《从 0 到 1 手写 babel》思路分享
前言
周末我在开心地写着小册的时候,不小心碰倒了饮料,撒了一些在键盘上,虽然我很快的收拾了一下,但电脑却突然关机了。我尝试着重启了一下发现启动不了了,最终确认它坏掉了。
电脑坏掉倒不是我最担心的,主要是我答应了很多读者要下周上线小册,不能再鸽了,可是现在不得不鸽了,因为代码全在那台电脑。
我在想着怎么弥补比较好,想起不少人期待最后的《手写简易的 babel》那个案例的,正好我最近也在写那个案例了,我想着要不提前分享下思路吧。算是一些补偿(也公布下再鸽几天的消息)。
整体思路
babel 的编译流程
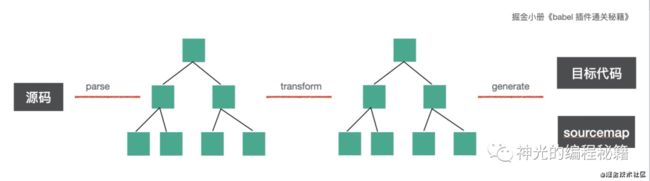
我们知道,babel 的主要编译流程是 parse、transform、generate。
parse 是把源码转成 AST
transform 是对 AST 做增删改
generate 是打印 AST 成目标代码并生成 sourcemap
babel7 内置的包
babel 7 把这些功能的实现放到了不同的包里面:
@babel/parser解析源码成 AST,对应 parse 阶段@babel/traverse遍历 AST 并调用 visitor 函数,对应 transform 阶段@babel/generate打印 AST,生成目标代码和 sorucemap,对应 generate 阶段
其中,遍历过程中需要创建 AST,会用到:
@babel/types创建、判断 AST@babel/template根据模块批量创建 AST
上面是每一个阶段的功能, babel 整体功能的入口是在:
@babel/core解析配置、应用 plugin、preset,完成整体编译流程
插件和插件之间有一些公共函数,这些都是在:
@babel/helpers用于转换 es next 代码需要的通过模板创建的 AST,比如 _typeof、_defineProperties 等@babel/helper-xxx其他的插件之间共享的用于操作 AST 的公共函数
当然,除了编译期转换的时候会有公共函数以外,运行时也有,这部分是放在:
@babel/runtime主要是包含 corejs、helpers、regenerator 这 3 部分:-
helper:helper 函数的运行时版本(不是通过 AST 注入了,而是运行时引入代码)
corejs:es next 的 api 的实现,corejs 2 只支持静态方法,corejs 3 还支持实例方法
regenerator:async await 的实现,由 facebook 维护
(babel 做语法转换是自己实现的 helper,但是做 polyfill 都不是自己实现的,而是借助了第三方的 corejs、regenerator)
我们要实现哪些包
上面介绍的是 babel 完成功能所内置的一些包,我们如果要写一个简易的 babel,也得实现这些包,但可以做一些简化。
parser 包是肯定要实现的,babel parser 是基于 acorn fork 的,我们也基于 acorn,做一点扩展。完成从源码到 AST 的转换。traverse 包是对 AST 的遍历,需要知道不同类型的 AST 都遍历哪些 key,这些是在 @babel/types 包里面定义的,我们也用类似的实现方式,并且会调用对应的 visitor,实现 path 和 path.scope 的一些 api 然后传入。generate 包是打印 AST 成目标代码,生成 sourcemap。打印这部分每个 AST 类型都要写一个对应的函数来处理,生成 sourcemap 使用 source-map 这个包,关联 parse 时记录的 loc 和打印时计算的位置来生成每一个 mapping。types 包用于创建 AST,会维护创建和判断各种 AST 的 api,并且提供每种 AST 需要遍历的属性是哪些,用于 traverse 的过程template 包是批量创建 AST 的,这里我们实现一个简单的版本,传入字符串,parse 成 AST 返回。core 包是整体流程的串联,支持 plugins 和 presets,调用插件,合并成最终的 visitors,然后再 traverse。helper 包我们也会实现一个,因为支持了 plugin,那么中有一些公共的函数可以复用runtime 包我们也提供一下,不过只加入一些用于做语法转换的辅助函数就好了
