hudi详解并集成spark实现快照查询和增量读取数据
1.什么是Hudi?
2.Hudi对HDFS可以实现哪些操作?
3.Hudi与其它组件对比有哪些特点?
Hudi是在HDFS的基础上,对HDFS的管理和操作。支持在Hadoop上执行upserts/insert/delete操作。这里大家可能觉得比较抽象,那么它到底解决了哪些问题?
Hudi解决了我们那些痛点
1.实时获取新增数据
你是否遇到过这样的问题,使用Sqoop获取Mysql日志或则数据,然后将新增数据迁移到Hive或则HDFS。对于新增的数据,有不少公司确实是这么做的,比较高级点的,通过Shell调用Sqoop迁移数据实现自动化,但是这里面有很多的坑和难点,相对来说工作量也不少,那么有没有更好的解决办法那?—Hudi可以解决。Hudi可以实时获取新数据。
2.实时查询、分析
对于HDFS数据,我们要查询数据,是需要使用MapReduce的,我们使用MapReduce查询,这几乎是让我们难以接受的,有没有近实时的方案,有没有更好的解决方案–Hudi。
什么是Hudi
Apache Hudi代表Hadoop Upserts anD Incrementals,管理大型分析数据集在HDFS上的存储。Hudi的主要目的是高效减少摄取过程中的数据延迟。由Uber开发并开源,HDFS上的分析数据集通过两种类型的表提供服务:读优化表(Read Optimized Table)和近实时表(Near-Real-Time Table)。
读优化表的主要目的是通过列式存储提供查询性能,而近实时表则提供实时(基于行的存储和列式存储的组合)查询。
Hudi是一个开源Spark库(基于Spark2.x),用于在Hadoop上执行诸如更新,插入和删除之类的操作。它还允许用户仅摄取更改的数据,从而提高查询效率。它可以像任何作业一样进一步水平扩展,并将数据集直接存储在HDFS上。
Hudi的作用
上面还是比较抽象的话,接着我们来看下图,更形象的来了解Hudi

我们看到数据库、Kafka更改会传递到Hudi,Hudi提供了三个逻辑视图:
- 1.读优化视图 - 在纯列式存储上提供出色的查询性能,非常像parquet表。
- 2.增量视图 - 在数据集之上提供一个变更流并提供给下游的作业或ETL任务。
- 3.准实时的表 - 使用基于列存储(例如 Parquet + Avro)和行存储以提供对实时数据的查询
我们看到直接在HDFS上存储数据,是可以用于Presto和Spark等交互式SQL引擎。
Hudi机制
存储机制
hudi维护了一个时间轴,记录了在不同时刻对数据集进行的所有操作。
hudi拥有2种存储优化。
读优化(Copy On Write):在每次commit后都将最新的数据compaction成列式存储(parquet);
写优化(Merge On Read):对增量数据使用行式存储(avro),后台定期将它compaction成列式存储。
读数据
hudi维护着一个索引,以支持在记录key存在情况下,将新记录的key快速映射到对应的fileId。索引的实现是插件式的,默认是bloomFilter,也可以使用HBase。
hudi提供3种查询视图。
读优化视图:仅提供compaction后的列式存储的数据;
增量视图:仅提供一次compaction/commit前的增量数据;
实时视图:包括读优化的列式存储数据和写优化的行式存储数据。
更新数据
hudi写数据的时候需要指定PRECOMBINE_FIELD_OPT_KEY、RECORDKEY_FIELD_OPT_KEY和PARTITIONPATH_FIELD_OPT_KEY。
RECORDKEY_FIELD_OPT_KEY:每条记录的唯一id,支持多个字段;
PRECOMBINE_FIELD_OPT_KEY:在数据合并的时候使用到,当 RECORDKEY_FIELD_OPT_KEY 相同时,默认取 PRECOMBINE_FIELD_OPT_KEY 属性配置的字段最大值所对应的行;
PARTITIONPATH_FIELD_OPT_KEY:用于存放数据的分区字段。
hudi更新数据和插入数据很相似(写法几乎一样),更新数据时,会根据 RECORDKEY_FIELD_OPT_KEY、PRECOMBINE_FIELD_OPT_KEY 以及 PARTITIONPATH_FIELD_OPT_KEY三个字段对数据进行Merge。
spark与hudi的集成
Hudi 适用于 Spark-2.4.3+ 和 Spark 3.x 版本。因此spark版本需要对应,不过spark和hudi的集成比起flink和Hudi的集成方便很多,毕竟hudi的设计之初就是为了融合spark,而且hudi和spark耦合性很高。现在hudi社区正在做的是实现对于hudi和spark的解耦,不受限于某个数据引擎,这也是hudi一大缺陷,但是社区正在积极推进此项工作,很多大公司也加入进来,如阿里,字节跳动,腾讯等等。而且使用在大数据领域hudi的发展势头很强劲,越来越多的人加入到其中。
设置spark-shell
首先在服务器中通过spark-shell命令来引入hudi包
