一文搞懂,redis单线程执行全貌(深入拆解分析)
文章目录
- 前言
- 一、基础知识
-
- 1.Reactor 单线程模型:
- 2.文件描述符:
- 3.套接字:
- 4.服务端连接建立:
- 二、大话单线程模型
-
- 1.建立连接:
- 2.IO轮训及就绪事件处理
- 3.命令处理及响应
- 三、总结
前言
本文参考源码版本为
redis6.2
redis 6.0 版本之前,采用的是单线程模型,即:一个线程既要负责命令读写、解析,又要负责命令执行。但是,仍然能达到极高的并发能力,其终极法宝是优秀的IO模型 + 纯内存操作 + 优秀的数据结构及算法的设计。
redis6.0 及之后的版本,引入了多线程模型,主要目的是分担主线程的压力,负责部分IO事件读写、解析的工作;但是,命令执行仍然都由主线程处理。
本文的主要目的不是对比两种线程模型的差异,而旨在梳理单线程执行的整体流程,看看为何单线程也能如此优秀?
如果你也和我一样好奇,咱们接着往下看~
一、基础知识
之前系列文章,我们已经先后介绍了 select/poll/epoll实现的IO多路复用 和 Reactor 模型,有了这些基础,我们再来看 Redis 对应的相关实现,应该就非常容易了;因此,如果你还不太了解,建议先看看。
1.Reactor 单线程模型:
我们再来复习下, 何为 IO多路复用、Reactor 单线程模型?
1)IO多路复用:

其核心思想是,先通过 select/poll/epoll 等系统调用查询监听的文件描述符是否准备就绪,这个操作可阻塞也可立即返回(具体看参数和对应规则),当其中一个或者多个文件描述符IO事件准备就绪才开始下一步,即 read 或者 write 等系统调用。
为啥叫 IO 多路复用?
在第一步中,你可能已经发现了,我们通常一次 select/poll/epoll 系统调用就可以监听所有已注册的文件描述符IO事件,这种一个线程发起并且同时监听多个IO通道的状态,就叫做 IO多路复用。
2)Reactor 单线程模型:
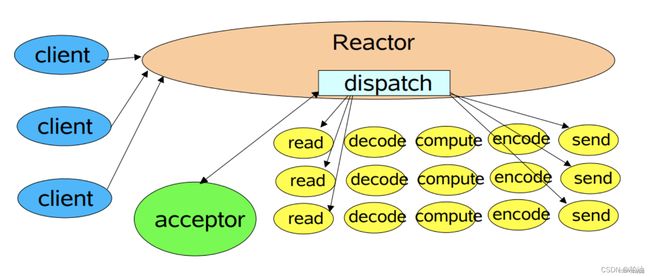
在 Reactor 单线程模型中,所有 I/O 操作(包括连接建立、数据读写、事件分发等)、业务处理,都是由一个线程完成的。单线程模型逻辑简单,缺陷也十分明显:
- 一个线程支持处理的连接数非常有限,CPU 很容易打满,性能方面有明显瓶颈;
- 当多个事件被同时触发时,只要有一个事件没有处理完,其他后面的事件就无法执行,这就会造成消息积压及请求超时;
- 线程在处理 I/O 事件时,Select 无法同时处理连接建立、事件分发等操作;
- 如果 I/O 线程一直处于满负荷状态,很可能造成服务端节点不可用。
2.文件描述符:
对于内核而言,所有打开的文件都通过文件描述符引用。文件描述符是一个非负整数。当打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。
当读、写一个文件时,使用 open 或 creat 返回的文件描述符标识该文件,将其作为参数传递给 read 或者 write。
简单来说,文件描述符就像一个凭证,有了它就可以获取到与之关联的信息;进程到内核,内核之间都可以通过文件描述符进行传递、监听、通知等各类操作。
3.套接字:
套接字是一个抽象概念,我们常说的套接字编程,也叫 Socket 编程;可见,套接字是网络编程的重要概念、是用户态与内核态数据交互的桥梁,在数据收发过程中扮演举足轻重的作用。
