比较pytorch与keras训练模型的不同并且在Pytorch中使用一维卷积神经网络对一维连续数据分类
卷积神经网络对于周期性的一维信号分类效果是比较好的,本人做电机故障检测,需要对不同故障的轴承振动信号进行分类。
之前都是用keras搭建神经网络,确实很方便,使用fit()函数训练模型确实很省事。但是fit()函数不太灵活,如果想对网络中间层输出特征操作的话好像是不行的(博主也是初学者,如果有大佬知道keras或者tensorflow如何对中间输出特征操作的话还望不吝赐教)。所有,最近看了一下pytorch,并用pytorch搭建了一维卷积神经网络对凯斯西储大学数据集进行分类。在过程中也踩了一些雷,在这边也分享出来。
我选择的数据为空载工况下,外圈故障、内圈故障、滚动体故障三种故障类型,每种故障类型有三个故障深度,所以模型要处理一个9分类任务。下图是我用的数据集。
首先说我踩得第一个坑
在keras中通道数排在最后,比如通过数据预处理程序之后我得到的训练数据和标签形状为(5400,1024),(5400,9),训练数据中5400是样本数,1024是单个样本长度,训练标签中的9是九分类的独热编码。
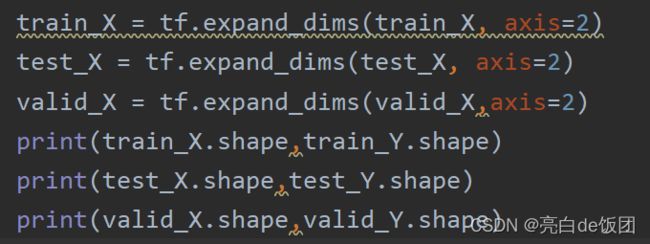
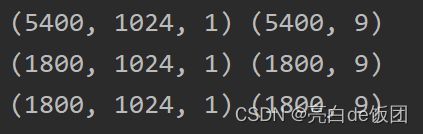
在keras中需要插入一个通道维度,并且通道维度在最后,也就是我上图这个样子。但是在pytorch中,通道数所在的位置在批维度之后。比如(32,1,1024)为(一批样本数,通道数,数据长度)。所以要正确插入通道维度。
此外,在pytorch中输入数据要转化成张量形式,在keras中就不需要这个操作,fit会自动处理。方法如下:
class MyDataset(Dataset):
def __init__(self, X, Y):
self.data_x = torch.FloatTensor(X, ).unsqueeze(dim=1)
self.data_y = torch.FloatTensor(Y, )
self.len = X.shape[0]
pass
def __getitem__(self, index):
return self.data_x[index],self.data_y[index]
def __len__(self):
return self.len
pass
batch_size = 32
train_data = MyDataset(X=train_X, Y=train_Y)
train_dataloader = DataLoader(train_data,batch_size=batch_size,shuffle=True,drop_last=True,num_workers=0)其中注意DataLoader()这个函数中的shuffle=,一定要打成True,就是要将数据集打乱,否则可能会造成训练的时候loss不降,我当时跑的时候输出loss从开始就不变,但是我debug的时候loss是变化的,很诡异。个人认为原因就是输入数据没打乱,那在一开始模型学习的都是同一类型数据,当模型适应这些数据之后他的参数自然不会再发生变化,那loss肯定也就不会下降。
第二个就是loss曲线和acc曲线,我看了一些网上给的方法,个人觉得不太直观,对初学者而言肯定一目了然最好。下面是我的代码
# 训练模型
Loss_list = []
correct_list = []
for epoch in range(100):
correct = 0
running_loss = 0
for i,data in enumerate(train_dataloader,0):
train_x,train_y = data
train_x = train_x.unsqueeze(dim=1)
outputs = Net(train_x)
loss = criterion_loss(outputs,train_y)
opt.zero_grad()
loss.backward()
opt.step()
predicted = torch.max(outputs.data, 1)[1]
y = torch.max(train_y.data, 1)[1]
running_loss += loss.item()
correct += (predicted == y).sum()
Loss_list.append(running_loss / train_X.shape[0])
correct_list.append(correct / train_X.shape[0])
x1 = range(0, 100)
y1 = Loss_list
plt.subplot(2, 1, 1)
plt.plot(x1, y1,'.-')
plt.ylabel('train loss')
plt.xlabel('train loss vs. epoches')
plt.show()
x2 = range(0, 100)
y2 = correct_list
plt.subplot(2, 1, 2)
plt.plot(x2, y2,'.-')
plt.ylabel('train acc')
plt.xlabel('train acc vs. epoches')
plt.show()每训练一个epoch记录一次正确率和损失,这边说一下批训练之后返回的loss是这一批数据的平均loss,不是最后一个数据的loss。
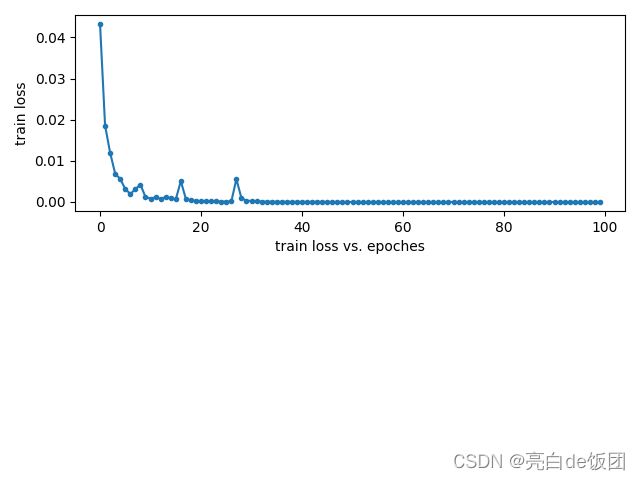
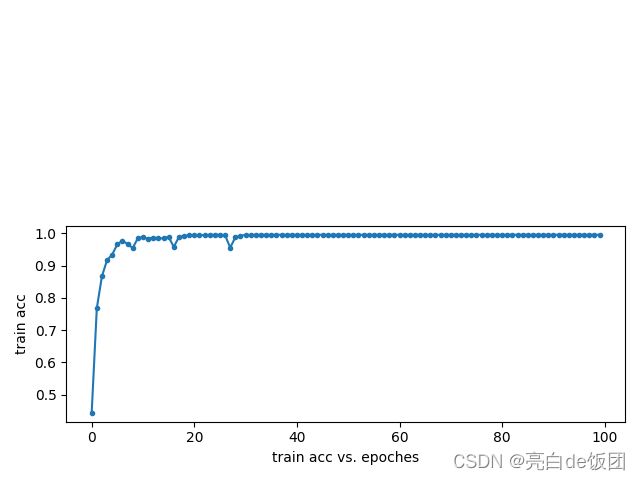
训练过程如上图所示,训练结果如下图所示
再说一下keras和pytorch搭建模型的不同,keras直接import之后往容器里写就行了,但是torch需要自己写一个类,写法基本固定。此外,torch的前向传播和反向传播都是自己写的,所以它要比keras灵活,你可以自己决定返回哪些值。
总的代码直接放在下面:
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optimizer
import dataprocess
import torch
from torch.utils.data import Dataset,DataLoader
from matplotlib import pyplot as plt