这是我们大概会做的事情,把这些都实现一遍就算一个比较完整的 babel 了。实现的过程中更能加深我们对 babel、对转译器的认识,不只是掌握 babel 本身。
下面我们来详细分析一下每一步的具体思路:
代码实现
(因为代码在那台坏掉的电脑拿不出来,加上这也不是小册里,所以只会提供思路,等小册上线会提供完整源码的)
为了简化,我们不做分包了,把代码都放在一个包里实现。
parser
主流的 parser 有 esprima、acorn 等,acorn 是最流行的,babel parser 是 fork 自 acorn,做了很多修改。我们不需要 fork,基于 acorn 的插件机制做一些扩展即可。
比如 acorn 所 parse 出的 AST 只有 Literal (字面量)类型,不区分具体是字符串、数字或者布尔等字面量,而 babel parser 把它们细化成了 StringLiteral、NumericLiteral、BooleanLiteral 等 AST。
我们就实现一下对 AST 做了这种扩展的 parser。
我们先用一下原本的 acorn parser:
const acorn = require("acorn");
const Parser = acorn.Parser;
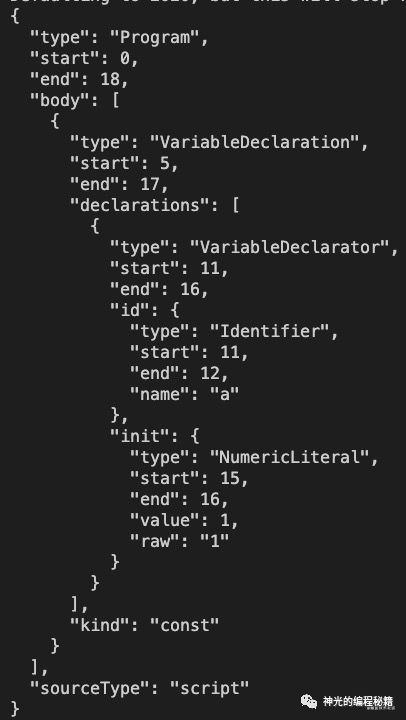
const ast = Parser.parse(`
const a = 1;
`);
console.log(JSON.stringify(ast, null, 2));
打印如下:
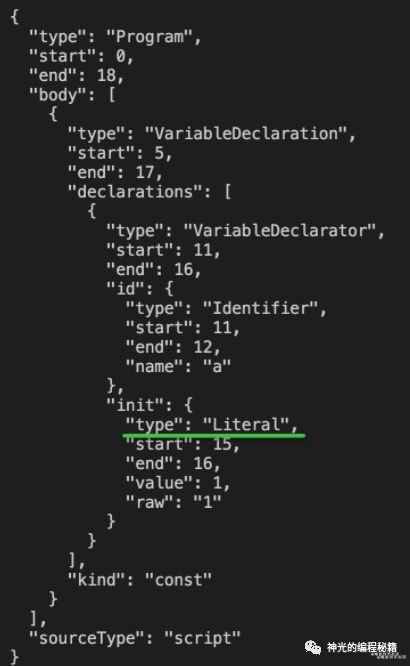
可以看到数字字面量 parse 的结果是 Literal,这样判断类型还需要去看下值的类型,才能确定是什么字面量,比较麻烦。这也是为什么 babel 把它们做了细化。
我们也细化一下:
acorn 扩展的方式是继承 + 重写,继承之前的 parser,重写一些方法,返回新 parser。
const acorn = require("acorn");
const Parser = acorn.Parser;
var literalExtend = function(Parser) {
return class extends Parser {
parseLiteral (...args) {
const node = super.parseLiteral(...args);
switch(typeof node.value) {
case 'number':
node.type = 'NumericLiteral';
break;
case 'string':
node.type = 'StringLiteral';
break;
}
return node;
}
}
}
const newParser = Parser.extend(literalExtend);
const ast = newParser.parse(`
const a = 1;
`);
console.log(JSON.stringify(ast, null, 2));
我们在 parse 的时候就判断了字面量的类型,然后设置了 type。
试下效果:
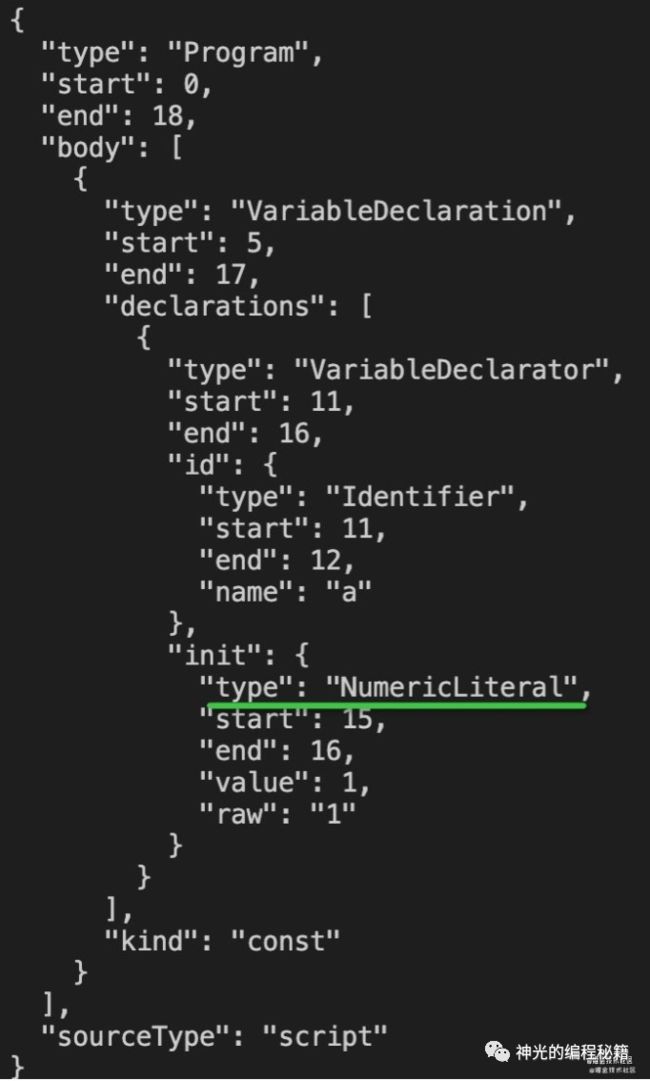
这样,我们就实现了类似 babel parser 对 acorn 的扩展。
当然,babel parser 的扩展有很多,这里我们只是简单实现,理清思路即可。
traverse
遍历 AST 是一个深度优先搜索的过程,当处理到具体的 AST 节点我们要知道怎么继续遍历子 AST 节点。
在 babel types 包中定义了不同 AST 怎么遍历(visitor)、怎么创建(builder)、怎么判断(fidelds.validate)以及别名(alias)。
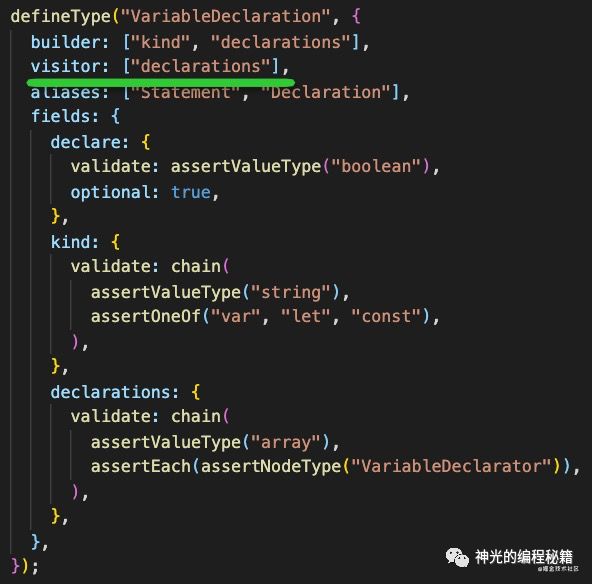 image.png
image.png
这里我们也需要维护每种 AST 怎么遍历的数据:
const AST_DEFINATIONS_MAP = new Map();
AST_DEFINATIONS_MAP.set('Program', {
visitor: ['body']
});
AST_DEFINATIONS_MAP.set('VariableDeclaration', {
visitor: ['declarations']
});
AST_DEFINATIONS_MAP.set('VariableDeclarator', {