当我们想在服务端接收客户端连接时,我们需要通过内核提供的 API 创建套接字,然后指定一个服务器端口绑定到该套接字用于监听事件,最后通过套接字接收连接、发送应答等。
前面说了,套接字只是一个抽象概念,如果想要具体化描述,可以简单理解为,套接字是内核的一块内存空间,其保存了如监听的ip、端口以及通信进度状态等信息。
UNIX 系统一切皆文件,因此,套接字也是一种特殊的文件,对套接字的操作,也需要通过其对应的文件描述符进行。简言之,当我们想使用某个套接字时,直接使用其文件描述符即可。
4.服务端连接建立:
当客户端与服务端想要建立通信时,服务端需要做一系列的工作之后,才能等待客户端的连接请求,一般来说,服务端一般需要做以下几个工作:
- 创建套接字(如TCP套接字)(create)
- 将服务器端口绑定到套接字 (bind)
- 把套接字转换成监听套接字 (listen)
- 接收客户连接、发送应答 (accept、处理业务及应答)
- 终止连接 (close)
服务端会通过 accept() 阻塞等待客户端的新连接请求,一般情况下,会单独用一个线程无限循环的方式接收新连接,如:
while(1) {
...
// 接收新连接
fd = accept(...)
// 注册新连接的文件描述符至内核进行监听IO事件
registerFd(fd);
...
}
但是,redis 是单线程,不会通过单独的线程处理新连接请求,因此,上面的写法就有了些变化,如下:
int MAX_ACCEPTS_PER_CALL = 1000, cnt = 0
while(1) {
...
// 接收新连接
fd = accept(...)
// 注册新连接的文件描述符至内核进行监听IO事件
registerFd(fd);
if (cnt++ >= MAX_ACCEPTS_PER_CALL) {
break;
}
...
}
因为是单线程,负责新连接接收的逻辑,每一次调用,最多只能处理指定数量的新连接,然后就继续处理其他模块的逻辑。
我们知道,redis 的单线程要负责新连接建立、IO事件就绪监听、IO读写以及业务处理;各模块需要高效联动,才能保证其优秀的并发能力。看起来就像单核操作系统一样,通过时间片,同一时间只能处理一个模块的逻辑。
你可能会问,Reactor 单线程模型有这么多缺点,Redis 为什么还要采用这种模型?
redis 是纯内存操作,一般情况下, 单个操作处理速度极快;所以,即使单线程模式,设计得当,也能达到极高的性能。
二、大话单线程模型
相信通过前面的介绍,你已经了解 Reactor 单线程模型,本文将通过源码分析为何 reactor 单线程模型在 redis 中能够一枝独秀?
我们知道,reactor 模型的核心是事件驱动,当然,需要底层操作系统内核提供的IO多路复用能力。我们再来回顾这张图,一个网络请求在服务端经历了哪些阶段:
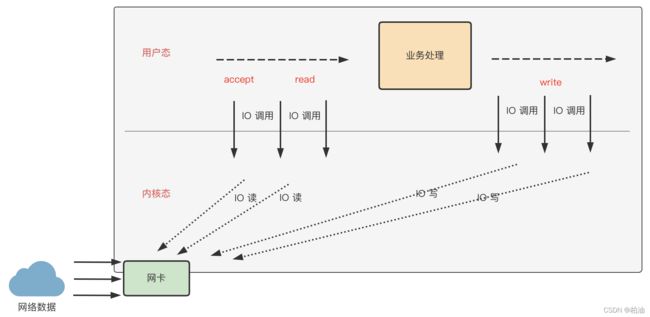
先思考以下几个问题, 看看是否心中有解:
- 问题1:如何建立连接?一次建立一个并处理,还是多个?
- 问题2:单个线程如何利用内核IO多路复用特性?
- 问题3:一个正常请求,瓶颈点在哪个阶段?
- 问题4:单线程如何支撑起成千上万高并发?
- 问题5:redis 如何选择不同操作系统提供的IO多路复用接口?
