卷积层TSNE可视化
很多小伙伴经常问,怎么把卷积层的输出提取出来,然后画曲线、可视化、连接到其他网络等等问题,由于本人使用的是基于keras和tensorflow框架的Spyder软件编写的代码,因此对别的软件怎么输出参数不清楚,单说spyder,往往经过卷积层后提取到的特征形式是:样本数量×特征长度×特征维度,因此即使输出来也是很操蛋的就一个样本长度为特征长度而且仅仅第一个维度的数据。使用这些数据去绘图很难,因为输出来的一个样本的数据并不是一条,而是经过堆叠成的数据。
但用这些数据来做一些可视化和连接到其他网络还是可以的。
以可视化为例,前面有过卷积层可视化,但并不能从图中得到有效信息。因此用这些数据做TSNE可视化试试看。由于卷积层输出来的数据是样本数量×特征长度×特征维度,而tsne输入是样本数乘特征数,因此需要将:样本数量×特征长度×特征维度重新reshape成样本数×特征数的形式。先看一下效果图,首先展示神经网络对数据进行二分类,观察每个卷积层的TSNE可视化情况:
1、原始数据TSNE

2、第一个卷积层等不在意义叙述:







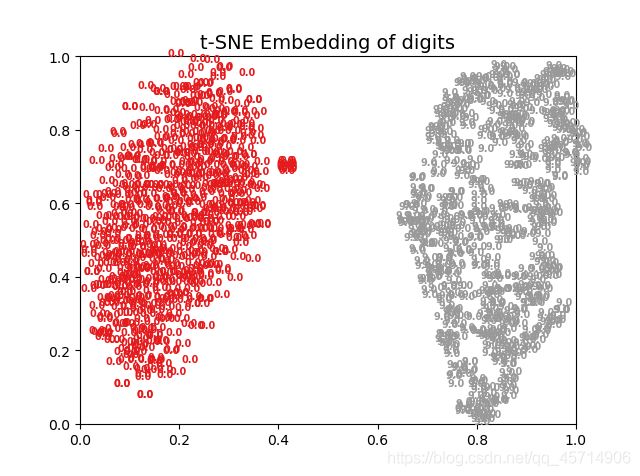


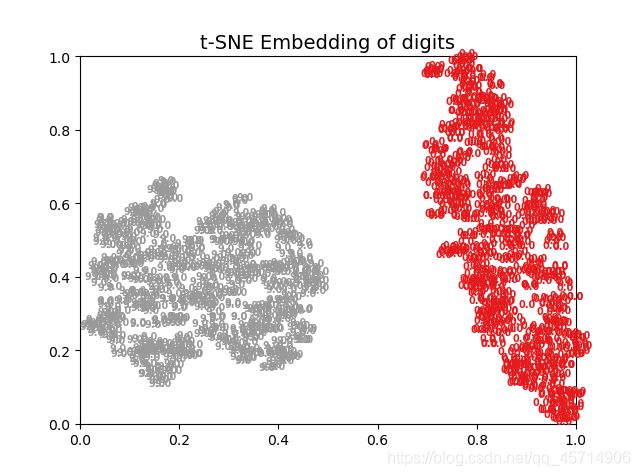
从这些图能分析出什么?毛都分析不出来,仅仅能说明两种数据本来差异性就很大。另外就是,用神经网络做二分类完全没有展现出神经网络特征提取的强大能力,因此前面写的里面曲线收敛的非常快,差不多第二批次就收敛了,这也就没什么奇怪的了。
因此增加样本数量,并研究单一个卷积层在不同训练批次下,输出数据的可视化i情况:
1、没有训练:

2、训练3次

3、训练300次

4、训练3000次

这个效果就不用再赘述了,很明显训练300次最佳。
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Wed Jul 7 11:55:08 2021
@author: 1
"""
import tensorflow as tf
from sklearn.manifold import TSNE
import numpy as np
import pandas as pd
import keras
from keras.models import Sequential
from keras.wrappers.scikit_learn import KerasClassifier
from keras.utils import np_utils,plot_model
from sklearn.model_selection import cross_val_score,train_test_split,KFold
from sklearn.preprocessing import LabelEncoder
from keras.models import model_from_json
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
import itertools
from keras.optimizers import SGD
from keras.layers import Dense,LSTM, Activation, Flatten, Convolution1D, Dropout,MaxPooling1D,BatchNormalization
from keras.models import load_model
from sklearn import preprocessing
# 载入数据
df = pd.read_csv(r'C:/Users/1/Desktop/14改.csv')
X = np.expand_dims(df.values[:, 0:1024].astype(float), axis=2)
Y = df.values[:, 1024]
# 湿度分类编码为数字
# 划分训练集,测试集
X_train, X_test, K, y = train_test_split(X, Y, test_size=0.3, random_state=0)
K=K
encoder = LabelEncoder()
Y_encoded1 = encoder.fit_transform(K)
Y_train = np_utils.to_categorical(Y_encoded1)
Y_encoded2 = encoder.fit_transform(y)
Y_test = np_utils.to_categorical(Y_encoded2)
# 定义神经网络
def baseline_model():
model = Sequential()
model.add(Convolution1D(16, 64,strides=16,padding='same', input_shape=(1024, 1),activation='relu'))#第一个卷积层
model.add(MaxPooling1D(2,strides=2,padding='same'))
model.add(BatchNormalization(axis=-1, momentum=0.99, epsilon=0.001, center=True, scale=True, beta_initializer='zeros', gamma_initializer='ones', moving_mean_initializer='zeros', moving_variance_initializer='ones', beta_regularizer=None, gamma_regularizer=None, beta_constraint=None, gamma_constraint=None))
model.add(Convolution1D(32,3,padding='same',activation='relu'))
model.add(MaxPooling1D(2,strides=2,padding='same'))
model.add(BatchNormalization(axis=-1, momentum=0.99, epsilon=0.001, center=True, scale=True, beta_initializer='zeros', gamma_initializer='ones', moving_mean_initializer='zeros', moving_variance_initializer='ones', beta_regularizer=None, gamma_regularizer=None, beta_constraint=None, gamma_constraint=None))
model.add(Convolution1D(64,3,padding='same',activation='relu'))#第二个卷积层
model.add(MaxPooling1D(2,strides=2,padding='same'))
model.add(BatchNormalization(axis=-1, momentum=0.99, epsilon=0.001, center=True, scale=True, beta_initializer='zeros', gamma_initializer='ones', moving_mean_initializer='zeros', moving_variance_initializer='ones', beta_regularizer=None, gamma_regularizer=None, beta_constraint=None, gamma_constraint=None))
model.add(Convolution1D(64, 3,padding='same',activation='relu'))#第三个卷积层
model.add(MaxPooling1D(2,strides=2,padding='same'))
model.add(BatchNormalization(axis=-1, momentum=0.99, epsilon=0.001, center=True, scale=True, beta_initializer='zeros', gamma_initializer='ones', moving_mean_initializer='zeros', moving_variance_initializer='ones', beta_regularizer=None, gamma_regularizer=None, beta_constraint=None, gamma_constraint=None))
model.add(Convolution1D(64, 3,padding='same',activation='relu'))#第四个卷积层
