Pytorch项目(1)| 预测泰坦尼克号船上的生存乘客
前言
为了使得自己的知识成为体系,首先明确一点,知识不需要去记忆,有个印象即可,不记得就去百度,重要的是锻炼思维以及编程能力(拿到问题如何解决问题的能力。)
那么,从这个时间点开始,便开始首先搞定基础,python基础已经有了,接着就是深度学习框架pytorch的基础,所有的基础我们都不去纠结它里面有什么东西,找一个问题,去解决,干就完事了,重要的是训练解决问题的能力。好了,废话,就这么多了。
一般来说,个人认为,深度学习的”hello world“就是泰坦尼克号了,于是我们入门的第一个项目就是泰坦尼克船上的生存乘客的预测了。
1.深度学习的步骤
一般来说,深度学习的步骤主要有以下四步:
1.准备和分析数据;
2.搭建网络模型;
3.训练模型;
4.使用和评估模型。
2.案例描述
搭建一个多层的全连接神经网络,通过对泰坦尼克号船上的乘客的数据进行拟合,预测乘客是否能够在灾难中存活下来。
3.准备和分析数据
3.1 观察和分析数据
首先,我们观察一下数据每一列的特征分别所代表的含义
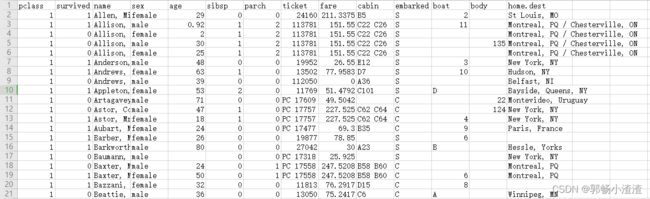
该数据表总共有1309行,14列,其中每一类表示的特征意义如下:
pclass:乘客舱位的等级(1,2,3)
survived:是否获救(1,获救,0,没有获救)
name:姓名
sex:性别
age:年龄
sibsp:兄弟姐妹/配偶
parch:父母/孩子
ticket:票价
cabin:船舱号码
embarked:登船港口
boat:救生艇
body:身份证号
home.dest:家庭住址
3.2 样本的特征分析--离散数据与连续数据
样本的数据特征主要可以分为两类:离散数据特征和连续数据特征。
1.离散数据特征
类似于分类任务中的标签数据,数据之间没有连续性。
在对离散数据做特征变换的时候,主要分为两类处理:
(1)具有固定类别:直接按照类别数目进行变换;
(2)没有固定类别:比如姓名这种,可以使用hash算法,或者词向量技术,one-hot编码等。
2.连续数据特征
类似于回归任务中的标签数据,例如年龄,时间等,在做特征变换时,经常做对数运算或者归一化处理,使其具有统一的值域。
3.离散数据与连续数据之间相互转化
在实际应用中,需要根据数据的特性选择合适的转化方式,有时还需要实现连续数据与离散数据之间的相互转化。
例如,在对一个值域跨度很大(0.1~10000)的特征属性记性数据预处理的时候,可以有以下3种方法。
(1)将其按照最大值、最小值进行归一化处理。
(2)对其使用对数运算。
(3)按照其分布情况将其分为几类,做离散化处理。
具体选择哪一种方法还要看数据的分布情况。假设数据中有90%的样本在0.1-1之间,只有10%的样本在1000-10000之间,那么使用第一种和第二种明显不合理,因为这两种方法会将90%的样本与10%的样本分开,并不能很好地体现出这90%的样本的内部分布情况。
而使用第三种方法,可以按照样本在不同区间的分布数量对样本进行分类,让样本内部的分布特征更好的表达出来。
(上面的描述我需要找到相关的案例才能理解,不然就像抄了一遍意义不大!!!)