接下来,我将以单线程处理连接请求为主线,将一个请求分多个阶段进行解说,并借助于 redis 源码进行验证;
带着疑问,我们一起往下继续寻找答案~
1.建立连接:
我们知道,TCP 三次握手建立连接是由内核完成,当我们使用 accept() 方法接收连接时,只是从 TCP 连接队列中取出一个 ESTABLISHED 状态的连接。
要知道,内核为给定的监听套接字维护了两个队列,如下所示:
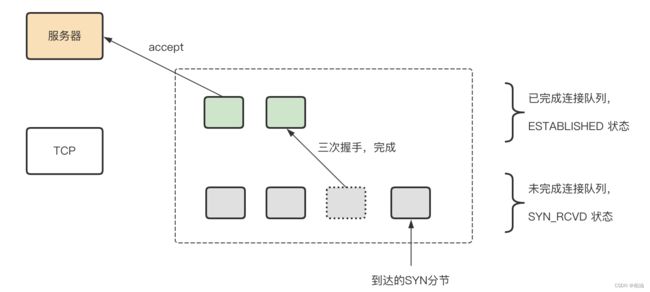
- 未完成连接队列:指还未完成 TCP 三次握手,此时处于 SYN_RCVD 状态。
- 已完成连接队列:指已经完成 TCP 三次握手的客户端,处于 ESTABLISHED 状态;这个状态可以通过 accept() 直接拿到这些连接。
所以,当我们调用 accept() 方法,其实是尝试从完成队列获取首个 ESTABLISHED 状态的连接。
前面我们提到,服务端启动时会创建套接字并绑定端口号,这个套接字我们一般用 ipfd 文件描述符引用,通过将 ipfd 注册到内核,便可以监听到新的 TCP 连接;
对于所有通过 accept() 接收的新连接,内核都会创建新的 文件描述符 fd,用以表示新的连接,然后将 fd 注册到内核进行监听;需要记住的是,进程与内核交流信息的媒介一般都是 fd。
为了更直观的表述,将通过两张图展示,如下图:

当服务端通过 accept 成功接收连接后,内核将返回新的文件描述符,如下图:
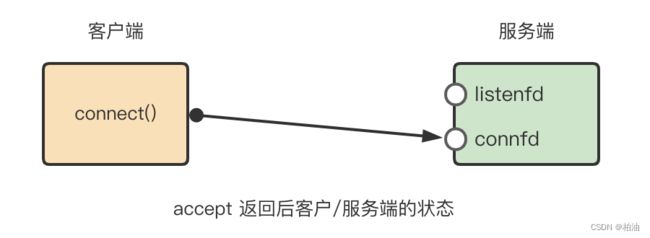
我们知道,IO多路复用是可以同时监听多个文件描述符,当这些文件描述符对应的IO事件就绪后便返回。思考,当我们还没有通过 accept() 接收任何已连接的请求时,此时将会监听哪些事件?事件如何被监听到?