visitor: ['id', 'init']
});
AST_DEFINATIONS_MAP.set('Identifier', {});
AST_DEFINATIONS_MAP.set('NumericLiteral', {});
然后基于这些数据对 AST 进行深度优先遍历:
function traverse(node) {
const defination = astDefinationsMap.get(node.type);
console.log(node.type);
if (defination.visitor) {
defination.visitor.forEach(key => {
const prop = node[key];
if (Array.isArray(prop)) { // 如果该属性是数组
prop.forEach(childNode => {
traverse(childNode);
})
} else {
traverse(prop);
}
})
}
}
打印结果如下:
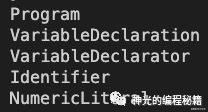
对照下刚才的 AST 结构,确实实现了深度优先遍历。
visitor
遍历之后,我们要实现 visitors 的功能,在遍历的过程中对 AST 做增删改。这个就是遍历的过程中根据 node.type 来调用对应的 visitor 函数:
function traverse(node, visitors) {
const defination = astDefinationsMap.get(node.type);
const visitorFunc = visitors[node.type];
if(visitorFunc && typeof visitorFunc === 'function') {
visitorFunc(node);
}
if (defination.visitor) {
defination.visitor.forEach(key => {
const prop = node[key];
if (Array.isArray(prop)) { // 如果该属性是数组
prop.forEach(childNode => {
traverse(childNode, visitors);
})
} else {
traverse(prop, visitors);
}
})
}
}
我们来试验一下:
traverse(ast, {
Identifier(node) {
node.name = 'b';
}
});
之后再次查看 AST,发现 Identifier 的 name 已经从 a 变成了 b

babel 的 visitor 也支持指定 enter、exit 来选择在遍历子节点之前和之后调用,如果传入的是函数,那么就被当做 enter:
function traverse(node, visitors) {
const defination = astDefinationsMap.get(node.type);
let visitorFuncs = visitors[node.type] || {};
if(typeof visitorFuncs === 'function') {
visitorFuncs = {
enter: visitorFuncs
}
}
visitorFuncs.enter && visitorFuncs.enter(node);
if (defination.visitor) {
defination.visitor.forEach(key => {
const prop = node[key];
if (Array.isArray(prop)) { // 如果该属性是数组
prop.forEach(childNode => {
traverse(childNode, visitors);
})
} else {
traverse(prop, visitors);
}
})
}
visitorFuncs.exit && visitorFuncs.exit(node);
}
这样,我们传入的 visitor 也可以这样写:
traverse(ast, {
Identifier: {
exit(node) {
node.name = 'b';
}
}
});
会在遍历完子节点之后被调用。
path
我们实现的 visitor 是直接传入的 node,但是 AST 中并没有父节点的信息,所以我们要把父节点也传进去。
