dlib库包的介绍与使用,opencv+dlib检测人脸框、opencv+dlib进行人脸68关键点检测,opencv+dlib实现人脸识别,dlib进行人脸特征聚类、dlib视频目标跟踪
文章目录:
- 1 dlib库介绍
- 2 dlib人脸检测:绘制出人脸检测框
-
- 2.1 dlib人脸检测源码
- 2.2 opencv + dlib 人脸检测
- 2.3 dlib人脸检测总结
- 3 dlib人脸关键点检测:并绘制检测框、关键点、不同区域关键点连线
-
- 3.1 dlib人脸关键点检测源码
- 3.2 opencv + dlib 进行人脸关键点检测
- 4 dlib人脸识别
-
- 4.1 dlib进行人脸识别逻辑
- 4.2 opencv+dlib 进行人脸识别
- 4.3 人脸识别总结
- 5 dlib人脸聚类
- 6 dlib视频目标跟踪
1 dlib库介绍
dlib官网:http://dlib.net/
dlib模型文件和源码下载:http://dlib.net/files/
dlib介绍
dlib人脸检测与人脸识别
2 dlib人脸检测:绘制出人脸检测框
2.1 dlib人脸检测源码
1、人脸检测,dlib官方例子face_detector.py
- face detector
这个人脸检测器是使用现在经典的直方图定向梯度(HOG)特征,结合线性分类器,图像金字塔和滑动窗口检测方案。这种类型的物体检测器是相当普遍的,除了人脸之外,还能够检测许多类型的半刚性物体。因此,如果您对制作自己的对象检测器感兴趣,那么请阅读train_object _detector.py示例程序。
# coding=utf-8
"""
Copyright (c) 2018-2022. All Rights Reserved.
@author: shliang
@email: [email protected]
"""
import dlib
def dlib_detector_face(img_path):
print("Processing file: {}".format(img_path))
img = dlib.load_rgb_image(img_path)
# dlib正面人脸检测器
detector = dlib.get_frontal_face_detector()
win = dlib.image_window()
# 1 表示图像向上采样一次,图像将被放大一倍,这样可以检测更多的人脸
dets = detector(img, 1)
print("Number of faces detected: {}".format(len(dets)))
for i, d in enumerate(dets):
# 人脸的左上和右下角坐标
print("Detection {}: Left: {} Top: {} Right: {} Bottom: {}".format(i, d.left(), d.top(), d.right(), d.bottom()))
win.clear_overlay()
win.set_image(img)
win.add_overlay(dets)
dlib.hit_enter_to_continue()
# 让检测器获取人脸得分score,约有把握的检测,得分越高。
# 第三个参数调整检测的阈值,负值将返回更多的检测结果,而正值将返回较少的检测结果
# 同时idx会告诉你那个面部对应的检测结果,用来广泛识别不同方向的面孔,idx的具体含义我还没有弄清楚
# 如果第三个参数设置位-2就会输出更多的检测结果,如果你设置为1可能就没有检测结果
dets, scores, idx = detector.run(img, 1, -1) # 把-1以上的score的检测结果全部输出
for i, d in enumerate(dets):
print("Detection {}, score: {}, face_type:{}".format(d, scores[i], idx[i]))
if __name__ == '__main__':
dlib_detector_face('./images/single_face.jpg')
dlib_detector_face('./images/multi_face.jpg')
输出结果:
Processing file: ./images/single_face.jpg
Number of faces detected: 1
Detection 0: Left: 118 Top: 139 Right: 304 Bottom: 325
Hit enter to continue