model.add(MaxPooling1D(2,strides=2,padding='same'))
model.add(BatchNormalization(axis=-1, momentum=0.99, epsilon=0.001, center=True, scale=True, beta_initializer='zeros', gamma_initializer='ones', moving_mean_initializer='zeros', moving_variance_initializer='ones', beta_regularizer=None, gamma_regularizer=None, beta_constraint=None, gamma_constraint=None))
model.add(Convolution1D(64,3,padding='same',activation='relu'))#第五个卷积层
model.add(MaxPooling1D(2,strides=2,padding='same'))
model.add(BatchNormalization(axis=-1, momentum=0.99, epsilon=0.001, center=True, scale=True, beta_initializer='zeros', gamma_initializer='ones', moving_mean_initializer='zeros', moving_variance_initializer='ones', beta_regularizer=None, gamma_regularizer=None, beta_constraint=None, gamma_constraint=None))
model.add(Dense(100,activation='relu'))
model.add(LSTM(64,return_sequences=True))
model.add(Dropout(0.5))
model.add(LSTM(32))
model.add(Flatten())
model.add(Dense(9, activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='adam', metrics=['accuracy'])
model.summary()
return model
# 训练分类器
estimator = KerasClassifier(build_fn=baseline_model, epochs=3000, batch_size=128, verbose=1)
history=estimator.fit(X_train, Y_train, validation_data=(X_test, Y_test))
import matplotlib.pyplot as plt
# 卷积网络可视化
def visual(model, data, num_layer=1):
layer = keras.backend.function([model.layers[0].input], [model.layers[num_layer].output])
f1 = layer([data])[0]
np.set_printoptions(threshold=np.inf)
print(f1.shape)
print(f1)
f2=f1.reshape(6034,64)
print(f2)
num = f1.shape[-1]
print(num)
plt.figure(figsize=(6, 12), dpi=150)
for i in range(num):
plt.subplot(np.ceil(np.sqrt(num)), np.ceil(np.sqrt(num)), i+1)
plt.imshow(f1[:, :, i] * 255, cmap='prism')
plt.axis('off')
plt.show()
def get_data():
#digits = datasets.load_digits(n_class=10)
digits=2
data = f2#digits.data # 图片特征
label = K#digits.target # 图片标签
n_samples=6034
n_features =64 #data.shape # 数据集的形状
return data, label, n_samples, n_features
# 对样本进行预处理并画图
def plot_embedding(data, label, title):
x_min, x_max = np.min(data, 0), np.max(data, 0)
data = (data - x_min) / (x_max - x_min) # 对数据进行归一化处理
fig = plt.figure() # 创建图形实例
ax = plt.subplot(111) # 创建子图
# 遍历所有样本
for i in range(data.shape[0]):
# 在图中为每个数据点画出标签
plt.text(data[i, 0], data[i, 1], str(label[i]), color=plt.cm.Set1(label[i] / 10),
fontdict={'weight': 'bold', 'size': 7})
plt.xticks() # 指定坐标的刻度
plt.yticks()
plt.title(title, fontsize=14)
# 返回值
return fig
data, label , n_samples, n_features = get_data() # 调用函数,获取数据集信息
print('Starting compute t-SNE Embedding...')
ts = TSNE(n_components=2, init='pca', random_state=0)
# t-SNE降维
reslut = ts.fit_transform(data)
# 调用函数,绘制图像
fig = plot_embedding(reslut, label, 't-SNE Embedding of digits')
# 显示图像
plt.show()
# 可视化卷积层
visual(estimator.model, X_train, 20)#在这里插入代码片
本来我是想拿这个代码作为创新点写个核心的,结果把把被拒说没有创新,么的办法只能放弃这个追求更高的创新了。

我发现投稿的难度并不和这个期刊的影响因子成正比,今年好几个影响因子接近1的期刊被踢出北大核心了,而且例如机械设计与研究等期刊,影响因子高于1非常好中,但是像机械强度、制造业自动化等等影响因子小于0.5的期刊,纯看命,很难中。
本次所使用的数据如下连接,永久有效:
链接:https://pan.baidu.com/s/1jmOOKXFA27I6iGlvvMBiwg
提取码:SLBY
链接:https://pan.baidu.com/s/1plW9siresvTIvlNZsDA_tw
提取码:SLBY
两个数据名字一样,但是内容不一样。