path = r'G:\桌面\凯斯西储大学轴承故障数据\12K驱动端承载故障数据\test_0'
train_X, train_Y, valid_X,valid_Y,test_X, test_Y=dataprocess.prepro(d_path=path,
length=1024,
number=1000,
normal=True,
rate=[0.6,0.2,0.2],
enc=True,
enc_step=28)
class MyModel(nn.Module):
def __init__(self):
super(MyModel,self).__init__()
self.conv1 = nn.Conv1d(in_channels=1,out_channels=4,kernel_size=16,stride=1,padding='same')
self.conv2 = nn.Conv1d(in_channels=4, out_channels=4, kernel_size=16, stride=1, padding='same')
self.conv3 = nn.Conv1d(in_channels=4, out_channels=4, kernel_size=16, stride=1, padding='same')
self.conv4 = nn.Conv1d(in_channels=4, out_channels=4, kernel_size=16, stride=1, padding='same')
self.conv5 = nn.Conv1d(in_channels=4, out_channels=4, kernel_size=16, stride=1, padding='same')
self.pool = nn.MaxPool1d(2,2)
self.fc1 = nn.Linear(in_features=512,out_features=64)
self.fc2 = nn.Linear(in_features=64, out_features=9)
# self.flatten = nn.Flatten()
def forward(self,x):
x = self.pool(F.relu(self.conv1(x)))
# print(x.shape)
x = self.pool(F.relu(self.conv2(x)))
# print(x.shape)
x = self.pool(F.relu(self.conv3(x)))
# print(x.shape)
# x = self.pool(F.relu(self.conv4(x)))
# x = self.pool(F.relu(self.conv5(x)))
x = x.flatten(start_dim=1)
# print(x.shape)
# x = self.flatten(x)
x = F.relu(self.fc1(x))
# print(x.shape)
x = self.fc2(x)
return x
class MyDataset(Dataset):
def __init__(self, X, Y):
self.data_x = torch.FloatTensor(X, )
self.data_y = torch.FloatTensor(Y, )
self.len = X.shape[0]
pass
def __getitem__(self, index):
return self.data_x[index],self.data_y[index]
def __len__(self):
return self.len
pass
batch_size = 32
train_data = MyDataset(X=train_X, Y=train_Y)
train_dataloader = DataLoader(train_data,batch_size=batch_size,shuffle=True,drop_last=True,num_workers=0)
Net = MyModel()
print(Net)
# 定义损失函数和优化器
criterion_loss = nn.CrossEntropyLoss()
opt = optimizer.Adam(Net.parameters(), lr=0.001)
# 训练模型
Loss_list = []
correct_list = []
for epoch in range(100):
correct = 0
running_loss = 0
for i,data in enumerate(train_dataloader,0):
train_x,train_y = data
train_x = train_x.unsqueeze(dim=1)
outputs = Net(train_x)
loss = criterion_loss(outputs,train_y)
opt.zero_grad()
loss.backward()
opt.step()
predicted = torch.max(outputs.data, 1)[1]
y = torch.max(train_y.data, 1)[1]
running_loss += loss.item()
correct += (predicted == y).sum()
Loss_list.append(running_loss / train_X.shape[0])
correct_list.append(correct / train_X.shape[0])
x1 = range(0, 100)
y1 = Loss_list
plt.subplot(2, 1, 1)
plt.plot(x1, y1,'.-')
plt.ylabel('train loss')
plt.xlabel('train loss vs. epoches')
plt.show()
x2 = range(0, 100)
y2 = correct_list
plt.subplot(2, 1, 2)
plt.plot(x2, y2,'.-')
plt.ylabel('train acc')
plt.xlabel('train acc vs. epoches')
plt.show()
最后再说明一下,模型结构是我随便搭的,有更好的卷积神经网络结构。
我也刚开始学torch,有问题欢迎指正。