下面的命令是适用于spark3.0+,具体细节可以参考hudi官网教程
spark-shell \
--packages org.apache.hudi:hudi-spark3-bundle_2.12:0.10.0,org.apache.spark:spark-avro_2.12:3.1.2 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
执行成功如上图,但是第一次执行的话会比较慢,因为需要远程拉取hudi包,第一次成功后,后面就比较快。
设置表名、基本路径和数据生成器来为本指南生成记录。
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_cow_table"
val basePath = "file:///tmp/hudi_cow_table"
val dataGen = new DataGenerator

数据生成器 可以基于行程样本模式 生成插入和更新的样本。
插入数据
生成一些新的行程样本,将其加载到DataFrame中,然后将DataFrame写入Hudi数据集中,如下所示。
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath);
执行时遇到一个问题,就是插入数据之后需要提交任务,由于服务器配置并不高,而且我还启动了hadoop集群造成内存不足,直接把进程杀掉了,这边我把hadoop集群停掉,杀掉一些占内存的进程,就可以解决问题了。

经过一番操作解决了上述问题,成功插入数据,可以看到hudi表的存储路径
其中,mode(Overwrite)覆盖并重新创建数据集(如果已经存在)。 您可以检查在/tmp/hudi_cow_table下生成的数据。我们提供了一个记录键 (schema中的uuid),分区字段(region/county/city)和组合逻辑(schema中的ts) 以确保行程记录在每个分区中都是唯一的。
查询数据
将数据文件加载到DataFrame中。
val roViewDF = spark.
read.
format("org.apache.hudi").
load(basePath + "/*/*/*/*")
roViewDF.registerTempTable("hudi_ro_table")
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_ro_table where fare > 20.0").show()
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_ro_table").show()

该查询提供已提取数据的读取优化视图。由于我们的分区路径(region/country/city)是嵌套的3个级别 从基本路径开始,我们使用了load(basePath + “////”)
更新数据
这类似于插入新数据。使用数据生成器生成对现有行程的更新,加载到DataFrame中并将DataFrame写入hudi数据集。
val updates = convertToStringList(dataGen.generateUpdates(10))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 2));
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath);
成功将数据更新到了hudi表中
注意,保存模式现在为追加。通常,除非你是第一次尝试创建数据集,否则始终使用追加模式。 查询现在再次查询数据将显示更新的行程。每个写操作都会生成一个新的由时间戳表示的commit 。在之前提交的相同的_hoodie_record_key中寻找_hoodie_commit_time, rider, driver字段变更。
增量查询
Hudi还提供了获取给定提交时间戳以来已更改的记录流的功能。 这可以通过使用Hudi的增量视图并提供所需更改的开始时间来实现。 如果我们需要给定提交之后的所有更改(这是常见的情况),则无需指定结束时间。

特定时间点查询
我们可以通过将结束时间指向特定的提交时间,将开始时间指向"000"(表示最早的提交时间)来表示特定时间。
val beginTime = "000" // Represents all commits > this time.
val endTime = commits(commits.length - 2) // commit time we are interested in
// 增量查询数据
val incViewDF = spark.read.format("org.apache.hudi").
option(VIEW_TYPE_OPT_KEY, VIEW_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
option(END_INSTANTTIME_OPT_KEY, endTime).