3.3 处理样本中的离散数据和nan值
本案例中的样本的离散数据处理比较简单,具体的操作如下:
(1)将离散数据转换为one-hot编码;
(2)对数据中的nan值进行过滤填充;
(3)剔除无用的数据列。
1.剔除无用的数据列
首先根据经验和常识分析,是否获救与乘客的名字(name)、票号(ticket)、船舱号码(cabin)等信息无关,因此直接在数据中删除。操作代码如下:
# 处理数据
# 1.提出无用的数据
titanic_data = titanic_data.drop(["name", 'ticket', 'cabin', 'boat', 'body', 'home.dest', 'pclass'], axis=1) # axis=1 按列删除
print(titanic_data.columns) # 观察数据的列属性特征2.将离散数据转换为one-hot编码
使用pandas库中的get_dummies()函数可以将离散的数据转成one-hot编码。具体代码如下。
# 用哑变量将指定字段转成one-hot
# 虚拟变量(dummy variable)也叫哑变量,翻译不同而已。因为dummy的含义有假的、虚拟的、哑的等各种含义,所以国内翻译也不一样。但是他们俩是一回事。
# 这里应该是指我们使用的这个函数
titanic_data = pd.concat([titanic_data,
pd.get_dummies(titanic_data["sex"]),
pd.get_dummies(titanic_data['embarked'], prefix="embarked"), # prefix:指定前缀
pd.get_dummies(titanic_data["pclass"], prefix="class")], axis=1)
# titanic_data.drop(["sex",'embarked','pclass'],axis=1) # 同时删除掉原来的列表属性
print(titanic_data.columns) # 查看当前的列属性
print(titanic_data["sex"]) # 查看当前的sex值
print(titanic_data['female']) # 查看female对应的值
titanic_data = titanic_data.drop(["sex",'embarked','pclass'],axis=1) # 同时删除掉原来的列表属性输出为:
Index(['pclass', 'survived', 'sex', 'age', 'sibsp', 'parch', 'fare',
'embarked', 'female', 'male', 'embarked_C', 'embarked_Q', 'embarked_S',
'class_1', 'class_2', 'class_3'],
dtype='object')
0 female
1 male
2 female
3 male
4 female
...
1304 female
1305 female
1306 male
1307 male
1308 male
Name: sex, Length: 1309, dtype: object
0 1
1 0
2 1
3 0
4 1
..
1304 1
1305 1
1306 0
1307 0
1308 0
Name: female, Length: 1309, dtype: uint8在输出的结果中,female列之后都是one-hot转码后生成的新列,其中female为sex列中的离散值。也就是说在sex中,列中为female的值,在female中值为1,其他为0。同样在male中的,sex为male的,值也为1,其他为0.
3.对nan值进行过滤填充
样本中并不是每一个属性都有数据的。没有数据的部分再pandas中会被解析成nan值。因为模型无法对无效值nan进行处理,所以需要对nan值进行过滤并填充。
在本例中,只对两个连续属性的数据列进行nan值处理,即age和fare属性。具体代码如下:
# 3.对nan值进行处理
titanic_data["age"] = titanic_data["age"].fillna(titanic_data["age"].mean())
titanic_data["fare"] = titanic_data["fare"].fillna(titanic_data["fare"].mean())在以上代码中,调用了fillna()函数对nan值进行了过滤,并用该数据列中的平均值进行填充。
3.4 分离样本和标签并制作为数据集
将survived列从数据列表中单独提取出来作为标签。将数据列中剩下的数据作为输入样本。
将样本和标签按照30%和70%比例分成测试集和训练数据集。具体代码如下:
# 4.分离数据样本
labels = titanic_data["survived"].to_numpy()
print(labels)
titanic_data = titanic_data.drop(["survived"],axis=1)
data = titanic_data.to_numpy()
print(data)
# 样本的属性名称
feature_names = list(titanic_data.columns)
print(feature_names)
# 将样本分为训练和测试两部分
np.random.seed(10) # 设置随机种子,保证每次运行随机出来的样本一致,从而方便他人复现实验
train_indices = np.random.choice(len(labels),int(0.7*len(labels)),replace=False)
#numpy.random.choice(a, size=None, replace=True, p=None)
#从a(只要是ndarray都可以,但必须是一维的)中随机抽取数字,并组成指定大小(size)的数组
#replace:True表示可以取相同数字,False表示不可以取相同数字
#数组p:与数组a相对应,表示取数组a中每个元素的概率,默认为选取每个元素的概率相同。