babel 提供了 path 的功能,它是从当前节点到根节点的一条路径,通过 parent 串联。
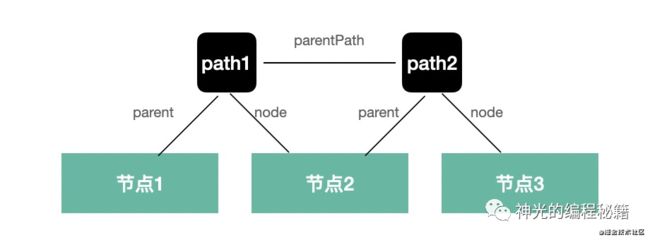
我们封装一个 NodePath 的类:
class NodePath {
constructor(node, parent, parentPath) {
this.node = node;
this.parent = parent;
this.parentPath = parentPath;
}
}
调用 visitor 的时候创建 path 对象传入:
function traverse(node, visitors, parent, parentPath) {
const defination = astDefinationsMap.get(node.type);
let visitorFuncs = visitors[node.type] || {};
if(typeof visitorFuncs === 'function') {
visitorFuncs = {
enter: visitorFuncs
}
}
const path = new NodePath(node, parent, parentPath);
visitorFuncs.enter && visitorFuncs.enter(path);
if (defination.visitor) {
defination.visitor.forEach(key => {
const prop = node[key];
if (Array.isArray(prop)) { // 如果该属性是数组
prop.forEach(childNode => {
traverse(childNode, visitors, node, path);
})
} else {
traverse(prop, visitors, node, path);
}
})
}
visitorFuncs.exit && visitorFuncs.exit(path);
}
这样,我们可以在 visitor 中拿到父节点,父节点的父节点,我们来试一下:
traverse(ast, {
Identifier: {
exit(path) {
path.node.name = 'b';
let curPath = path;
while (curPath) {
console.log(curPath.node.type);
curPath = curPath.parentPath;
}
}
}
});
打印结果如下:
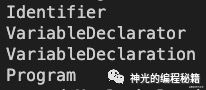
从当前节点到根节点的 AST 都可以获取到。
path 的 api
parent 可以保存,同理 sibling 也可以,也就是说我们可以通过 path 拿到所有的 AST。但是直接操作 AST 有点麻烦,所以我们要提供一些 api 来简化操作。
首先我们要把遍历到的 AST 的属性对应的 key 和如果是数组时对应的 listKey 都保存下来。
class NodePath {
constructor(node, parent, parentPath, key, listKey) {
this.node = node;
this.parent = parent;
this.parentPath = parentPath;
this.key = key;
this.listKey = listKey;
}
}
function traverse(node, visitors, parent, parentPath, key, listKey) {
const defination = astDefinationsMap.get(node.type);
let visitorFuncs = visitors[node.type] || {};
if(typeof visitorFuncs === 'function') {
visitorFuncs = {
enter: visitorFuncs
}
}
const path = new NodePath(node, parent, parentPath, key, listKey);
visitorFuncs.enter && visitorFuncs.enter(path);
if (defination.visitor) {
defination.visitor.forEach(key => {