Detection [(118, 139) (304, 325)], score: 1.6567257084382887, face_type:0
Detection [(55, 218) (98, 262)], score: -0.6576982940533731, face_type:2
Processing file: ./images/multi_face.jpg
Number of faces detected: 3
Detection 0: Left: 339 Top: 82 Right: 468 Bottom: 211
Detection 1: Left: 163 Top: 140 Right: 270 Bottom: 247
Detection 2: Left: 265 Top: 136 Right: 354 Bottom: 226
Hit enter to continue
Detection [(339, 82) (468, 211)], score: 1.9180631791420404, face_type:1
Detection [(163, 140) (270, 247)], score: 1.5263808407319899, face_type:0
Detection [(265, 136) (354, 226)], score: 1.153857532931697, face_type:0
如下是检测结果:

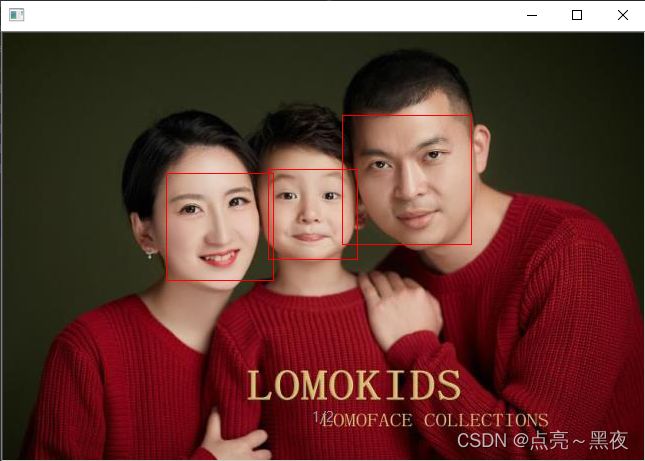
2.2 opencv + dlib 人脸检测
1、把上面的代码改用opencv读取与显示
# coding=utf-8
"""
Copyright (c) 2018-2022. All Rights Reserved.
@author: shliang
@email: [email protected]
"""
import dlib
import cv2
def dlib_detector_face(img_path):
print("Processing file: {}".format(img_path))
img = cv2.imread(img_path)
# dlib正面人脸检测器
detector = dlib.get_frontal_face_detector()
# 1 表示图像向上采样一次,图像将被放大一倍,这样可以检测更多的人脸
dets = detector(img, 1)
print('dets:', dets) # dets: rectangles[[(118, 139) (304, 325)]]
print("Number of faces detected: {}".format(len(dets)))
for i, d in enumerate(dets):
# 人脸的左上和右下角坐标
left = d.left()
top = d.top()
right = d.right()
bottom = d.bottom()
print("Detection {}: Left: {} Top: {} Right: {} Bottom: {}".format(i, left, top, right, bottom))
cv2.rectangle(img, (left, top), (right, bottom), color=(0, 255, 255), thickness=1, lineType=cv2.LINE_AA)
cv2.imshow('detect result', img)
cv2.waitKey(0)
if __name__ == '__main__':
dlib_detector_face('./images/single_face.jpg')
dlib_detector_face('./images/multi_face.jpg')
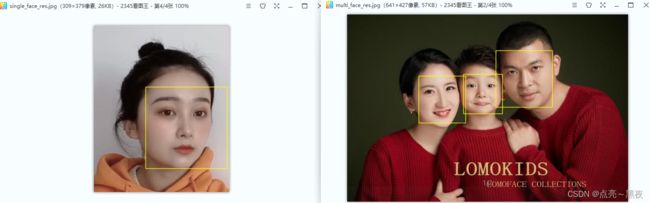
2.3 dlib人脸检测总结
1、dlib人脸检测效果
dlib人脸检测并不是很准确,如果人脸比较小,有大角度偏转,很有可能就检测不到人脸,我以为dlib版本更新了,人脸检测的模型也会更新,其实不是,dlib是一个机器学习库,里面有很多算法的!
2、使用dlib的场景
- 最好是正脸
- 图像分辨率不能太小
- 图像清晰
3 dlib人脸关键点检测:并绘制检测框、关键点、不同区域关键点连线
3.1 dlib人脸关键点检测源码
1、人脸关键点检测,dlib官方例子face_detector.py
- face detector
# coding=utf-8
"""
Copyright (c) 2018-2022. All Rights Reserved.