其实,这个问题本质是要搞懂什么是IO事件?、内核与进程通信的媒介是什么?,上文已经详细解说了套接字与文件描述符,进程与内核是通过文件描述符进行通信;在IO多路复用模式下,文件描述符对应的套接字或者连接是否有可读、可写、可连接的IO事件,都需要进程主动查询,然后通过对应的 handler 进行处理,这也是所谓的事件驱动模式;
如果有可连接事件处理就交给专门的 acceptHandler 进行处理,如果是可读事件就交给 readHandler 进行处理,如果是可写事件就交给 writeHandler 进行处理。
再来看我们的问题,服务最开始还没有接收新连接,因此,只需要监听与服务端口绑定的 ipfd 文件描述符是否有 IO事件就绪;如果有就绪 IO事件,就交给 acceptHandler 进行处理,比如,创建新连接、注册新连接的文件描述符 fd 到内核进行监听 IO事件等。
至于如何被监听到?进程会不断的向内核查询已注册的文件描述符是否有IO事件就绪,内核对 ipfd 与 普通连接的 fd 是一视同仁的,不同点在于事件的 handler 不同而已。
好了,做了这么多铺垫了,我们一起看看,redis 是如何建立连接的~
1)将端口与TCP套接字绑定
其中 ipfd 表示 TCP 套接字文件描述符,一个端口就一个,用来监听新连接事件:
// server.c#initServer()
if (server.port != 0 &&
listenToPort(server.port,server.ipfd,&server.ipfd_count) == C_ERR)
exit(1);
2)将 ipfd 描述符注册到内核,用以监听新连接请求。
当通过内核提供的IO多路复用API查询到有新连接事件时,交给 acceptTcpHandler 接收新连接。
// server.c#initServer()
if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL) == AE_ERR)
{
serverPanic(
"Unrecoverable error creating server.ipfd file event.");
}
对于内核提供的 epoll 方法,redis 也做了一层简单封装方便自己处理。这里通过 redis 封装的 aeApiAddEvent 方法调用内核的 epoll_ctl 方法(假定是 linux 系统)。
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
aeFileProc *proc, void *clientData)
{
if (fd >= eventLoop->setsize) {
errno = ERANGE;
return AE_ERR;
}
aeFileEvent *fe = &eventLoop->events[fd];
// 将ipfd注册至内核,并且指定要处理的事件类型
if (aeApiAddEvent(eventLoop, fd, mask) == -1)
return AE_ERR;
fe->mask |= mask;
// 指定事件的处理方法
if (mask & AE_READABLE) fe->rfileProc = proc;
if (mask & AE_WRITABLE) fe->wfileProc = proc;
fe->clientData = clientData;
if (fd > eventLoop->maxfd)
eventLoop->maxfd = fd;
return AE_OK;
}
3)acceptTcpHandler 接收新连接
真正的调用 accept() 接收新连接并创建新的connection,如下:
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
// #define MAX_ACCEPTS_PER_CALL 1000
int cport, cfd, max = MAX_ACCEPTS_PER_CALL;
char cip[NET_IP_STR_LEN];
UNUSED(el);
UNUSED(mask);
UNUSED(privdata);
while(max--) {
// 通过 accept 调用,内核返回新的文件描述符
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
if (cfd == ANET_ERR) {
if (errno != EWOULDBLOCK)
serverLog(LL_WARNING,
"Accepting client connection: %s", server.neterr);
return;
}
serverLog(LL_VERBOSE,"Accepted %s:%d", cip, cport);
// 这里会将 cfd 注册到内核
acceptCommonHandler(connCreateAcceptedSocket(cfd),0,cip);
}
}
也许你会问,redis 请求整个过程都是单线程处理;倘若,新连接请求来一个,我们accept() 一个,并且继续 IO 读、命令执行、IO 写等一条龙处理完;这个过程只有单个请求,既无法利用IO多路复用特性,也无法有效利用事件驱动模型,岂不效率低下? ------ 是的。
不过,acceptTcpHandler 方法的实现给出了答案。当新连接就绪事件触发时,都会通过 acceptTcpHandler 来处理,其内部每次调用最高可循环调用 MAX_ACCEPTS_PER_CALL(1000)次 accept() 方法从内核 TCP 已连接队列获取新连接。
也就是手,一次 新连接事件触发并进行处理 时,可能会一次性创建起很多 socket connection,并将其文件描述符注册到内核进行IO事件监听。
通过 MAX_ACCEPTS_PER_CALL 的机制,既可以通过一次性调用接收多个新连接,提升IO多路复用能力;又可以避免一次性接收过多新连接(长时间阻塞),而无法及时处理,造成文件描述符资源的枯竭与浪费。
2.IO轮训及就绪事件处理
我们前面讲了新连接的接收,新连接 接收之后便是如何处理了~
1)IO事件轮训及处理:
事件处理入口方法是 server.c#main() 方法,当服务启动基本完成后,调用 ae.c#aeMain() 进行事件监听,这是一个无限循环,直到服务停止,如下:
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
aeProcessEvents(eventLoop, AE_ALL_EVENTS|
AE_CALL_BEFORE_SLEEP|
AE_CALL_AFTER_SLEEP);
}
}
其主要逻辑在 ae.c#aeProcessEvents() 中处理,如下:
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
...
