【Hudi】数据湖(四):Hudi与Spark整合
Hudi与Spark整合
一、向Hudi插入数据
默认Spark操作Hudi使用表类型为Copy On Write模式。Hudi与Spark整合时有很多参数配置,可以参照https://hudi.apache.org/docs/configurations.html配置项来查询,此外,整合时有几个需要注意的点,如下:
- Hudi这里使用的是0.8.0版本,其对应使用的Spark版本是2.4.3+版本
- Spark2.4.8使用的Scala版本是2.12版本,虽然2.11也是支持的,建议使用2.12。
- maven导入包中需要保证httpclient、httpcore版本与集群中的Hadoop使用的版本一致,不然会导致通信有问题。检查Hadoop使用以上两个包的版本路径为:$HADOOP_HOME/share/hadoop/common/lib。
- 在编写代码过程中,指定数据写入到HDFS路径时直接写“/xxdir”不要写“hdfs://mycluster/xxdir”,后期会报错“java.lang.IllegalArgumentException: Not in marker dir. Marker Path=hdfs://mycluster/hudi_data/.hoodie.temp/2022xxxxxxxxxx/default/c4b854e7-51d3-4a14-9b7e-54e2e88a9701-0_0-22-22_20220509164730.parquet.marker.CREATE, Expected Marker Root=/hudi_data/.hoodie/.temp/2022xxxxxxxxxx”,可以将对应的hdfs-site.xml、core-site.xml放在resources目录下,直接会找HDFS路径。
1、创建项目,修改pom.xml为如下内容
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<scala.version>2.12.14scala.version>
<spark.version>2.4.8spark.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpclientartifactId>
<version>4.5.2version>
dependency>
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpcoreartifactId>
<version>4.4.4version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.12artifactId>
<version>${spark.version}version>
<exclusions>
<exclusion>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpclientartifactId>
exclusion>
<exclusion>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpcoreartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.12artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-avro_2.12artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_2.12artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-jdbcartifactId>
<version>1.2.1version>
dependency>
<dependency>
<groupId>org.apache.hudigroupId>
<artifactId>hudi-spark-bundle_2.12artifactId>
<version>0.8.0version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-toolsgroupId>
<artifactId>maven-scala-pluginartifactId>
<version>2.15.2version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
<plugin>
<artifactId>maven-assembly-pluginartifactId>
<version>2.4version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
<archive>
<manifest>
<mainClass>com.xxxmainClass>
manifest>
archive>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>assemblygoal>
goals>
execution>
executions>
plugin>
plugins>
build>
2、编写向Hudi插入数据代码
val session: SparkSession = SparkSession.builder().master("local").appName("insertDataToHudi")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
//关闭日志
// session.sparkContext.setLogLevel("Error")
//创建DataFrame
val insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\jsondata.json")
//将结果保存到hudi中
insertDF.write.format("org.apache.hudi")//或者直接写hudi
//设置主键列名称
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY,"id")
//当数据主键相同时,对比的字段,保存该字段大的数据
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY,"data_dt")S
//并行度设置,默认1500
.option("hoodie.insert.shuffle.parallelism","2")
.option("hoodie.upsert.shuffle.parallelism", "2")
//表名设置
.option(HoodieWriteConfig.TABLE_NAME,"person_infos")
.mode(SaveMode.Overwrite)
//注意:这里要选择hdfs路径存储,不要加上hdfs://mycluster//dir
//将hdfs 中core-site.xml 、hdfs-site.xml放在resource目录下,直接写/dir路径即可,否则会报错:java.lang.IllegalArgumentException: Not in marker dir. Marker Path=hdfs://mycluster/hudi_data/.hoodie\.temp/20220509164730/default/c4b854e7-51d3-4a14-9b7e-54e2e88a9701-0_0-22-22_20220509164730.parquet.marker.CREATE, Expected Marker Root=/hudi_data/.hoodie/.temp/20220509164730
.save("/hudi_data/person_infos")

二、指定分区向hudi中插入数据
向Hudi中存储数据时,如果没有指定分区列,那么默认只有一个default分区,我们可以保存数据时指定分区列,可以在写出时指定“DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY”选项来指定分区列,如果涉及到多个分区列,那么需要将多个分区列进行拼接生成新的字段,使用以上参数指定新的字段即可。
1、指定一个分区列
insertDF.write.format("org.apache.hudi")
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "data_dt")
//指定分区列
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "loc")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
.option(HoodieWriteConfig.TABLE_NAME, "person_infos")
.mode(SaveMode.Overwrite)
.save("/hudi_data/person_infos")