@author: shliang
@email: [email protected]
"""
import dlib
# 下载人脸关键点检测模型: http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2
predictor_path = './model/shape_predictor_68_face_landmarks.dat'
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(predictor_path)
win = dlib.image_window()
# face_image_path = './images/single_face.jpg'
face_image_path = './images/multi_face.jpg'
print("Processing file: {}".format(face_image_path))
img = dlib.load_rgb_image(face_image_path)
win.clear_overlay()
win.set_image(img)
# Ask the detector to find the bounding boxes of each face. The 1 in the
# second argument indicates that we should upsample the image 1 time. This
# will make everything bigger and allow us to detect more faces.
dets = detector(img, 1)
print("Number of faces detected: {}".format(len(dets)))
for k, d in enumerate(dets):
print("Detection {}: Left: {} Top: {} Right: {} Bottom: {}".format(
k, d.left(), d.top(), d.right(), d.bottom()))
# Get the landmarks/parts for the face in box d.
shape = predictor(img, d)
print("Part 0: {}, Part 1: {} ...".format(shape.part(0),
shape.part(1)))
# Draw the face landmarks on the screen.
win.add_overlay(shape)
win.add_overlay(dets)
dlib.hit_enter_to_continue()
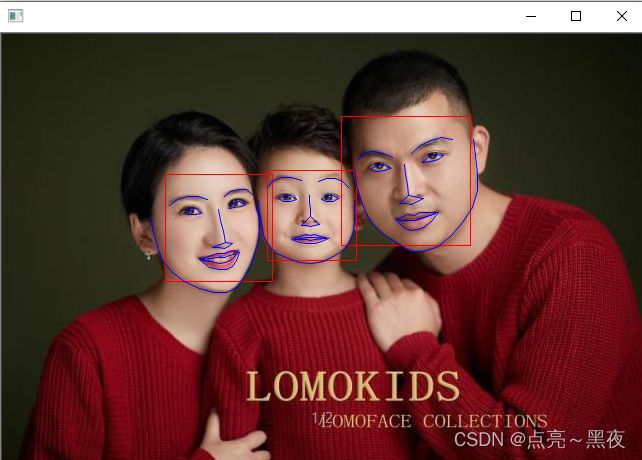
3.2 opencv + dlib 进行人脸关键点检测
# coding=utf-8
"""
Copyright (c) 2018-2022. All Rights Reserved.
@author: shliang
@email: [email protected]
"""
import os
import cv2
import dlib
import numpy as np
pred_types = {'face': ((0, 17), (0.682, 0.780, 0.909, 0.5)),
'eyebrow1': ((17, 22), (1.0, 0.498, 0.055, 0.4)),
'eyebrow2': ((22, 27), (1.0, 0.498, 0.055, 0.4)),
'nose': ((27, 31), (0.345, 0.239, 0.443, 0.4)),
'nostril': ((31, 36), (0.345, 0.239, 0.443, 0.4)),
'eye1': ((36, 42), (0.596, 0.875, 0.541, 0.3)),
'eye2': ((42, 48), (0.596, 0.875, 0.541, 0.3)),
'lips': ((48, 60), (0.596, 0.875, 0.541, 0.3)),
'teeth': ((60, 68), (0.596, 0.875, 0.541, 0.4))
}
# 绘制直线和关键点
def draw_line(img, shape, i):
cv2.line(img, pt1=(shape.part(i).x, shape.part(i).y), pt2=(shape.part(i+1).x, shape.part(i+1).y),
color=(0, 255, 0), thickness=1, lineType=cv2.LINE_AA)
# 连成一圈
def draw_line_circle(img, shape, i, start, end):
cv2.line(img, pt1=(shape.part(i).x, shape.part(i).y), pt2=(shape.part(i + 1).x, shape.part(i + 1).y),
color=(0, 255, 0), thickness=1, lineType=cv2.LINE_AA)
cv2.line(img, pt1=(shape.part(start).x, shape.part(start).y), pt2=(shape.part(end).x, shape.part(end).y),
color=(0, 255, 0), thickness=1, lineType=cv2.LINE_AA)
# 使用训练好的模型shape_predictor_68_face_landmarks.dat检测出人脸上的68个关键点
def dlib_face_keypoint_detector(img_path, save_result=True):
# 检测人脸框
detector = dlib.get_frontal_face_detector()
# 下载人脸关键点检测模型: http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2
predictor_path = './model/shape_predictor_68_face_landmarks.dat'
# 检测人脸关键点
predictor = dlib.shape_predictor(predictor_path)
img = cv2.imread(img_path)
print("Processing file: {}".format(img_path))
# # 1 表示图像向上采样一次,图像将被放大一倍,这样可以检测更多的人脸
dets = detector(img, 1)
print("Number of faces detected: {}".format(len(dets)))
for k, d in enumerate(dets):
x1 = d.left()
y1 = d.top()
x2 = d.right()
y2 = d.bottom()
print("Detection {}: Left: {} Top: {} Right: {} Bottom: {}".format(k, x1, y1, x2, y2))
cv2.rectangle(img, (x1, y1), (x2, y2), color=(0, 255, 255), thickness=1, lineType=cv2.LINE_AA)
