labels文件夹和三个包含数据集的txt文件,其中labels中为不同图像的标注文件,train.txt等txt文件为划分后图像所在位置的绝对路径,如train.txt就含有所有训练集图像的绝对路径 .
(3)增加自己的配置文件
在yolov5/data/文件下添加一个自己数据集的文件:our.yaml
train: /home/rist/Documents/yolov5/ours_data/train.txt
val: /home/rist/Documents/yolov5/ours_data/val.txt
test: /home/rist/Documents/yolov5/ours_data/test.txt
# Classes
nc: 10 # number of classes
names: ['truck gun', 'uav', 'ball', 'plane', 'person', 'tank', 'carrier', 'car', 'airplane', 'ship'] # class names(4)修改模型文件
在yolov5/models/中有几个模型文件,可以自己选择一个进行修改,主要是改里面的类别参数
nc: 10 # number of classes(5)修改train.py

--weights --cfg --data 中的default参数信息根据自己文件路径和命名方式进行修改,这里为了验证是否正确,--epochs=10(如果显卡好可以调大一点,Github上下载时为300), --batch-size 是一次看完多少张图片才进行权重更新,梯度下降的mini-batch,显卡不好可以调小.
(6)开始训练
python train.py
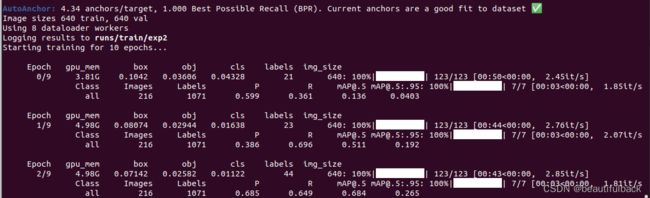
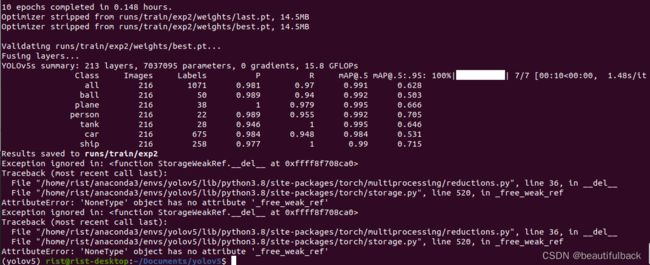
epoch=10训练过程结果,也可以用TensorBoard:
 result.jpg
result.jpg
 val_batch2_labels.jpg
val_batch2_labels.jpg
结果保存在yolov5/runs/train/exp2中
训练过程中遇到这个问题:
Exception ignored in:
Traceback (most recent call last):
File "/home/rist/anaconda3/envs/yolov5/lib/python3.8/site-packages/torch/multiprocessing/reductions.py", line 36, in __del__
File "/home/rist/anaconda3/envs/yolov5/lib/python3.8/site-packages/torch/storage.py", line 520, in _free_weak_ref
AttributeError: 'NoneType' object has no attribute '_free_weak_ref'
Exception ignored in:
Traceback (most recent call last):
File "/home/rist/anaconda3/envs/yolov5/lib/python3.8/site-packages/torch/multiprocessing/reductions.py", line 36, in __del__
File "/home/rist/anaconda3/envs/yolov5/lib/python3.8/site-packages/torch/storage.py", line 520, in _free_weak_ref
AttributeError: 'NoneType' object has no attribute '_free_weak_ref' 原因是 Pytorch版本过高,降低版本即可解决,参考:降低Pytorch版本≤10.0
由于目前用的设备是Jetson AGX Orin在刷机时Jetpack=5.0.1,在使用Pytorch时只能对应使用python=3.8+torch1.11.0(或者torch1.12.0)+torchvision0.12.0,故而不能降低版本,但是后面测试没有影响,就没有管,亦可检测.
(7)测试自己的图片
python detect.py --weights runs/train/exp2/weights/best.pt --source data/images/ --device 0


如果需要检测物体的位置坐标和类别标签可以运行下面的代码:
python detect.py --weights runs/train/exp2/weights/best.pt --source data/images/ --device 0 --save-txt(8)测试视频
将要检测的视频格式为.mp4放在images文件夹下,运行下面的代码即可保存在detect文件中
python detect.py --weights runs/train/exp2/weights/best.pt --source data/images/ --device 0三.TensorRT加速优化
(1)安装TensorRT加速优化器
查看自己CUDA和Cudnn版本
CUDA Zone - Library of Resources | NVIDIA Developer
cuDNN Archive | NVIDIA Developer

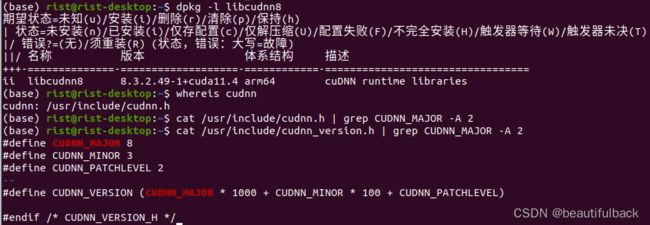 根据自己的版本在官网上下载对应的TensorRT:https://developer.nvidia.com/nvidia-tensorrt-8x-download
根据自己的版本在官网上下载对应的TensorRT:https://developer.nvidia.com/nvidia-tensorrt-8x-download
TensorRT-8.2.1.8.Ubuntu-20.04.aarch64-gnu.cuda-11.4.cudnn8.2.tar
(2)安装
# 提取到此处
tar -xzvf TensorRT-8.2.1.8.Ubuntu-20.04.aarch64-gnu.cuda-11.4.cudnn8.2.tar
# 打开环境变量文件
vim ~/.bashrc
# 将下面三个环境变量写入环境变量文件并保存
export LD_LIBRARY_PATH=/home/rist/software/TensorRT-8.2.1.8/lib:$LD_LIBRARY_PATH
export CUDA_INSTALL_DIR=/usr/local/cuda-11.4
export CUDNN_INSTALL_DIR=/usr/local/cuda-11.4
# 使刚刚修改的环境变量文件生效
source ~/.bashrc
# 进入虚拟环境
conda activate yolov5
# 进入TensorRT-8.2.1.8/python
cd TensorRT-8.2.1.8/python
pip install tensorrt-8.2.1.8-cp38-none-linux_aarch64.whl 成功安装TensorRT=8.2.1.8 !
成功安装TensorRT=8.2.1.8 !
优化过程另起一篇博客,请移步:
Jetson AGX Orin上部署YOLOv5_v5.0+TensorRT8