2、指定分区为多个列时,可以先拼接,后指定拼接字段当做分区列:
指定两个分区,需要拼接
//导入函数,拼接列
import org.apache.spark.sql.functions._
val endDF: DataFrame = insertDF.withColumn("partition_key", concat_ws("-", col("data_dt"), col("loc")))
endDF.write.format("org.apache.hudi")
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "data_dt")
//指定分区列,这里是拼接的列
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "partition_key")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
.option(HoodieWriteConfig.TABLE_NAME, "person_infos")
.mode(SaveMode. )
.save("/hudi_data/person_infos")

三、 读取Hudi数据
使用SparkSQL读取Hudi中的数据,无法使用读取表方式来读取,需要指定HDFS对应的路径来加载,指定的路径只需要指定到*.parquet当前路径或者上一层路径即可,路径中可以使用“*”来替代任意目录和数据。
读取数据返回的结果中除了原有的数据之外,还会携带Hudi对应的列数据,例如:hudi的主键、分区、提交时间、对应的parquet名称。
Spark读取Hudi表数据代码如下:
val session: SparkSession = SparkSession.builder().master("local").appName("queryDataFromHudi")
.getOrCreate()
//读取的数据路径下如果有分区,会自动发现分区数据,需要使用 * 代替,指定到parquet格式数据上层目录即可。
val frame: DataFrame = session.read.format("org.apache.hudi").load("/hudi_data/person_infos/*/*")
frame.createTempView("personInfos")
//查询结果
val result = session.sql(
"""
| select * from personInfos
""".stripMargin)
result.show(false)

四、更新Hudi数据
向Hudi中更新数据有如下几个特点
- 同一个分区内,向Hudi中更新数据是用主键来判断数据是否需要更新的,这里判断的是相同分区内是否有相同主键,不同分区内允许有相同主键。
- 更新数据时,如果原来数据有分区,一定要指定分区,不然就相当于是向相同表目录下插入数据,会生成对应的“default”分区。
- 向Hudi中更新数据时,与向Hudi中插入数据一样,但是写入的模式需要指定成“Append”,如果指定成“overwrite”,那么就是全覆盖了。建议使用时一直使用“Append”模式即可。
- 当更新完成之后,再一次从Hudi中查询数据时,会看到Hudi提交的时间字段为最新的时间。
这里将原有的三条数据改成如下三条数据:
#修改之前
{"id":1,"name":"zs1","age":18,"loc":"beijing","data_dt":"20210709"}
{"id":2,"name":"zs2","age":19,"loc":"shanghai","data_dt":"20210709"}
{"id":3,"name":"zs3","age":20,"loc":"beijing","data_dt":"20210709"}
#修改之后
{"id":1,"name":"ls1","age":40,"loc":"beijing","data_dt":"20210709"} --更新数据
{"id":2,"name":"ls2","age":50,"loc":"shanghai","data_dt":"20210710"} --更新数据
{"id":3,"name":"ls3","age":60,"loc":"ttt","data_dt":"20210711"} --相当于是新增数据
更新Hudi数据代码如下:
val session: SparkSession = SparkSession.builder().master("local").appName("updataDataToHudi")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
//读取修改数据
val updateDataDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\updatedata.json")
//向Hudi 更新数据
updateDataDF.write.format("org.apache.hudi") //或者直接写hudi
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "data_dt")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY,"loc")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
.option(HoodieWriteConfig.TABLE_NAME, "person_infos")
.mode(SaveMode.Append)
.save("/hudi_data/person_infos")
//查询数据
val frame: DataFrame = session.read.format("org.apache.hudi").load("/hudi_data/person_infos/*/*")
frame.createTempView("personInfos")
//查询结果
val result = session.sql(
"""
| select * from personInfos
""".stripMargin)
result.show(false)

五、 增量查询Hudi数据
Hudi可以根据我们传入的时间戳查询此时间戳之后的数据,这就是增量查询,需要注意的是增量查询必须通过以下方式在Spark中指定一个时间戳才能正常查询:
option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY,timestamp)
例如:原始数据如下:

我们可以查询“20210709220335”之后的数据,查询结果如下:

代码如下:
val session: SparkSession = SparkSession.builder().master("local").appName("updataDataToHudi")
.getOrCreate()
//关闭日志
session.sparkContext.setLogLevel("Error")
//导入隐式转换
import session.implicits._
//查询全量数据,查询对应的提交时间,找出倒数第二个时间
val basePath = "/hudi_data/person_infos"
session.read.format("hudi").load(basePath+"/*/*").createTempView("personInfos")
val df: DataFrame = session.sql("select distinct(_hoodie_commit_time) as commit_time from personInfos order by commit_time desc")
//这里获取由大到小排序的第二个值
val dt: String = df.map(row=>{row.getString(0)}).collect()(1)
//增量查询
val result:DataFrame = session.read.format("hudi")
/**
* 指定数据查询方式,有以下三种:
* val QUERY_TYPE_SNAPSHOT_OPT_VAL = "snapshot" -- 获取最新所有数据 , 默认
* val QUERY_TYPE_INCREMENTAL_OPT_VAL = "incremental" --获取指定时间戳后的变化数据
* val QUERY_TYPE_READ_OPTIMIZED_OPT_VAL = "read_optimized" -- 只查询Base文件中的数据
*
* 1) Snapshot mode (obtain latest view, based on row & columnar data)
* 2) incremental mode (new data since an instantTime)
* 3) Read Optimized mode (obtain latest view, based on columnar data)
*
* Default: snapshot
*/
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY,DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL)
//必须指定一个开始查询的时间,不指定报错
.option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY,dt)
.load(basePath+"/*/*")
result.show(false)
六、指定时间范围查询Hudi数据
Hudi还可以通过指定开始时间和结束时间来查询时间范围内的数据。如果想要查询最早的时间点到某个结束时刻的数据,开始时间可以指定成“000”。
1、向原有Hudi表“person_infos”中插入两次数据
目前hudi表中的数据如下:

先执行两次新的数据插入,两次插入数据之间的间隔时间至少为1分钟,两次插入数据代码如下:
//以下代码分两次向 HDFS /hudi_data/person_infos 路径中插入数据,两次运行至少1分钟以上
val session: SparkSession = SparkSession.builder().master("local").appName("PointTimeQueryHudi")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
//读取第一个文件,向Hudi中插入数据
val df1: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\appendData1.json")
val df2: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\appendData2.json")
//向Hudi中插入数据
df2.write.format("hudi")
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "data_dt")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "loc")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
.option(HoodieWriteConfig.TABLE_NAME, "person_infos")
.mode(SaveMode.Append)
.save("/hudi_data/person_infos")
import org.apache.spark.sql.functions._
//查询数据
session.read.format("hudi").load("/hudi_data/person_infos/*/*")
.orderBy(col("_hoodie_commit_time"))
.show(100,false)
此时,数据如下:

2、指定时间段查询Hudi中的数据
代码如下:
val session: SparkSession = SparkSession.builder().master("local").appName("PointTimeQueryHudi")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
//指定时间段,查询hudi中的数据
// val beginTime = "000"
val beginTime = "20210710002148"
val endTime = "20210710002533"
val result: DataFrame = session.read.format("hudi")
//指定增量查询
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL)
//指定查询开始时间(不包含),“000”指定为最早时间
.option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, beginTime)
//指定查询结束时间(包含)
.option(DataSourceReadOptions.END_INSTANTTIME_OPT_KEY, endTime)
.load("/hudi_data/person_infos/*/*")
result.createTempView("temp")
session.sql(
"""
| select * from temp order by _hoodie_commit_time
""".stripMargin).show(100,false)
开始时间为“000”,相当于是从头开始查询到endTime的数据:

开始时间为“20210710002148”:

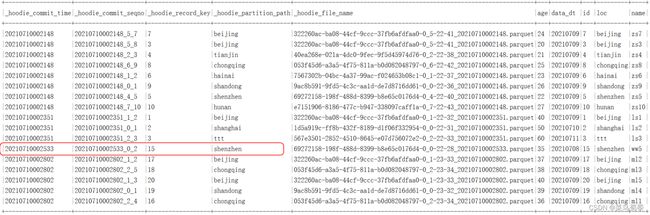
七、删除Hudi数据
我们准备对应的主键及分区的数据,将Hudi中对应的主键及分区的数据进行删除,在删除Hudi中的数据时,需要指定option(OPERATION_OPT_KEY,“delete”)配置项,并且写入模式只能是Append,不支持其他写入模式,另外,设置下删除执行的并行度,默认为1500个,这里可以设置成2个。
原始数据如下:

