简单实现中文分词中的常用字过滤
首先感谢
兽族的荣耀朋友的文章
简单编写的中文分词程序 ,我开始接触搜索引擎这个领域以及写这篇随笔都离不开他的精彩文章的帮助:)
下面切入正题。
名词:分析器(Analyzer),词单元(Tokens),高亮(Highlight)。
实现背景:
当在搜索引擎文本框中写入源词时,分析器(Analyzer)会将源词拆分成多组词单元(Tokens)。之后搜索引擎会在词库中搜索词单元,进行匹配,记录权重等其它操作。
当有些源词中包括常用词时,往往会给接下来的工作带来麻烦,比如下面的情况:

当搜索 [丰富的教学经验]时,分词器将源词拆分为[丰富]-[的]-[教学]-[经验],由于高亮(Highlight)会将每个词单元在页面中套色,于是过滤掉这些常用词就会显得十分必要 。
实现思路:
可以为词汇创建词库,当然也可以为需要过滤的常用词创建过滤词库,每次源词分词之前将源词进行过滤,再把过滤后的源词进行拆分。
实现环节:
知识1:缓存配置文件
许多朋友都有 J2EE 开发经验,对经典框架 Struts 都能熟练运用。大家一定都注意到每次修改struts-config.xml时,都要重新启动服务器后才能生效。为什么要这样设计呢?每次修改配置文件都能立即奏效不是更好吗?
对于小型应用来讲,每次从配置文件中读取信息,的确是不错的选择,但是当配置文件比较大时,比如用于过滤常用词的过滤词库,每次搜索时都重新加载词库并且从中进行搜索,显然耗费很长的时间。于是当应用程序启动时一次性加载过滤词库成为了不错的解决方案。
将配置文件缓存的方法非常简单,只要把接收过滤词的对象(可以是string[],也可以是IList<string>或者其它的什么你随意:))声明为 static 就可以了,以下是实现代码:
 public
class
FilterDemo
public
class
FilterDemo


 {
{
 private static string _filterPath;
private static string _filterPath;
private static IList<string> filter = null;
static FilterDemo()

 {
{
_filterPath = HttpContext.Current.Request.MapPath("~/App_Data/File/" + "Filter.txt");
// 从指定文件获得 待过滤字符串列表
InitFilterFile(_filterPath);
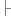 }
}
 }
}
filter 被声明为静态变量用于接收过滤词库中的词。当静态方法 InitFilterFile() 方法执行之后,filter被初始化。至此过滤词库加载成功,之后要获得过滤词列表,只会从缓存,也就是 filter 变量中获得,而不是从过滤词库中加载,从而提高了响应速度。当然如果要在词库中添加或者修改内容,必须重新启动服务才能生效,事物有一利必有一弊,鱼和熊掌的道理吧:)
知识2:从文本文件中读取信息
从文本文件读取信息,随手查一下 msdn 或者随便 google 一下可以找到一堆解决方案,所以具体实现过程也不用过多陈述。在这里我想强调一下文件字符集格式问题,因为我在写代码的时候的确遇到了问题。 先看一下下面的两种写法吧:
方法1:
using
(StreamReader sr
=
File.OpenText(path))
{
filter = new List<string>();
string s = "";
while ((s = sr.ReadLine()) != null)
{
filter.Add(s);
}
}
方法2:
using
(StreamReader sr
=
new
StreamReader(path, Encoding.Default))
{
filter = new List<string>();
string s = "";
while ((s = sr.ReadLine()) != null)
{
filter.Add(s);
}
}
第一种方法用 File 类的静态方法 OpenText(string path) 将内容读入 StreamReader 对象中,第二种方法直接用 StreamReader 的构造器实现了同样的功能,除此之外还指定了操作流的字符集。