const prop = node[key];
if (Array.isArray(prop)) { // 如果该属性是数组
prop.forEach((childNode, index) => {
traverse(childNode, visitors, node, path, key, index);
})
} else {
traverse(prop, visitors, node, path, key);
}
})
}
visitorFuncs.exit && visitorFuncs.exit(path);
}
然后基于 key 和 listKey 来实现 replaceWith 和 remove 的 api:
class NodePath {
constructor(node, parent, parentPath, key, listKey) {
this.node = node;
this.parent = parent;
this.parentPath = parentPath;
this.key = key;
this.listKey = listKey;
}
replaceWith(node) {
if (this.listKey) {
this.parent[this.key].splice(this.listKey, 1, node);
}
this.parent[this.key] = node
}
remove () {
if (this.listKey) {
this.parent[this.key].splice(this.listKey, 1);
}
this.parent[this.key] = null;
}
}
试验下效果:
traverse(ast, {
NumericLiteral(path) {
path.replaceWith({ type: 'Identifier', name: 'bbbbbbb' });
}
});
结果为:
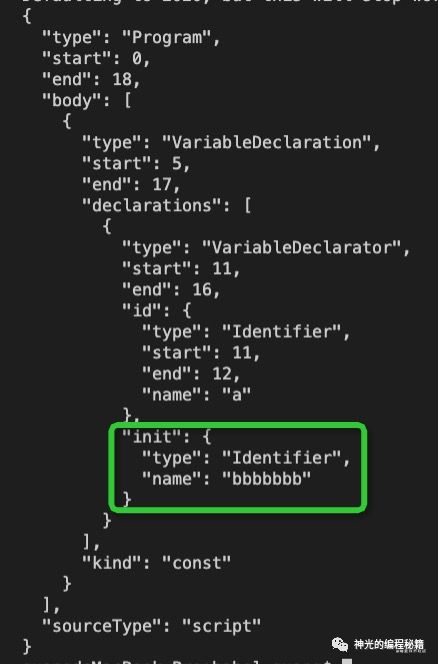
NumericLiteral 被替换为了 Identifier。我们成功的实现了 path.replaceWith。
path.scope
path.scope 是作用域的信息,记录声明的变量的 binding、它们的引用 reference、在哪里被修改 (constantViolations),以及父作用域等。是静态作用域链的实现。
实现思路:
首先函数、块、模块都会生成作用域,当处理到这些 AST 时要创建一个 Scope 对象,它有 bindings 属性,每一个声明都会创建一个 binding(比如变量声明语句 VariableDeclaration、函数声明语句 FuncitonDeclaration 以及参数、import 等)
通过 Identifier 引用这些作用域中的 binding 的时候就会记录 references,如果被修改,则记录修改的语句的 AST 对应的 path,比如赋值语句。
同样需要提供一系列 api 来简化作用域的分析和操作,比如查找 getBinding、删除 removeBinding、重命名 rename 等。
篇幅关系,这里就不做实现了,《babel 插件通关秘籍》小册中会有完整的实现。
types
在 traverse 的时候我们实现了 path.replaceWith 的 api,用于替换 AST 成新的 AST,我们是直接传入了字面量对象,这种方式比较麻烦。babel 是通过 types 包来提供创建 AST 的能力,我们来分析一下实现思路:
其实创建 AST 节点也是一个递归的过程,需要保证每一部分都是正确的,我们在遍历的时候保存了 visitor 的 key,在创建的时候仍然是创建这些 key 对应的 AST,不过需要对传入的参数做一下检验。
defineType("BinaryExpression", {
builder: ["operator", "left", "right"],
fields: {
operator: {
validate: assertOneOf(...BINARY_OPERATORS),
},
left: {
validate: assertNodeType("Expression"),
},
right: {
validate: assertNodeType("Expression"),
},
},
visitor: ["left", "right"],