准备要删除的数据如下:
{"id":11,"loc":"beijing"}
{"id":12,"loc":"beijing"}
{"id":13,"loc":"beijing"}
{"id":14,"loc":"shenzhen"}
{"id":15,"loc":"tianjian"} --此条数据对应的主键一致,但是分区不一致,不能在Hudi中删除
编写代码如下:
val session: SparkSession = SparkSession.builder().master("local").appName("DeleteHudiData")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
//读取需要删除的数据,只需要准备对应的主键及分区即可,字段保持与Hudi中需要删除的字段名称一致即可
//读取的文件中准备了一个主键在Hudi中存在但是分区不再Hudi中存在的数据,此主键数据在Hudi中不能被删除,需要分区和主键字段都匹配才能删除
val deleteData: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\deleteData.json")
//将删除的数据插入到Hudi中
deleteData.write.format("hudi")
//指定操作模式为delete
.option(DataSourceWriteOptions.OPERATION_OPT_KEY,"delete")
//指定主键
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY,"id")
//指定分区字段
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY,"loc")
//指定表名,这里的表明需要与之前指定的表名保持一致
.option(HoodieWriteConfig.TABLE_NAME,"person_infos")
//设置删除并行度设置,默认1500并行度
.option("hoodie.delete.shuffle.parallelism", "2")
.mode(SaveMode.Append)
.save("/hudi_data/person_infos")
//执行完成之后,查询结果
import org.apache.spark.sql.functions._
session.read.format("hudi").load("/hudi_data/person_infos/*/*")
.orderBy(col("_hoodie_commit_time")).show(100,false)
结果如下:
八、更新Hudi某个分区数据
如果我们想要更新Hudi某个分区的数据,其他分区数据正常使用,那么可以通过配置option(DataSourceWriteOptions.OPERATION_OPT_KEY,“insert_overwrite”)选项,该选项“insert_overwrite”可以直接在元数据层面上操作,直接将写入某分区的新数据替换到该分区内,原有数据会在一定时间内删除,相比upsert更新Hudi速度要快。
1、删除person_infos对应的目录,重新插入数据,代码如下
val session: SparkSession = SparkSession.builder().master("local").appName("InsertOverWrite")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
//创建DataFrame
val insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\jsondata.json")
insertDF.write.format("org.apache.hudi")
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "data_dt")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "loc")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
.option(HoodieWriteConfig.TABLE_NAME, "person_infos")
.mode(SaveMode.Append)
.save("/hudi_data/person_infos")
//写入完成之后,查询hudi 数据:
val person_infos: DataFrame = session.read.format("hudi").load("/hudi_data/person_infos/*/*")
person_infos.show(100,false)

2、读取更新分区数据,插入到Hudi preson_infos表中
读取数据如下:
{"id":1,"name":"s1","age":1,"loc":"beijing","data_dt":"20210710"}
{"id":100,"name":"s2","age":2,"loc":"beijing","data_dt":"20210710"}
{"id":200,"name":"s3","age":3,"loc":"beijing","data_dt":"20210710"}
{"id":8,"name":"w1","age":4,"loc":"chongqing","data_dt":"20210710"}
{"id":300,"name":"w2","age":5,"loc":"chongqing","data_dt":"20210710"}
代码如下:
val session: SparkSession = SparkSession.builder().master("local").appName("InsertOverWrite")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
//读取需要替换的数据,将beijing分区数据替换成2条,将chognqing分区数据替换成1条
val overWritePartitionData: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\overWrite.json")
//写入hudi表person_infos,替换分区
overWritePartitionData.write.format("hudi")
.option(DataSourceWriteOptions.OPERATION_OPT_KEY,"insert_overwrite")
//设置主键列名称
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
//当数据主键相同时,对比的字段,保存该字段大的数据
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "data_dt")
//指定分区列
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "loc")
//并行度设置
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
//表名设置
.option(HoodieWriteConfig.TABLE_NAME, "person_infos")
.mode(SaveMode.Append)
.save("/hudi_data/person_infos")
//写入完成之后,查询hudi 数据:
val person_infos: DataFrame = session.read.format("hudi").load("/hudi_data/person_infos/*/*")
person_infos.show(100,false)