# Get the landmarks/parts for the face in box d.
shape = predictor(img, d)
# print(dir(shape)) # 'num_parts', 'part', 'parts', 'rect'
print(shape.num_parts) # 68 打印出关键点的个数
print(shape.rect) # 检测到每个面部的矩形框 [(118, 139) (304, 325)]
print(shape.parts()) # points[(147, 182), (150, 197), (154, 211), (160, 225),...,(222, 227), (215, 228)] # 68个关键点坐标
# print(type(shape.part(0))) # 注意:
# 检测人脸框
detector = dlib.get_frontal_face_detector()
# 下载人脸关键点检测模型: http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2
predictor_path = './model/shape_predictor_68_face_landmarks.dat'
# 检测人脸关键点
predictor = dlib.shape_predictor(predictor_path)
如果循环检测多张图片,detector和predictor只需要在最开始调用,相当于是加载模型,不用每次都加载,如果每次都加载你检测一张图片的时间大概是2s,如果只在最开始加载,检测每张图片关键点的时间为50ms左右
看下68个关键点的位置,然后进行连线:



4 dlib人脸识别
4.1 dlib进行人脸识别逻辑
1、首先需要需要构建一个人脸识别的底库(专业点就叫gallery),也就是每一个人在数据库中注册一张人脸图片,这里假设./images/recog_face/register是我们注册的人脸数据,每张人脸数据是包含人脸ID(这里我就先简单用文件名表示,如reba,表示的是迪丽热巴,实际场景中一般注册的都是提前提取好的人脸特征)
2、提取注册图片中的人脸
- 注册的图片每张图片中只能有一张图片
- 注册图片最好是正脸照片、无遮挡、光照良好
- 总之注册图片的质量必须比较好
3、提取待识别图片中的人脸特征:./images/recog_face/test_face:目录下待识别的人脸,我们并不知道每张图片中人脸的真实身份(我的图片命名成已知身份,只是为了方便后续和识别结果做对比)
4、特征比对:将待识别图片中提取的人脸特征 和 注册数据中的每张人脸特征都做比对,然后取特征距离最近的一张注册数据,如果距离小于设定的阈值,则该注册数据的ID身份则为识别未知人脸的身份,否则在数据库中没有正确匹配识别都人脸
- 待识别的人脸图片在数据库中可能是有的,但由于人脸角度大、遮挡等,导致计算出的特征距离比较大,因此也就不能正确识别!
注意:
在提取图片中人脸特征之前,是先经过了检测人脸 和 人脸对齐操作的,可以看下面具体代码!