功能强大的 Framework 为实现相同的功能提供了多套解决方案,方法的重载中往往为功能的实现提供了更为准确的路线,比如 StreamReader 构造中的 字符集 参数,在我使用上面第一种方法实现功能时,的确就遇到了乱码,而且把可用的词库修改内容另存之后用第一种方法读取,依然乱码,于是我试想是否可以在操作流中指定流的字符集,结果找到了上面的第二种方法,而且奏效。
想在这里说的感想就是自己想要的方法,Framework 可能已经为你做好了服务,理解了 Framework 的风格,会使功能实现的过程变得更加顺利:)
最后就是过滤源词的步骤了,非常简单:
// 过滤非法字符,字符串 - private static string WordFilter(string s)
#region // 过滤非法字符,字符串 - private static string WordFilter(string s)
/**//// <summary>
/// 过滤非法字符,字符串
/// </summary>
/// <param name="s">源字符串</param>
private static string WordFilter(string s)
{
foreach (string code in filter)
{
s = s.Replace(code, "");
}
return s;
}
#endregion
WordFilter(string s) 方法返回的就是过滤后的源词,至此功能实现。
看看效果吧:

存在问题:
过滤词库中的一些词(或字),会出现在一些词语中,比如[我], 在成语[我见犹怜]中会被过滤,所以这个成语会被拆分成 [见]-[犹]-[怜]。
说在后边:
搜索引擎技术至今没有一个统一的标准,还没有到某某功能用某某方式解决 普遍比较认同的阶段。大多数的站内搜索都处于摸索,试探阶段(当然,这个阶段给我们带来了无穷的乐趣:)),所以以上的解决方案只是众多解决方案中非常不成熟的一种,但是如果以上的方案能够给您带来一丝的灵感或者引起您对搜索引擎的一点点兴趣,我将感到非常开心:)
附赠: 过滤词库
Filter.txt
的
吗
么
啊
说
对
在
和
是
被
最
所
那
这
有
将
会
与
於
于
他
她
它
您
为
the
for
in
to
on
a
b
c
d
e
f
g
h
i
j
k
l
m
n
o
p
q
r
s
t
u
v
w
x
y
z
1
2
3
4
5
6
7
8
9
0
about
above
after
again
all
also
am
an
and
any
are
as
at
back
be
been
before
behind
being
below
but
by
can
click
do
does
done
each
else
etc
ever
every
few
for
from
generally
get
go
gone
has
have
hello
here
how
if
in
into
is
just
keep
later
let
like
lot
lots
made
make
makes
many
may
me
more
most
much
must
my
need
no
not
now
of
often
on
only
or
other
others
our
out
over
please
put
so
some
such
than
that
the
their
them
then
there
these
they
this
try
to
up
us
very
want
was
we
well
what
when
where
which
why
will
with
within
you
your
yourself
下面切入正题。
名词:分析器(Analyzer),词单元(Tokens),高亮(Highlight)。
实现背景:
当在搜索引擎文本框中写入源词时,分析器(Analyzer)会将源词拆分成多组词单元(Tokens)。之后搜索引擎会在词库中搜索词单元,进行匹配,记录权重等其它操作。
当有些源词中包括常用词时,往往会给接下来的工作带来麻烦,比如下面的情况:
当搜索 [丰富的教学经验]时,分词器将源词拆分为[丰富]-[的]-[教学]-[经验],由于高亮(Highlight)会将每个词单元在页面中套色,于是过滤掉这些常用词就会显得十分必要 。
实现思路:
可以为词汇创建词库,当然也可以为需要过滤的常用词创建过滤词库,每次源词分词之前将源词进行过滤,再把过滤后的源词进行拆分。
实现环节:
知识1:缓存配置文件
许多朋友都有 J2EE 开发经验,对经典框架 Struts 都能熟练运用。大家一定都注意到每次修改struts-config.xml时,都要重新启动服务器后才能生效。为什么要这样设计呢?每次修改配置文件都能立即奏效不是更好吗?