aliases: ["Binary", "Expression"],
});
babel 内部通过 defineType 方法定义 AST 类型的创建逻辑,其中 fileds 属性包含了这个 AST 需要什么属性,每种属性怎么校验。通过校验之后会根据相应的参数创建 AST。
template
babel template 是通过字符串批量创建 AST,我们可以基于 parser 实现一个简单的 template
function template(code) {
return parse(code);
}
template.expression = function(code) {
return template(code).body[0].expression;
}
上面的代码就可以变成:
traverse(ast, {
NumericLiteral(path) {
path.replaceWith(template.expression('bbb'));
}
});
generate
上面都是对 AST 的增删改,接下来我们来实现下 generate,把 AST 打印成目标代码。
其实就是一个拼接字符串的过程:
class Printer {
constructor () {
this.buf = '';
}
space() {
this.buf += ' ';
}
nextLine() {
this.buf += '\n';
}
Program (node) {
node.body.forEach(item => {
this[item.type](item) + ';';
this.nextLine();
});
}
VariableDeclaration(node) {
this.buf += node.kind;
this.space();
node.declarations.forEach((declaration, index) => {
if (index != 0) {
this.buf += ',';
}
this[declaration.type](declaration);
});
this.buf += ';';
}
VariableDeclarator(node) {
this[node.id.type](node.id);
this.buf += '=';
this[node.init.type](node.init);
}
Identifier(node) {
this.buf += node.name;
}
NumericLiteral(node) {
this.buf += node.value;
}
}
class Generator extends Printer{
generate(node) {
this[node.type](node);
return this.buf;
}
}
function generate (node) {
return new Generator().generate(node);
}
我们来试验一下:
const sourceCode = `
const a = 1,b=2,c=3;
const d=4,e=5;
`;
ast = parse(sourceCode);
traverse(ast, {
NumericLiteral(path) {
if (path.node.value === 2) {
path.replaceWith(template.expression('aaaaa'));
}
}
})
console.log(generate(ast));
打印结果如下:
const a=1,b=aaaaa,c=3;
const d=4,e=5;
我们成功的实现了 generate 方法。
sourcemap
generator 除了打印目标代码外还要生成 sourcemap,这个是转译器很重要的一个功能。
sourcemap 的实现思路也比较简单:
parse 之后的 AST 中保留了源码中的位置信息(行列号),在打印成目标代码的时候计算新的行列号,这样有了新旧行列号,就可以用 source-map 包的 api 生成 sourcemap 了。
var map = new SourceMapGenerator({
file: "source-mapped.js"
});
map.addMapping({
generated: {
line: 10,
column: 35
},
source: "foo.js",
original: {
line: 33,
column: 2
},