// 1.调用内核多路复用API, 查询是否有IO事件就绪。当遇到超时或者部分IO事件就绪时返回
// 其中 numevents 表示就绪的IO事件数量
numevents = aeApiPoll(eventLoop, tvp);
...
// 2. 轮训这些就绪事件,挨个处理
for (j = 0; j < numevents; j++) {
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
...
// 2.1 处理读事件
if (!invert && fe->mask & mask & AE_READABLE) {
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
fe = &eventLoop->events[fd]; /* Refresh in case of resize. */
}
// 2.2 处理写事件
if (fe->mask & mask & AE_WRITABLE) {
if (!fired || fe->wfileProc != fe->rfileProc) {
fe->wfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
}
}
...
}
}
...
}
以上逻辑比较中规中矩,先查询哪些连接的IO事件准备就绪了(IO多路复用),然后依次遍历这些IO就绪的连接进行处理(事件驱动)。
值得说明的是,当我们需要处理 read 事件的时候,直接调用 rfileProc 方法;当处理 write 事件的时候,直接调用 wfileProc 方法,使用起来是不是非常方便?这得益于 aeFileEvent 结构体的封装,结构如下:
typedef struct aeFileEvent {
int mask; /* one of AE_(READABLE|WRITABLE|BARRIER) */
aeFileProc *rfileProc;
aeFileProc *wfileProc;
void *clientData;
} aeFileEvent;
rfileProc、wfileProc 都是指向函数的指针,在创建一个 aeFileEvent 事件时,便指定其中的读/写处理方法。这样一来,各个模块可以很方便的以事件为枢纽传递信息,实现了解耦、降低复杂性、提升可扩展性。
再一次回证了,redis 是以事件驱动为核心的框架。
2)谁注册了新连接的IO事件?
前面讲到IO事件的监听以及处理,我们再回过头来看看,这些新连接的IO事件如何才能被监听到?没错,将新连接的文件描述符注册到内核才能进行IO事件监听,当然,这仍然是 acceptTcpHandler 来完成。
acceptTcpHandler 负责从内核TCP就绪队列接收新连接并进一步包装处理,其中一个操作会将新连接的文件描述符注册到内核进行监听,我们重点来看看它是如何做的:
// networking.c#acceptTcpHandler()
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
...
while(max--) {
// 通过 accept 调用,内核返回新的文件描述符
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
...
acceptCommonHandler(connCreateAcceptedSocket(cfd),0,cip);
}
}
内部依赖通用的处理器 acceptCommonHandler:
// networking.c#acceptCommonHandler()
#define MAX_ACCEPTS_PER_CALL 1000
static void acceptCommonHandler(connection *conn, int flags, char *ip) {
client *c;
...
/* 创建 client 对象 */
if ((c = createClient(conn)) == NULL) {
...
}
...
}
其内部也是依赖 createClient 操作,创建 client 对象的时候会做一些初始化操作,比如指定 用哪个方法来读取数据、向内核注册文件描述符监听等等。
// networking.c#createClient()
client *createClient(connection *conn) {
client *c = zmalloc(sizeof(client));
if (conn) {
connNonBlock(conn);
connEnableTcpNoDelay(conn);
if (server.tcpkeepalive)
connKeepAlive(conn,server.tcpkeepalive);
// 向内核注册新连接的文件描述符
// 并指定 readQueryFromClient 为处理方法,负责读取数据并执行。
connSetReadHandler(conn, readQueryFromClient);
connSetPrivateData(conn, c);
}
...
}
readQueryFromClient 此方法非常重要,是数据读取以及处理的开端,咱们放在后面再聊!