如下是我人脸识别图片相关路径:
images/recog_face/register:注册的人脸images/recog_face/test_face:待识别人脸图片images/recog_face/recog_result:保存识别人脸的结果
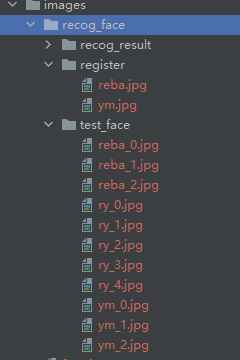
4.2 opencv+dlib 进行人脸识别
1、dlib通过检测出每个人脸框,然后对人脸框中的每张人脸进行特征提取,每张人脸特征映射为一个128维的向量,当两个向量之间的Euclidean距离小于0.6时,可以认为属于同一个人
2、这里需要用到两个模型:
- 人脸68关键点检测模型:
shape_predictor_68_face_landmarks.dat - 人脸识别模型:
dlib_face_recognition_resnet_model_v1.dat
以上判定标准在LFW(Labeled Faces in the Wild)数据集上可以获得99.38%的识别准确率
3、你也可以这样调用这个函数:face_descriptor = facerec.compute_face_descriptor(img, shape, 100, 0.25) 在LFW(Labeled Faces in the Wild)上:
- 不使用100的参数值在LFW获得99.13%的准确率,
- 使用100的参数值获得99.38%的准确率,但是使用100的参数值后调用的执行速度慢了100倍,
所以选择你可以根据需要选择使不使用该参数。
解释一下:
-
第三个参数100:告诉代码
抖动/重新采样图像的次数。当将其设置为100时,它将对稍微修改过的面部版本执行100次面部描述符提取,并返回平均结果。您还可以选择一个更中间的值,比如10,它的速度只有10倍,但仍然可以获得99.3%的LFW精度。 -
第四个参数0.25:是脸周围的填充。如果填充== 0,那么对齐时将会在面部周围被紧密裁剪。设置更大的填充值将导致更松散的裁剪。特别是0.5的填充值将使裁剪区域的宽度加倍,即值为1会是三倍,以此类推。还有另一个compute_face_descriptor重载,它可以将一个对齐的图像作为输入。注意,将对齐的图像生成为dlib是很重要的。Get_face_chip会这样做,即大小必须是150x150,居中并缩放。
# coding=utf-8
"""
Copyright (c) 2018-2022. All Rights Reserved.
@author: shliang
@email: [email protected]
"""
import cv2
import os
import dlib
import glob
import numpy as np
# 计算两个特征向量的欧式距离
# 定义一个计算Euclidean距离的函数
def Eucl_distance(a, b):
'''
d = 0
for i in range(len(a)):
d += (a[i] - b[i]) * (a[i] - b[i])
return np.sqrt(d)
:param a:
:param b:
:return:
'''
return np.linalg.norm(a - b, ord=2)
# 提取人脸的128维特征向量
def extract_face_feature(img_array):
predictor_path = './model/shape_predictor_68_face_landmarks.dat'
face_rec_model_path = './model/dlib_face_recognition_resnet_model_v1.dat'
# 导入需要的模型,人脸检测、人脸68个关键点检测模型、人脸识别模型
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(predictor_path)
facerec = dlib.face_recognition_model_v1(face_rec_model_path)
# 当前帧中所有人脸的特征
# 1 表示图像向上采样一次,图像将被放大一倍,这样可以检测更多的人脸
dets = detector(img_array, 1)
print("Number of faces detected: {}".format(len(dets)))
# 一张图片中可能有多张脸,每张都要验证,同时保存每张人脸的矩形框坐标,用于后续处理
all_face_feature = []
all_face_rect = []
# Now process each face we found.
for k, d in enumerate(dets):
x1 = d.left()
y1 = d.top()
x2 = d.right()
y2 = d.bottom()
print("Detection {}: Left: {} Top: {} Right: {} Bottom: {}".format(k, x1, y1, x2, y2))
all_face_rect.append([x1, y1, x2, y2])
shape = predictor(img_array, d)
# Draw the face landmarks on the screen so we can see what face is currently being processed.
# 把人脸的特征表示成128维向量,然后计算两张人脸的128维向量之间的欧式距离,一般来说如果距离小于0.6认为是同一个人
# 如果距离大于0.6则认为是不同的人!
face_descriptor = facerec.compute_face_descriptor(img_array, shape) # 人脸特征秒描述子
print("Computing descriptor on aligned image ..")
