Pytorch的学习——CNN
CNN
在pytorch中CNN(卷积神经网络)由 torch.nn中的Conv1d()、Conv2d()、Conv3d()三个函数进行数据的一维、二维、三维卷积操作。主要参数有in_channels, out_channels,kernel_size。
in_channels:代表输入数据的个数
比如[[1,1],[2,2],[3,3],[4,4],[5,5]]这可以当作一维数据也可以当作二维数据
如果当作一维数据,每个数据又由一个[]组成,在每个[]中有2个数据,所以in_channels就等于2
如果当作二维数据,每个位置只有一个数据,所以in_channels就等于1
out_channels:代表输出的层数,可随便填
比如[1,2,3,4,5],如果out_channels=5,那么卷积之后就会变成[[…],[…],[…],[…],[…]]
每个[…]都含有5个数据
kernel_size:代表选择框的长度,一般选取奇数
比如kernel_size=5,对一维数据每5个数据进行一次卷积操作,对二维数据就会生成边长为5的正方形矩形框进行卷积操作,同理三维数据是边长为5的正方体
下面例子是对图像进行卷积操作
如下图kernel_size就为k,一维数据可以想象成在直线上
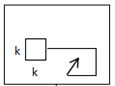 二维数据
二维数据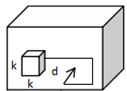 三维数据
三维数据
torch.nn.Conv2d(
in_channels=3, # 图像每个像素点由R,G,B三个数组成,当然有的就一个数据,这里具体看图像的每个像素点的组成数据的个数
out_channels=16, # 输出16层
kernel_size=5, # 框的边长
)
正常数据通过卷积后,数据会缩小如4x4的图片在3x3的矩形框下卷积操作后就会变成2x2,这样会漏掉图像的边缘信息。所以可以通过在数据的外围包裹数据的方式来解决该问题,pytorch提供了padding参数来保持图像卷积后的大小不会改变。
而padding=kernel_size/2-1,如下列子
torch.nn.Conv2d(
in_channels=3,
out_channels=16,
kernel_size=5,
padding=2,
)
卷积后就是池化层,作用是缩小图像,由MaxPool1d()、MaxPool2d()、MaxPool3d()函数提供,与Conv1d()、Conv2d()、Conv3d()一一对应
小编这里用MaxPool2d()做例子,这里一般只需要参数kernel_size就可以了,kernel_size意义还是矩形框的边长。因为在源码中stride即步长,如果不填的话会默认等于kernel_size
torch.nn.MaxPool2d(kernel_size=2)
这里一般都填2,因为比较易于计算池化后的图像的长和宽,就是输入图像的长宽除2
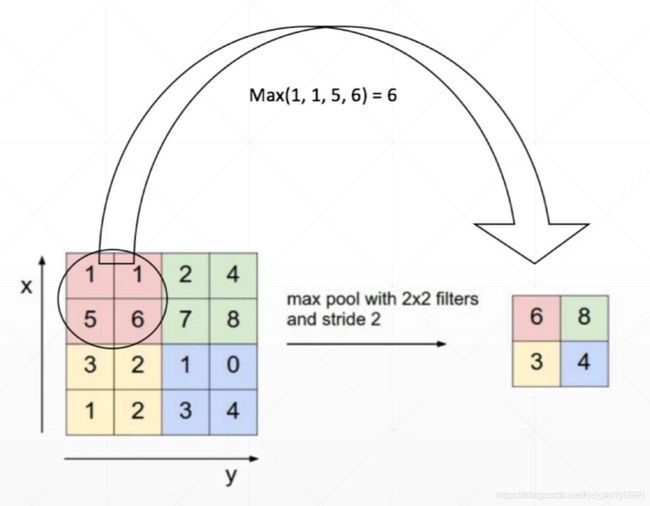
这里通过手写数字的一个小例子来进一步了解pytorch中的cnn
import torch
import torch.utils.data as Data
import torch.nn as nn
import torchvision
# import matplotlib.pyplot as plt
from torch.nn import functional as F
EPOCH = 1 # 批处理的次数
BATCH_SIZE = 50 # 批处理时,每次提取的数据个数,这里是图片的个数
LR = 0.001 # 学习效率
DOWNLOAD_MNIST = False # 有没有下载mnist手写数字数据,如果没有改成True
# 加载数据
train_data = torchvision.datasets.MNIST(
root='./mnist', # 数据存放路径
train=True,
transform=torchvision.transforms.ToTensor(), # 转换数据格式成torch
download=DOWNLOAD_MNIST
)
print(train_data.data.size()) # (60000, 28, 28)
print(train_data.targets.size()) # (60000)
# shuffle=True代表乱序提取图片shuffle=False代表按顺序提取图片,
# 这里还有一个参数num_workers代表线程个数,默认是0,Window上Pytorch并不支持多线程训练,Linux支持,可以加快训练速度
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True,num_workers=0)
# 加载测试数据
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
# 改变数据格式,这里除255是为了把数据放入0-1区间之内
test_x = torch.unsqueeze(test_data.data, dim=1).type(torch.FloatTensor)[:2000]/255.
test_y = test_data.targets[:2000]
# 搭建神经网络
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 输入图片是(28, 28, 1)
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=1,
out_channels=16,
kernel_size=5,
stride=1,
padding=2,
),
# 卷积后(28, 28, 16)
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
# 池化后(14, 14, 16)
)
# 输入图片是(14, 14, 16)
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 5, 1, 2),
# 卷积后(14, 14, 32)
nn.ReLU(),
nn.MaxPool2d(2),
# 池化后(7, 7, 32)
)
# 所以最后输出为(7, 7, 32)
self.out = nn.Linear(32*7*7, 10)# 全连接层32*7*7就是最后输的数据三个维度的乘积,10代表分类的个数,因为基础数字一共10个
# 调用神经网络
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
output = self.out(x)
return output
# 初始化
cnn = CNN()
# 优化器
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR)
# 选择计算误差的方法
loss_func = nn.CrossEntropyLoss()
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader):
output = cnn(b_x)
# 计算误差
loss = loss_func(output, b_y)
# 梯度归零
optimizer.zero_grad()
# 误差反向传递
loss.backward()
# 更新网络参数
optimizer.step()
if step % 50 == 0:
# 检验准确率
test_output = cnn(test_x)
pred_y = torch.max(test_output, 1)[1].numpy()
accuracy = float((pred_y == test_y.data.numpy()).astype(int).sum()) / float(test_y.size(0))
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)
test_output = cnn(test_x[:20])
pred_y = torch.max(test_output, 1)[1].detach().numpy()
print(pred_y, 'prediction number')
print(test_y[:20].numpy(), 'real number')
训练过程
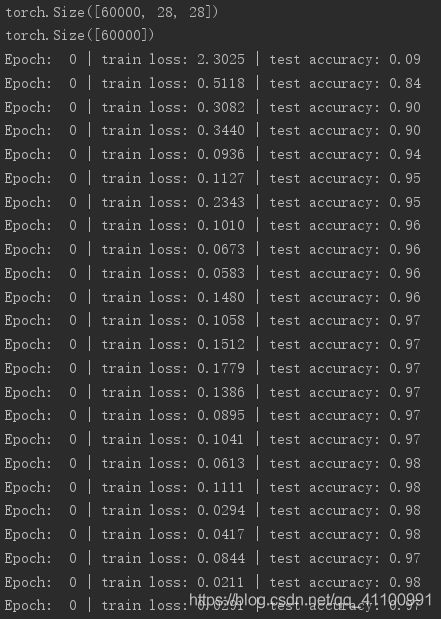
测试结果