对于小型应用来讲,每次从配置文件中读取信息,的确是不错的选择,但是当配置文件比较大时,比如用于过滤常用词的过滤词库,每次搜索时都重新加载词库并且从中进行搜索,显然耗费很长的时间。于是当应用程序启动时一次性加载过滤词库成为了不错的解决方案。
将配置文件缓存的方法非常简单,只要把接收过滤词的对象(可以是string[],也可以是IList<string>或者其它的什么你随意:))声明为 static 就可以了,以下是实现代码:
public
class
FilterDemo
{ private static string _filterPath; private static IList<string> filter = null; static FilterDemo() { _filterPath = HttpContext.Current.Request.MapPath("~/App_Data/File/" + "Filter.txt"); // 从指定文件获得 待过滤字符串列表 InitFilterFile(_filterPath); }}
filter 被声明为静态变量用于接收过滤词库中的词。当静态方法 InitFilterFile() 方法执行之后,filter被初始化。至此过滤词库加载成功,之后要获得过滤词列表,只会从缓存,也就是 filter 变量中获得,而不是从过滤词库中加载,从而提高了响应速度。当然如果要在词库中添加或者修改内容,必须重新启动服务才能生效,事物有一利必有一弊,鱼和熊掌的道理吧:)
知识2:从文本文件中读取信息
从文本文件读取信息,随手查一下 msdn 或者随便 google 一下可以找到一堆解决方案,所以具体实现过程也不用过多陈述。在这里我想强调一下文件字符集格式问题,因为我在写代码的时候的确遇到了问题。 先看一下下面的两种写法吧:
方法1:
using
(StreamReader sr
=
File.OpenText(path))
{ filter = new List<string>(); string s = ""; while ((s = sr.ReadLine()) != null) { filter.Add(s); }}
using
(StreamReader sr
=
new
StreamReader(path, Encoding.Default))
{ filter = new List<string>(); string s = ""; while ((s = sr.ReadLine()) != null) { filter.Add(s); }}
功能强大的 Framework 为实现相同的功能提供了多套解决方案,方法的重载中往往为功能的实现提供了更为准确的路线,比如 StreamReader 构造中的 字符集 参数,在我使用上面第一种方法实现功能时,的确就遇到了乱码,而且把可用的词库修改内容另存之后用第一种方法读取,依然乱码,于是我试想是否可以在操作流中指定流的字符集,结果找到了上面的第二种方法,而且奏效。
想在这里说的感想就是自己想要的方法,Framework 可能已经为你做好了服务,理解了 Framework 的风格,会使功能实现的过程变得更加顺利:)
最后就是过滤源词的步骤了,非常简单:
// 过滤非法字符,字符串 - private static string WordFilter(string s)
#region // 过滤非法字符,字符串 - private static string WordFilter(string s) /**//// <summary> /// 过滤非法字符,字符串 /// </summary> /// <param name="s">源字符串</param> private static string WordFilter(string s) { foreach (string code in filter) { s = s.Replace(code, ""); } return s; } #endregion
WordFilter(string s) 方法返回的就是过滤后的源词,至此功能实现。
看看效果吧:
存在问题:
过滤词库中的一些词(或字),会出现在一些词语中,比如[我], 在成语[我见犹怜]中会被过滤,所以这个成语会被拆分成 [见]-[犹]-[怜]。
说在后边:
搜索引擎技术至今没有一个统一的标准,还没有到某某功能用某某方式解决 普遍比较认同的阶段。大多数的站内搜索都处于摸索,试探阶段(当然,这个阶段给我们带来了无穷的乐趣:)),所以以上的解决方案只是众多解决方案中非常不成熟的一种,但是如果以上的方案能够给您带来一丝的灵感或者引起您对搜索引擎的一点点兴趣,我将感到非常开心:)
附赠: 过滤词库
的吗么啊说对在和是被最所那这有将会与於于他她它您为theforintoon abcdefghijklmnopqrstuvwxyz1234567890aboutaboveafteragainallalsoamanandanyareasatbackbebeenbeforebehindbeingbelowbutbycanclickdodoesdoneeachelseetcevereveryfewforfromgenerallygetgogonehashavehelloherehowifinintoisjustkeeplaterletlikelotlotsmademakemakesmanymaymemoremostmuchmustmyneednonotnowofoftenononlyorotherothersouroutoverpleaseputsosomesuchthanthatthetheirthemthentherethesetheythistrytoupusverywantwaswewellwhatwhenwherewhichwhywillwithwithinyouyouryourself