一次Python爬虫实战,解决反爬问题!
人生苦短,快学Python!
随着互联网的发展,Python的崛起,很多网站经常被外面的爬虫程序骚扰,有什么方法可以阻止爬虫吗?
阻止爬虫也就称之为反爬虫,反爬虫涉及到的技术比较综合,说简单也简单,说复杂也复杂,看具体要做到哪种保护程度了。
针对于不同的网站,它的反爬措施不一样,常见的反爬有User-Agent、ip代理、cookie认证,js加密等等,与之对应所保护的数据也不一样。比如某宝某猫等电商网站,那么店铺信息用户信息就比较重要了,像是某眼电影网站,它对于电影评分,票房等信息做了反爬处理。
我们今天的采集目标网站是某论坛,当对其文章的文本数据进行采集时,但是发现有字体反爬措施,就是有的文本数据被替换了。(文末附python学习资料)
一、需求分析
我们是需要爬取论坛文本数据,如下图所示:
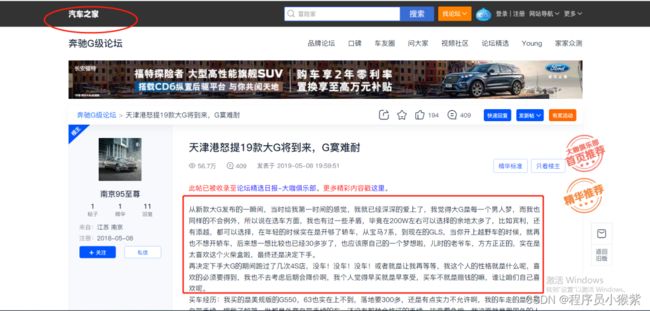
部分网页源码展示:

我们发现文本数据是在网页源码里面的。
二、发起请求
import requests
url = "https://club.autohome.com.cn/bbs/thread/665330b6c7146767/80787515-1.html"
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"}
r = requests.get(url, headers=header)
html = etree.HTML(r.text)
content = html.xpath("//div[@class='tz-paragraph']//text()")
print(content)
然后得到如下数据(部分数据截图):

虽然在网页源码里面存在目标数据,但是通过requests简单请求之后发现有的文字被特殊字符替换掉了,此时再次查看Elenments对应的标签里的数据,如下图所示:
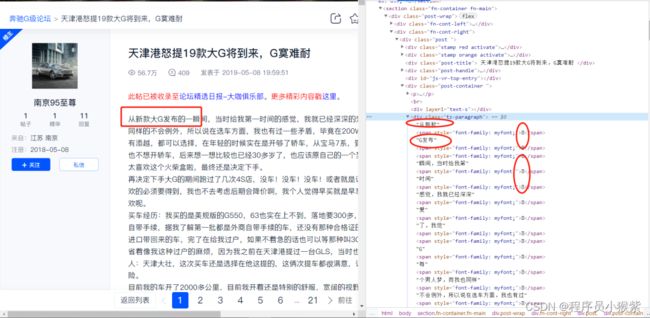
由图可以发现有的字被替换掉了,所以我们需要找到汉字被替换的方式,然后替换回去。
三、字体替换
我们知道系统字体一般都是xxxx.ttf的文件形式,如下图所示:
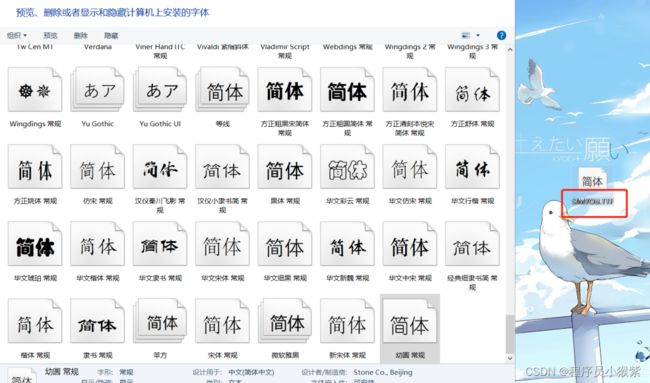
通过检查发现该网站中使用的字体对应的是myfont,这个很明显是网站为了反爬设置的自定义的字体:
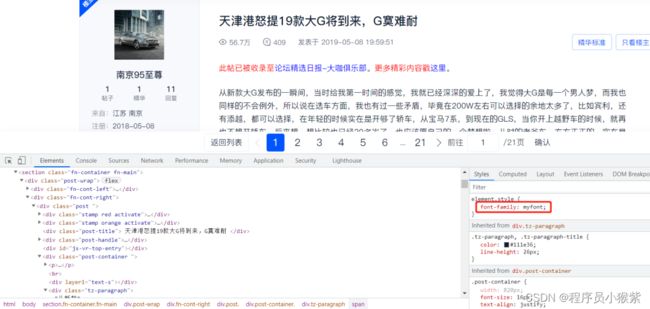
了解css的伙计应该知道,网页的字体样式放在了style标签里面,如下图所示:
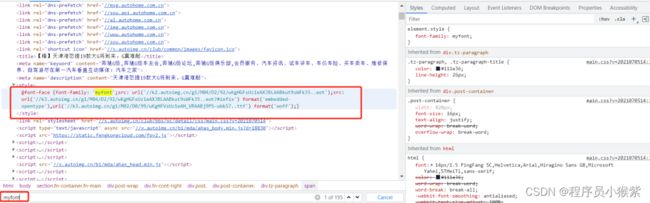
然后拿到url对应属性(xxx57…ttf),
//k3.autoimg.cn/g1/M02/D0/99/wKgHFVsUz1eAH_VRAABj9PS-ubk57…ttf
查看后发现是一个字体文件:

然后打开字体查看文件,把字体文件拖拽进去,如下图所示:(使用软件为FontCreator,可以查看字体的软件)
如果不想使用软件,可以打开百度字体平台网站,对应页面和软件打开是一样的
粗略一看其实发现不了什么,所以我们需要使用fontTools第三方库查看字体文件:

from fontTools.ttLib import TTFont
font = TTFont('./wKgHFVsUz1eAH_VRAABj9PS-ubk57..ttf')
print(font.getGlyphOrder())
结果如下图所示:

然后我们发现比如在先前的特殊字符表中,

这三个字应该分别对应于,大 、的、一,首先大对应的后缀为edb8,在字体文件的输出的列表中中有一个uniEDB8,对应于第六个,然后再FontCreator软件中刚好对应第六个汉字大,如下图所示:
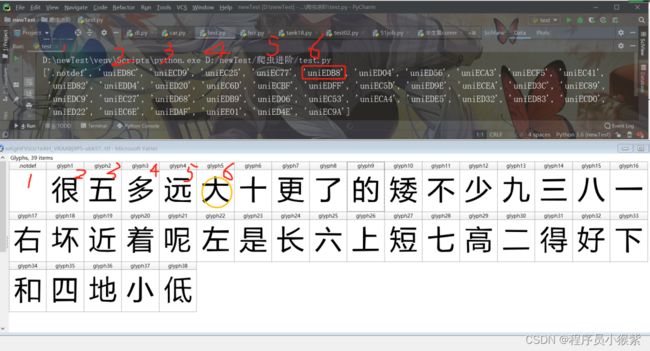
所以规律就是这样的。
四、数据抓取
1、先把对应的汉字打出来储存在一个列表中;
word_list = ['很', '五', '多', '远', '大', '十', '更', '了', '的', '矮', '不', '少', '九', '三', '八', '一', '右', '坏', '近', '着', '呢','左', '是', '长', '六', '上', '短', '七', '高', '二', '得', '好', '下', '和', '四', '地', '小', '低']
2、把字体文件对应的特殊字符保存到另一个列表中,边进行处理;
font = TTFont('wKgHFVsUz1eAH_VRAABj9PS-ubk57..ttf')
unilist = font.getGlyphOrder()
uni_list = []
for i in unilist[1:]:
s = r'\u' + i[3:]
uni_list.append(s)
print(uni_list)
但是问题出现了,结果如下:

我们发现出现了两个反斜线,所以需要使用eval函数简单修改:
font = TTFont('wKgHFVsUz1eAH_VRAABj9PS-ubk57..ttf')
unilist = font.getGlyphOrder()
# print(unilist)
uni_list = []
for i in unilist[1:]:
# print(i)
s = eval(r"'\u" + i[3:] + "'")
# print(s)
uni_list.append(s)
3、由于之前得到的不完整的文章数据是以一个列表的形式,所以需要把他拼接为字符串,然后使用replace(old,new),进行替换:
# ....前面代码省略
html = etree.HTML(result) # result为请求网页源码
content = html.xpath("//div[@class='tz-paragraph']//text()")
contents = ''.join(content)
4、最后进行替换:
for i in range(len(uni_list)):
contents = contents.replace(uni_list[i], word_list[i])
print(contents)
结果如下,文字替换成功:

五、小结
通常在爬取一些网站的信息时,偶尔会碰到这样一种情况:网页浏览显示是正常的,用 Python 爬取下来是乱码,F12用开发者模式查看网页源代码也是乱码。这种一般是网站设置了字体反爬。
字体反爬是一种比较常见的反爬方式,因为很多网站的文字信息是比较重要的,像是前面提到的猫眼电影电影票房评分等数据,非常重要,网站维护者当然会把这种数据进行反爬处理,只要好好分析,还是能够抓取到目标数据。
在学习python中有任何困难不懂的可以扫码加入python交流学习,多多交流问题,互帮互助,这里有不错的学习教程和开发工具。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、Python练习题
检查学习结果。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


最后,千万别辜负自己当时开始的一腔热血,一起变强大变优秀。