九、覆盖Hudi整个表数据
如果我们想要替换Hudi整个表数据,可以在向Hudi表写入数据时指定配置option(DataSourceWriteOptions.OPERATION_OPT_KEY,“insert_overwrite_table”)选项,该选项“insert_overwrite_table”可以直接在元数据层面上操作,直接将数据写入表,原有数据会在一定时间内删除,相比删除原有数据再插入更方便。
1、删除Hudi表person_infos对应的HDFS路径,重新插入数据
val session: SparkSession = SparkSession.builder().master("local").appName("InsertOverWrite")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
//创建DataFrame
val insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\jsondata.json")
insertDF.write.format("org.apache.hudi")
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "data_dt")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "loc")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
.option(HoodieWriteConfig.TABLE_NAME, "person_infos")
.mode(SaveMode.Append)
.save("/hudi_data/person_infos")
//写入完成之后,查询hudi 数据:
val person_infos: DataFrame = session.read.format("hudi").load("/hudi_data/person_infos/*/*")
person_infos.show(100,false)

2、读取新数据,覆盖原有Hudi表数据
覆盖更新的数据如下:
{"id":1,"name":"s1","age":1,"loc":"beijing","data_dt":"20210710"}
{"id":100,"name":"s2","age":2,"loc":"beijing","data_dt":"20210710"}
{"id":200,"name":"s3","age":3,"loc":"beijing","data_dt":"20210710"}
{"id":8,"name":"w1","age":4,"loc":"chongqing","data_dt":"20210710"}
{"id":300,"name":"w2","age":5,"loc":"chongqing","data_dt":"20210710"}
代码如下:
val session: SparkSession = SparkSession.builder().master("local").appName("InsertOverWrite")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
//读取需要替换的数据,覆盖原有表所有数据
val overWritePartitionData: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\overWrite.json")
//写入hudi表person_infos,替换分区
overWritePartitionData.write.format("hudi")
.option(DataSourceWriteOptions.OPERATION_OPT_KEY,"insert_overwrite_table")
//设置主键列名称
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
//当数据主键相同时,对比的字段,保存该字段大的数据
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "data_dt")
//指定分区列
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "loc")
//并行度设置
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
//表名设置
.option(HoodieWriteConfig.TABLE_NAME, "person_infos")
.mode(SaveMode.Append)
.save("/hudi_data/person_infos")
//写入完成之后,查询hudi 数据:
val person_infos: DataFrame = session.read.format("hudi").load("/hudi_data/person_infos/*/*")
person_infos.show(100,false)

十、Spark操作Hudi Merge On Read 模式
默认Spark操作Hudi使用Copy On Write模式,也可以使用Merge On Read 模式,通过代码中国配置如下配置来指定:
option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY,DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL)
代码操作如下:
- 删除原有person_infos对应的HDFS路径
- 读取数据向Hudi表person_info中插入数据
读取的数据如下:
{"id":1,"name":"zs1","age":18,"loc":"beijing","data_dt":"20210709"}
{"id":2,"name":"zs2","age":19,"loc":"shanghai","data_dt":"20210709"}
{"id":3,"name":"zs3","age":20,"loc":"beijing","data_dt":"20210709"}
{"id":4,"name":"zs4","age":21,"loc":"tianjin","data_dt":"20210709"}
{"id":5,"name":"zs5","age":22,"loc":"shenzhen","data_dt":"20210709"}
{"id":6,"name":"zs6","age":23,"loc":"hainai","data_dt":"20210709"}
{"id":7,"name":"zs7","age":24,"loc":"beijing","data_dt":"20210709"}
{"id":8,"name":"zs8","age":25,"loc":"chongqing","data_dt":"20210709"}
{"id":9,"name":"zs9","age":26,"loc":"shandong","data_dt":"20210709"}
{"id":10,"name":"zs10","age":27,"loc":"hunan","data_dt":"20210709"}
代码如下:
//1.读取json格式数据
val insertDf: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\jsondata.json")
//2.将结果使用Merge on Read 模式写入到Hudi中,并设置分区
insertDf.write.format("hudi")
//设置表模式为 mor
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY,DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY,"id")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY,"loc")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY,"data_dt")
//并行度设置
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
//表名设置
.option(HoodieWriteConfig.TABLE_NAME, "person_infos")
.mode(SaveMode.Append)
.save("/hudi_data/person_infos")