name: "christopher"
});
console.log(map.toString());
// '{"version":3,"file":"source-mapped.js",
// "sources":["foo.js"],"names":["christopher"],"mappings":";;;;;;;;;mCAgCEA"}'
core
上面我们已经实现了全流程的功能,但是平时我们平时很少使用 api,更多还是使用全流程的包 @babel/core,所以要基于上面的包实现 core 包,然后支持 plugin 和 preset。
function transformSync(code, options) {
const ast = parse(code);
const pluginApi = {
template
}
const visitors = {};
options.plugins.forEach(([plugin, options]) => {
const res = plugin(pluginApi, options);
Object.assign(visitors, res.visitor);
})
traverse(ast, visitors);
return generate(ast);
}
plugin 支持传入 options,并且在 plugin 里面可以拿到 api 和 options,返回值是 visitor 函数:
const sourceCode = `
const a = 1;
`;
const code = transformSync(sourceCode, {
plugins: [
[
function plugin1(api, options) {
return {
visitor: {
Identifier(path) {
// path.node.value = 2222;
path.replaceWith(api.template.expression(options.replaceName));
}
}
}
},
{
replaceName: 'ddddd'
}
]
]
});
console.log(code);
结果为:
const ddddd=1;
至此我们完成了 babel 所有内置功能的简易版本实现。(helper 就是一个放公共函数的包, runtime 是用于运行时引入的 api,这两个包比较简单,就不实现了。在《babel 插件通关秘籍》的小册里面会详细实现)
总结
我们梳理了 babel 的编译流程和内置的包的各自的功能,然后明确了我们要实现的包:parser、traverse、generate、types、template、core。接下来依次做了实现或梳理了实现思路。
parser 包基于 acorn,babel 是 fork 自 acorn,我们是直接基于 acorn 插件来修改 AST。我们实现了 Literal 的 AST 的扩展。
traverse 包负责遍历 AST,我们通过记录 visitor key 实现了 AST 的深度优先遍历,并且在遍历的过程中调用 visitor,而且还支持 enter 和 exit 两个阶段的调用。visitor 传入的参数支持了 path,可以拿到 parent,可以调用 replaceWith 和 remove 等 api。我们还梳理了实现 scope 的思路。
types 和 template 都是用于创建 AST 的,我们梳理了 types 的实现思路,就是递归创建 AST 然后组装,实现了简单的 template,使用直接从字符串 parse 的方式。
generate 包负责把修改以后的 AST 打印成目标代码以及生成 sourcemap,我们实现了代码的打印。梳理了 sourcemap 的思路。
core 包是整个编译流程的集成,而且支持 plugins 和 preset,我们实现了 transformSync 的 api,也支持了 plugin 的调用。
上面就是 babel 的实现思路,细化一下是能够实现一个完整功能的 babel 的。
这个是《babel 插件通关秘籍》 的最后一个案例,小册中的实现思路和代码会更清晰,也会提供源码。
这周末电脑突然坏了,代码可能也有丢失,所以不得不鸽一段时间。但是挺多人挺期待这本小册上线的,我实在过意不过,所以把大家感兴趣的《手写简易的 babel》的实现思路分享了出来,希望能够帮大家更好的掌握 babel 以及类似的编译器。(小册在我电脑修好后也会尽快写完的)