print(len(train_indices))
test_indices = list(set(range(len(labels)))-set(train_indices))
print(len(test_indices))
train_features = data[train_indices]
train_labels = labels[train_indices]
test_features = data[test_indices]
test_labels = labels[test_indices]
print(test_features)
4.搭建网络模型
紧接着,我们搭建一个3层全连接网络的模型,每个网络层使用Mish作为激活函数。该网络模型使用交叉熵的损失的计算方法。具体代码如下:
# 5.搭建网络模型
# 定义Mish激活函数
class Mish(nn.Module):
def __init__(self):
super().__init__()
def forward(self,x):
x = x * (torch.tanh(F.softplus(x)))
return x
torch.manual_seed(0) # 设置随机种子,是的每次初始化的权重相同,方便他人复现结果
class ThreelinearModel(nn.Module):
def __init__(self):
super(ThreelinearModel, self).__init__()
self.linear1 = nn.Linear(12,12)
self.mish1 = Mish()
self.linear2 = nn.Linear(12,8)
self.mish2 = Mish()
self.linear3 = nn.Linear(8,2)
self.softmax = nn.Softmax(dim=1)
self.criterion = nn.CrossEntropyLoss()
def forward(self,x):
x = self.linear1(x)
x = self.mish1(x)
x = self.linear2(x)
x = self.mish2(x)
x = self.linear3(x)
return self.softmax(x)
def getloss(self,x,y):
y_pre = self.forward(x)
loss = self.criterion(y_pre,y)
return loss5.训练模型
这里我们实现一个简单的训练过程,代码如下:
# 6.训练模型
if __name__ == '__main__':
net = ThreelinearModel() # 实例化模型对象
num_epochs = 1000 # 设置训练次数
optimizer = torch.optim.Adam(net.parameters(), lr=0.001) # 定义优化器
# 将输入的样本标签转化为张量
input_tensor = torch.from_numpy(train_features).type(torch.FloatTensor)
label_tensor = torch.from_numpy(train_labels)
losses = [] # 定义列表,用于接收每一步的损失值
for epoch in range(num_epochs):
loss = net.getloss(input_tensor, label_tensor)
losses.append(loss.item())
optimizer.zero_grad() # 清空之前的梯度值
loss.backward() # 反向传播损失值
optimizer.step() # 更新参数
if epoch % 20 == 0:
print("epoch{}/{} => Loss:{:.2f}".format(epoch+1, num_epochs,loss.item()))
os.makedirs("models", exist_ok=True) # 创建文件夹
torch.save(net.state_dict(), "models/titanic_model.pt") # 保存模型
# 显示loss值的可视化结果
plot_losses(losses)
# 输出训练的性能结果
out_probs = net(input_tensor).detach().numpy()
out_classes = np.argmax(out_probs, axis=1)
print("train Accuracy:", sum(out_classes == train_labels) / len(train_labels))显示训练的可视化结果如下:
epoch8841/9000 => Loss:0.45
epoch8861/9000 => Loss:0.45
epoch8881/9000 => Loss:0.45
epoch8901/9000 => Loss:0.45
epoch8921/9000 => Loss:0.45
epoch8941/9000 => Loss:0.45
epoch8961/9000 => Loss:0.45
epoch8981/9000 => Loss:0.45
train Accuracy: 0.8526200873362445
6.使用和评估模型
训练好模型之后我们开始对,模型进行测试评估。代码如下:
# 测试模型
test_input_tensor = torch.from_numpy(test_features).type(torch.FloatTensor)
out_probs = net(test_input_tensor).detach().numpy()
out_classes = np.argmax(out_probs, axis=1)
print("test Accuracy:" ,sum(out_classes == test_labels)/ len(test_labels))得到的结果如下:
test Accuracy: 0.7964376590330788