- 更新Hudi表person_info数据
这里更新“beijing”、“shanghai”、“ttt”分区数据,更新数据如下:
{"id":1,"name":"ls1","age":40,"loc":"beijing","data_dt":"20210709"}
{"id":2,"name":"ls2","age":50,"loc":"shanghai","data_dt":"20210710"}
{"id":3,"name":"ls3","age":60,"loc":"ttt","data_dt":"20210711"}
代码如下:
//3.读取更新数据,并执行插入更新
val updateDf: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\updatedata.json")
updateDf.write.format("hudi")
//设置表模式为 mor
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY,DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY,"id")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY,"loc")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY,"data_dt")
//并行度设置
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
//表名设置
.option(HoodieWriteConfig.TABLE_NAME, "person_infos")
.mode(SaveMode.Append)
.save("/hudi_data/person_infos")
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C8ysQGwo-1655007786956)(https://ask.qcloudimg.com/http-save/1159019/738d1e7a3a1220020f06ee6a56a33903.png?imageView2/2/w/1620)]
- 增量查询Hudi表中的数据
Snapshot 模式查询,这种模式对于COW或者MOR模式都是查询到当前时刻全量的数据,如果有更新,那么就是更新之后全量的数据:
//4.使用不同模式查询 MOR 表中的数据
/**
* 指定数据查询方式,有以下三种:
* val QUERY_TYPE_SNAPSHOT_OPT_VAL = "snapshot" -- 获取最新所有数据 , 默认
* val QUERY_TYPE_INCREMENTAL_OPT_VAL = "incremental" --获取指定时间戳后的变化数据
* val QUERY_TYPE_READ_OPTIMIZED_OPT_VAL = "read_optimized" -- 只查询Base文件中的数据
*
* 1) Snapshot mode (obtain latest view, based on row & columnar data)
* 2) incremental mode (new data since an instantTime)
* 3) Read Optimized mode (obtain latest view, based on columnar data)
*
* Default: snapshot
*/
//4.1 Snapshot 模式查询
session.read.format("hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY,DataSourceReadOptions.QUERY_TYPE_SNAPSHOT_OPT_VAL)
.load("/hudi_data/person_infos/*/*")
.show(100,false)

incremental 模式查询,这种模式需要指定一个时间戳,查询指定时间戳之后的新增数据:
//4.2 incremental 模式查询,查询指定时间戳后的数据
session.read.format("hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY,DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL)
//必须指定一个开始查询的时间,不指定报错
.option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY,"20210710171240")
.load("/hudi_data/person_infos/*/*")
.show(100,false)

Read Optimized 模式查询,这种模式只查询Base中的数据,不会查询MOR中Log文件中的数据,代码如下:
//4.3 Read Optimized 模式查询,查询Base中的数据,不会查询log中的数据
session.read.format("hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY,DataSourceReadOptions.QUERY_TYPE_READ_OPTIMIZED_OPT_VAL)
.load("/hudi_data/person_infos/*/*")
.show(100,false)