当定位到这一步时,一切都已明了。方法 connSocketSetReadHandler 中会向内核注册新连接的文件描述符并指定了对读事件进行监听,同时也指定处理方法 read_handler = func,即 readQueryFromClient 方法。
// connection.h#connSetReadHandler()
// 注册 read handler,当有事件就绪时,通过 func 进行处理
static inline int connSetReadHandler(connection *conn, ConnectionCallbackFunc func) {
return conn->type->set_read_handler(conn, func);
}
// connction.c#connSocketSetReadHandler()
static int connSocketSetReadHandler(connection *conn, ConnectionCallbackFunc func) {
if (func == conn->read_handler) return C_OK;
conn->read_handler = func;
if (!conn->read_handler)
aeDeleteFileEvent(server.el,conn->fd,AE_READABLE);
else
// 注册读事件
if (aeCreateFileEvent(server.el,conn->fd,
AE_READABLE,conn->type->ae_handler,conn) == AE_ERR) return C_ERR;
return C_OK;
}
以上是读事件监听的注册过程,写事件的注册也是类似,感兴趣的读者可以尝试看看,不再赘述。
3.命令处理及响应
前面做的一切,都是为我们的最终目标:执行命令并响应结果 而存在。
1)命令执行:
将从 readQueryFromClient 开始:
// networking.c#readQueryFromClient()
void readQueryFromClient(connection *conn) {
client *c = connGetPrivateData(conn);
...
// 数据读取,存放在 querybuf 缓存中
nread = connRead(c->conn, c->querybuf+qblen, readlen);
...
// 通过此方法真正进入命令处理入口 processCommand
processInputBuffer(c);
}
命令执行入口 processCommand 及 命令执行 call 方法:
// server.c#processCommand()
int processCommand(client *c) {
...
// 一系列参数、命令、权限校验操作
/* 执行命令 */
if (c->flags & CLIENT_MULTI && // 事物命令(可多条命令组合)
c->cmd->proc != execCommand && c->cmd->proc != discardCommand &&
c->cmd->proc != multiCommand && c->cmd->proc != watchCommand &&
c->cmd->proc != resetCommand)
{
queueMultiCommand(c);
addReply(c,shared.queued);
} else {
// 真正执行命令的操作
call(c,CMD_CALL_FULL);
c->woff = server.master_repl_offset;
if (listLength(server.ready_keys))
handleClientsBlockedOnKeys();
}
return C_OK;
}
// server.c#call()
void call(client *c, int flags) {
...
// 命令执行
c->cmd->proc(c);
...
}
以上便是命令执行的主逻辑。
2)响应:
我们知道,redis 中的所有命令都是以独立的 xxxCommand 进行封装,可以在 server.c 中看到所有枚举的 redisCommand 命令。
我们任找一个命令查看,可以发现,在命令处理完之后,都会有 addReplyXxx() 这类方法调用;其实,这便是在向客户端响应结果。
这些方法将返回结果发送给客户端的吗?其实不是。关于客户端结构体 client,其中有两个关键字段 reply 和 buf,分别表示输出链表与输出缓冲区,而函数 addReply 会直接或者间接地将返回结果暂时缓存在 reply 或者 buf 字段:
来看看 addReply() 方法:
void addReply(client *c, robj *obj) {
if (prepareClientToWrite(c) != C_OK) return;
if (sdsEncodedObject(obj)) {
if (_addReplyToBuffer(c,obj->ptr,sdslen(obj->ptr)) != C_OK)
_addReplyProtoToList(c,obj->ptr,sdslen(obj->ptr));
} else if (obj->encoding == OBJ_ENCODING_INT) {
char buf[32];
size_t len = ll2string(buf,sizeof(buf),(long)obj->ptr);
if (_addReplyToBuffer(c,buf,len) != C_OK)
_addReplyProtoToList(c,buf,len);
} else {
serverPanic("Wrong obj->encoding in addReply()");
}
}
其中, _addReplyToBuffer 表示输出到缓冲区,_addReplyProtoToList 表示输出到链表;值得注意的是,两者优先级之分,优先写到缓冲区,如果失败,则输出到链表。
什么时候将这些数据真正发送给客户端呢?