load(basePath);
incViewDF.registerTempTable("hudi_incr_table")
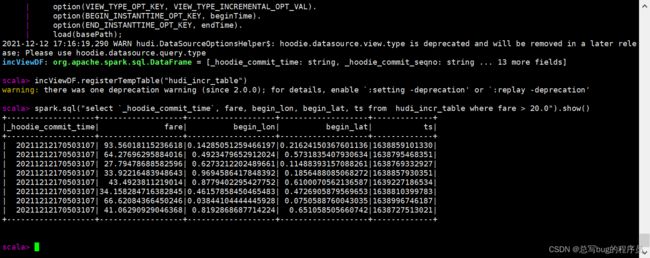
spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_incr_table where fare > 20.0").show()
使用案例
近实时摄取
将外部源(如事件日志、数据库、外部源)的数据摄取到Hadoop数据湖是一个众所周知的问题。 尽管这些数据对整个组织来说是最有价值的,但不幸的是,在大多数(如果不是全部)Hadoop部署中都使用零散的方式解决,即使用多个不同的摄取工具。
对于RDBMS摄取,Hudi提供 通过更新插入达到更快加载,而不是昂贵且低效的批量加载。例如,您可以读取MySQL BIN日志或Sqoop增量导入并将其应用于 DFS上的等效Hudi表。这比批量合并任务及复杂的手工合并工作流更快/更有效率。
对于NoSQL数据存储,如Cassandra / Voldemort / HBase,即使是中等规模大小也会存储数十亿行。 毫无疑问, 全量加载不可行,如果摄取需要跟上较高的更新量,那么则需要更有效的方法。
即使对于像Kafka这样的不可变数据源,Hudi也可以 强制在HDFS上使用最小文件大小, 这采取了综合方式解决HDFS小文件问题来改善NameNode的健康状况。这对事件流来说更为重要,因为它通常具有较高容量(例如:点击流),如果管理不当,可能会对Hadoop集群造成严重损害。
在所有源中,通过commits这一概念,Hudi增加了以原子方式向消费者发布新数据的功能,这种功能十分必要。
近实时分析
通常,实时数据集市由专业(实时)数据分析存储提供支持,例如Druid或Memsql或OpenTSDB。 这对于较小规模的数据量来说绝对是完美的(相比于这样安装Hadoop),这种情况需要在亚秒级响应查询,例如系统监控或交互式实时分析。 但是,由于Hadoop上的数据太陈旧了,通常这些系统会被滥用于非交互式查询,这导致利用率不足和硬件/许可证成本的浪费。
另一方面,Hadoop上的交互式SQL解决方案(如Presto和SparkSQL)表现出色,在 几秒钟内完成查询。 通过将 数据新鲜度提高到几分钟,Hudi可以提供一个更有效的替代方案,并支持存储在DFS中的 数量级更大的数据集 的实时分析。 此外,Hudi没有外部依赖(如专用于实时分析的HBase集群),因此可以在更新的分析上实现更快的分析,而不会增加操作开销。
增量处理管道
Hadoop提供的一个基本能力是构建一系列数据集,这些数据集通过表示为工作流的DAG相互派生。 工作流通常取决于多个上游工作流输出的新数据,新数据的可用性传统上由新的DFS文件夹/Hive分区指示。 让我们举一个具体的例子来说明这点。上游工作流U可以每小时创建一个Hive分区,在每小时结束时(processing_time)使用该小时的数据(event_time),提供1小时的有效新鲜度。 然后,下游工作流D在U结束后立即启动,并在下一个小时内自行处理,将有效延迟时间增加到2小时。
上面的示例忽略了迟到的数据,即processing_time和event_time分开时。 不幸的是,在今天的后移动和前物联网世界中,来自间歇性连接的移动设备和传感器的延迟数据是常态,而不是异常。 在这种情况下,保证正确性的唯一补救措施是重新处理最后几个小时的数据, 每小时一遍又一遍,这可能会严重影响整个生态系统的效率。例如; 试想一下,在数百个工作流中每小时重新处理TB数据。
Hudi通过以单个记录为粒度的方式(而不是文件夹/分区)从上游 Hudi数据集HU消费新数据(包括迟到数据),来解决上面的问题。 应用处理逻辑,并使用下游Hudi数据集HD高效更新/协调迟到数据。在这里,HU和HD可以以更频繁的时间被连续调度 比如15分钟,并且HD提供端到端30分钟的延迟。
为实现这一目标,Hudi采用了类似于Spark Streaming、发布/订阅系统等流处理框架,以及像Kafka 或Oracle XStream等数据库复制技术的类似概念。 如果感兴趣,可以在这里找到有关增量处理(相比于流处理和批处理)好处的更详细解释。
DFS的数据分发
一个常用场景是先在Hadoop上处理数据,然后将其分发回在线服务存储层,以供应用程序使用。 例如,一个Spark管道可以确定Hadoop上的紧急制动事件并将它们加载到服务存储层(如ElasticSearch)中,供Uber应用程序使用以增加安全驾驶。这种用例中,通常架构会在Hadoop和服务存储之间引入队列,以防止目标服务存储被压垮。 对于队列的选择,一种流行的选择是Kafka,这个模型经常导致 在DFS上存储相同数据的冗余(用于计算结果的离线分析)和Kafka(用于分发)