# 使用get_face_chip函数生成对齐后的图像
face_chip = dlib.get_face_chip(img_array, shape)
# 然后将对齐后图像chip(aligned image)传给api
face_descriptor_from_prealigned_image = facerec.compute_face_descriptor(face_chip)
# print(type(face_descriptor_from_prealigned_image)) # 如下时人脸识别的结果:

再调几张:




4.3 人脸识别总结
1、首先注册(入库)的图片的质量要好
2、需要选择一个合适的阈值,虽然dlib介绍如再LFW上准确率有有91.3%,但是再实际场景中这个准确率肯定会大打折扣的
3、dlib人脸识别的速度也不是很快,还有很多地方需要优化的,通过了解dlib人脸识别可以大概了解做人脸识别的一个基本流程:
- 人脸检测
- 人脸裁剪对齐
- 人脸特征提取
- 人脸特征比对,即人脸识别
具体做成一个人脸识别系统,还有很多细节,以及对自己的人脸识别系统的评测等!
人脸识别参考(参考、参考、参考)
参考:https://blog.csdn.net/weixin_33696106/article/details/87951676
5 dlib人脸聚类
# coding=utf-8
"""
Copyright (c) 2018-2022. All Rights Reserved.
@author: shliang
@email: [email protected]
"""
import os
import dlib
import glob
import cv2
import numpy as np
from collections import Counter
def dlib_face_cluster():
predictor_path = './model/shape_predictor_68_face_landmarks.dat'
face_rec_model_path = './model/dlib_face_recognition_resnet_model_v1.dat'
# 图片来源:https://github.com/davisking/dlib/tree/master/examples/johns
faces_path = glob.glob('./images/cluster/johns/*/*.jpg')
output_folder_path = './images/cluster/johns_output'
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(predictor_path)
facerec = dlib.face_recognition_model_v1(face_rec_model_path)
descriptors = []
images = []
# 获取所有人脸的关键点检测结果 和 128D向量表示
for img_path in faces_path:
print("Processing file: {}".format(img_path))
img = cv2.imread(img_path)
dets = detector(img, 1)
print("Number of faces detected: {}".format(len(dets)))
# 处理检测到每张人脸
for k, d in enumerate(dets):
# shape 检测到人脸的关键点
shape = predictor(img, d)
# print(dir(shape)) # 'num_parts', 'part', 'parts', 'rect'
print(shape.num_parts) # 68 打印出关键点的个数
print(shape.rect) # 检测到每个面部的矩形框 [(118, 139) (304, 325)]
print(
shape.parts()) # points[(147, 182), (150, 197), (154, 211), (160, 225),...,(222, 227), (215, 228)] # 68个关键点坐标
# print(type(shape.part(0))) # 6 dlib视频目标跟踪
1、源码
- 需要先手动指定要跟踪物体在
视频第一帧的位置,就是矩形框的坐标 - 然后在命令行中回车就可以不断更新之后每一帧更新的结果
# coding=utf-8
"""
Copyright (c) 2018-2022. All Rights Reserved.
@author: shliang
@email: [email protected]
"""
import dlib
import cv2
# 物体追踪是指,对于视频文件,在第一帧指定一个矩形区域,对于后续帧自动追踪和更新区域的位置
def dlib_video_object_tracking():
tracker = dlib.correlation_tracker()
win = dlib.image_window()
cap = cv2.VideoCapture('./images/cars_cut.mp4')
i = 0
while True:
ret, frame = cap.read()
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 首先指定要追踪物体所在的矩形框位置
if i == 0:
tracker.start_track(frame, dlib.rectangle(400, 380, 500, 475))
# 后续帧,自动追踪
else:
tracker.update(frame)
i += 1
win.clear_overlay()
win.set_image(frame)
win.add_overlay(tracker.get_position())
dlib.hit_enter_to_continue()
if __name__ == '__main__':
dlib_video_object_tracking()
第一帧:
第N帧的跟踪结果:
2、改进:
通过python+opencv,用鼠标的方式获取视频中待跟踪目标框:
- 还没有完全搞定,待更新!