在主事件循环(aeMain)中,方法 beforesleep 在每次事件循环阻塞等待文件事件之前执行,主要执行一些不是很费时的操作,比如过期键删除操作,向客户端返回命令回复等。
也就是在这个时候,会将缓冲区的数据发送到客户端,回复客户端的具体代码逻辑:
// networking.c#handleClientsWithPendingWritesUsingThreads()
int handleClientsWithPendingWritesUsingThreads(void) {
...
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 向客户端发送数据
writeToClient(c,0);
}
...
}
三、总结
本文的主线为:redis 单线程处理流程,并结合源码分阶段剖析其实现逻辑。
现在,我们尝试回答上文提的几个问题:
问题1):如何建立连接?一次建立一个并处理,还是多个?
redis 服务启动时,会向内核注册 ipfd(与端口绑定的套接字对应的文件描述符)用来监听新连接事件;当然,因为是单线处理,监听新连接与监听已连接的IO事件将会在一个主循环事件中处理;
新连接事件触发时将由 acceptTcpHandler 进行处理,一次性可以从内核 TCP 队列接收最多 1000 个新连接,然后将这些新连接对应的文件描述符注册到内核进行IO事件的监听。
问题2):单个线程如何利用内核IO多路复用特性?
在问题1,我们已经提到,acceptTcpHandler 一次调用可以从内核 TCP 就绪队列中接收最多1000个新连接,然后将这些新连接对应的文件描述符注册到内核进行监听。
可见,单线程我们仍然可以同时监听这1000个连接的IO事件,这便是IO多路复用。
问题3):一个正常请求,瓶颈点在哪个阶段?
我们这样来看,一般影响一个请求的有两部分:IO模型和命令执行:
- 在 IO 方面,利用IO多路复用能支持较高的并发度,能应付绝大部分场景;
- 命令执行方面,纯内存操作,只要采用的数据结构、算法以及数据量合适,完全能撑起IO层放进来的量。
简言之,内存操作可以碾压IO操作。
综上,redis 的性能瓶颈目前在于 IO 层面,因此,要想通过多线程来提升并发处理能力,也应在 IO 层面考虑。redis6.0 引入的多线程机制便是这样处理的。
但是,当我们遇到 keys 这种极耗性能的命令时,请求可能将会出现阻塞。从这个角度看,瓶颈点在于命令执行。
你会说,用多线程来处理命令执行不就可以了?对 redis 这种组件来说可能还真不行,并发太高、又必须保证线程安全,所以,多线程处理命令执行的方案行不通。
别忘了,我们主要的目的是考虑如何分担主线程的压力,将IO事件的读/写用多线程来处理,进而分担主线程的压力,至于功能层面,需要作出一些让步。
因此,redis6.0的多线程中,命令执行仍然是单线程处理,keys 仍然有阻塞的风险,因尽量避免。
问题4):单线程如何支撑起成千上万高并发?
其实在问题3基本已经回答了,redis 单线程支撑起成千上万的高并发,离不开其纯内存操作。
问题5):redis 如何选择不同操作系统提供的IO多路复用接口?
这个问题其实已经不只是 redis 要处理了,只要使用系统内核提供的IO多路复用API,都需要考虑系统的支持能力了。比如 windons 支持 select、linux 支持 epoll、mac OS 支持 kqueue等等。
redis 事先定义好几套处理方式,最后根据系统类型选择一套即可,在 ae.c 的定义中有:
/* Include the best multiplexing layer supported by this system.
* The following should be ordered by performances, descending. */
#ifdef HAVE_EVPORT
#include "ae_evport.c" // Solaris
#else
#ifdef HAVE_EPOLL
#include "ae_epoll.c" // Linux
#else
#ifdef HAVE_KQUEUE
#include "ae_kqueue.c" // MacOS
#else
#include "ae_select.c" // Windows
#endif
#endif
#endif
相关文档:
- 高性能网络编程之 Reactor 网络模型
- Redis事件驱动框架(上):何时使用select、poll、epoll?
- 一文搞懂,4种主要的 I/O 模型