通过将每次运行的Spark管道更新插入的输出转换为Hudi数据集,Hudi可以再次有效地解决这个问题,然后可以以增量方式获取尾部数据(就像Kafka topic一样)然后写入服务存储层。
Hudi与其它组件对比
Apache Hudi填补了在DFS上处理数据的巨大空白,并可以和这些技术很好地共存。然而, 通过将Hudi与一些相关系统进行对比,来了解Hudi如何适应当前的大数据生态系统,并知晓这些系统在设计中做的不同权衡仍将非常有用。
Kudu
Apache Kudu是一个与Hudi具有相似目标的存储系统,该系统通过对upserts支持来对PB级数据进行实时分析。 一个关键的区别是Kudu还试图充当OLTP工作负载的数据存储,而Hudi并不希望这样做。 因此,Kudu不支持增量拉取(截至2017年初),而Hudi支持以便进行增量处理。
Kudu与分布式文件系统抽象和HDFS完全不同,它自己的一组存储服务器通过RAFT相互通信。 与之不同的是,Hudi旨在与底层Hadoop兼容的文件系统(HDFS,S3或Ceph)一起使用,并且没有自己的存储服务器群,而是依靠Apache Spark来完成繁重的工作。 因此,Hudi可以像其他Spark作业一样轻松扩展,而Kudu则需要硬件和运营支持,特别是HBase或Vertica等数据存储系统。 到目前为止,我们还没有做任何直接的基准测试来比较Kudu和Hudi(鉴于RTTable正在进行中)。 但是,如果我们要使用CERN, 我们预期Hudi在摄取parquet上有更卓越的性能。
Hive事务
Hive事务/ACID是另一项类似的工作,它试图实现在ORC文件格式之上的存储读取时合并。 可以理解,此功能与Hive以及LLAP之类的其他工作紧密相关。 Hive事务不提供Hudi提供的读取优化存储选项或增量拉取。 在实现选择方面,Hudi充分利用了类似Spark的处理框架的功能,而Hive事务特性则在用户或Hive Metastore启动的Hive任务/查询的下实现。 根据我们的生产经验,与其他方法相比,将Hudi作为库嵌入到现有的Spark管道中要容易得多,并且操作不会太繁琐。 Hudi还设计用于与Presto/Spark等非Hive引擎合作,并计划引入除parquet以外的文件格式。
HBase
尽管HBase最终是OLTP工作负载的键值存储层,但由于与Hadoop的相似性,用户通常倾向于将HBase与分析相关联。 鉴于HBase经过严格的写优化,它支持开箱即用的亚秒级更新,Hive-on-HBase允许用户查询该数据。 但是,就分析工作负载的实际性能而言,Parquet/ORC之类的混合列式存储格式可以轻松击败HBase,因为这些工作负载主要是读取繁重的工作。 Hudi弥补了更快的数据与分析存储格式之间的差距。从运营的角度来看,与管理分析使用的HBase region服务器集群相比,为用户提供可更快给出数据的库更具可扩展性。 最终,HBase不像Hudi这样重点支持提交时间、增量拉取之类的增量处理原语。
流式处理
一个普遍的问题:“Hudi与流处理系统有何关系?”,我们将在这里尝试回答。简而言之,Hudi可以与当今的批处理(写时复制存储)和流处理(读时合并存储)作业集成,以将计算结果存储在Hadoop中。 对于Spark应用程序,这可以通过将Hudi库与Spark/Spark流式DAG直接集成来实现。在非Spark处理系统(例如Flink、Hive)情况下,可以在相应的系统中进行处理,然后通过Kafka主题/DFS中间文件将其发送到Hudi表中。从概念上讲,数据处理 管道仅由三个部分组成:输入,处理,输出,用户最终针对输出运行查询以便使用管道的结果。Hudi可以充当将数据存储在DFS上的输入或输出。Hudi在给定流处理管道上的适用性最终归结为你的查询在Presto/SparkSQL/Hive的适用性。
更高级的用例围绕增量处理的概念展开, 甚至在处理引擎内部也使用Hudi来加速典型的批处理管道。例如:Hudi可用作DAG内的状态存储(类似Flink使用的[rocksDB(https://ci.apache.org/projects/flink/flink-docs-release-1.2/ops/state_backends.html#the-rocksdbstatebackend))。 这是路线图上的一个项目并将最终以Beam Runner的形式呈现。
Hudi源码
hudi现在在蓬勃发展,虽说它在某些功能很出色,但是也存在一些缺陷,hudi社区也在更进一步完善,现在hudi已经更新到0.10版本,解决了上个版本的一些问题,新增了一些特性,如果你对于hudi比较感兴趣可以对源码进行fork,若是能发现一些问题或者做一些改进,可以将代码提交,成为hudi的开源贡献者。