十一、测试COW模式parquet文件删除与MOR模式Parquet文件与log文件Compact
COW默认情况下,每次更新数据Commit都会基于之前parquet文件生成一个新的Parquet Base文件数据,默认历史parquet文件数为10,当超过10个后会自动删除旧的版本,可以通过参数“hoodie.cleaner.commits.retained”来控制保留的FileID版本文件数,默认是10。测试代码如下:
val session: SparkSession = SparkSession.builder().master("local").appName("insertDataToHudi")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
//创建DataFrame
val insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\test\\insertdata1.json")
// val insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\test\\insertdata2.json")
// val insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\test\\insertdata3.json")
// val insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\test\\insertdata4.json")
// val insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\test\\insertdata5.json")
// val insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\test\\insertdata6.json")
// val insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\test\\insertdata7.json")
// val insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\test\\insertdata8.json")
// val insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\test\\insertdata9.json")
// val insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\test\\insertdata10.json")
insertDF.write.format("org.apache.hudi")
//设置cow模式
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY,DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL)
//根据commit提交次数计算保留多少个fileID版本文件,默认10。
.option("hoodie.cleaner.commits.retained","3")
//设置主键列名称
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
//当数据主键相同时,对比的字段,保存该字段大的数据
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "data_dt")
//并行度设置,默认1500并行度
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
//表名设置
.option(HoodieWriteConfig.TABLE_NAME, "person_infos")
.mode(SaveMode.Append)
.save("/hudi_data/test_person")
//查询结果数据
session.read.format("hudi")
//全量读取
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY,DataSourceReadOptions.QUERY_TYPE_SNAPSHOT_OPT_VAL)
.load("/hudi_data/test_person/*/*").show()
测试注意:每次运行代码,读取新的一个数据文件,并查看Hudi表对应的HDFS路径,每次读取都会生成一个新的Parquet文件,当达到指定的3个历史版本时(不包含最新Parquet文件),再插入数据生成新的Parquet文件时,一致会将之前的旧版本删除,保存4个文件。

MOR模式下,如果有新增数据会直接写入Base Parquet文件,这个Parquet文件个数的控制也是由“hoodie.cleaner.commits.retained”控制,默认为10。当对应的每个FlieSlice(Base Parquet文件+log Avro文件)中有数据更新时,会写入对应的log Avro文件,那么这个文件何时与Base Parquet文件进行合并,这个是由参数“hoodie.compact.inline.max.delta.commits”决定的,这个参数意思是在提交多少次commit后触发压缩策略,默认是5,也就是当前FlieSlice中如果有5次数据更新就会两者合并生成全量的数据,当前FlieSlice还是这个FileSlice名称,只不过对应的parquet文件中是全量数据,再有更新数据还是会写入当前FileSlice对应的log日志文件中。使“hoodie.compact.inline.max.delta.commits”参数起作用,默认必须开启“hoodie.compact.inline”,此值代表是否完成提交数据后进行压缩,默认是false。
测试代码如下:
#注意代码中设置参数如下:
//根据commit提交次数计算保留多少个fileID版本文件,默认10。
.option("hoodie.cleaner.commits.retained","3")
//默认false:是否在一个事务完成后内联执行压缩操作
.option("hoodie.compact.inline","true")
//设置提交多少次后触发压缩策略,默认5
.option("hoodie.compact.inline.max.delta.commits","2")
#完整代码如下:
val session: SparkSession = SparkSession.builder().master("local").appName("insertDataToHudi")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
//创建DataFrame ,新增
// val insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\test\\insertdata1.json")
//创建DataFrame ,更新
val insertDF: DataFrame = session.read.json("file:///D:\\2022IDEA_space\\SparkOperateHudi\\data\\test\\update11.json")
insertDF.write.format("org.apache.hudi") //或者直接写hudi
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY,DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL)
//根据commit提交次数计算保留多少个fileID版本文件,默认10。
.option("hoodie.cleaner.commits.retained","3")
//默认false:是否在一个事务完成后内联执行压缩操作
.option("hoodie.compact.inline","true")
//设置提交多少次后触发压缩策略,默认5
.option("hoodie.compact.inline.max.delta.commits","2")
//设置主键列名称
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
//当数据主键相同时,对比的字段,保存该字段大的数据
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "data_dt")
//并行度设置,默认1500并行度
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
//表名设置
.option(HoodieWriteConfig.TABLE_NAME, "person_infos")
.mode(SaveMode.Append)
.save("/hudi_data/test_person")
//查询结果数据
session.read.format("hudi")
//全量读取
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY,DataSourceReadOptions.QUERY_TYPE_SNAPSHOT_OPT_VAL)
.load("/hudi_data/test_person/*/*").show()
第一次运行插入数据,commit,路径对应数据目录如下:

第一次运行更新数据,commit,路径对应数据目录如下:

第二次运行更新数据,commit,路径对应的数据目录如下:

第三次运行更新数据,commit,路径对应的数据目录如下:

第四次运行更新数据,commit,路径对应的数据目录如下:

第五次运行更新数据,commit,路径对应的目录数据如下:

本文分享自作者个人站点/博客:https://lansonli.blog.csdn.net/复制
如有侵权,请联系本人
删除。