非结构化知识抽取 -- pipeline方法 joint方法
目录
非结构化知识抽取内容
实体关系抽取问题定义
实体关系抽取方法
pipeline方法:实体识别、关系分类
实体识别挑战: 实体嵌套
序列标注
指针标注
span标注
关系分类
非监督方法
监督方法
远程监督
关系重叠
另外一个pipeline方法
Joint方法
方法介绍 Joint-CasRel
方法介绍 TPLinker
方法介绍 - PRGC
非结构化知识抽取内容
知识抽取包含:实体抽取、概念抽取、属性抽取、关系抽取、事件抽取;
例子:新冠知识图谱
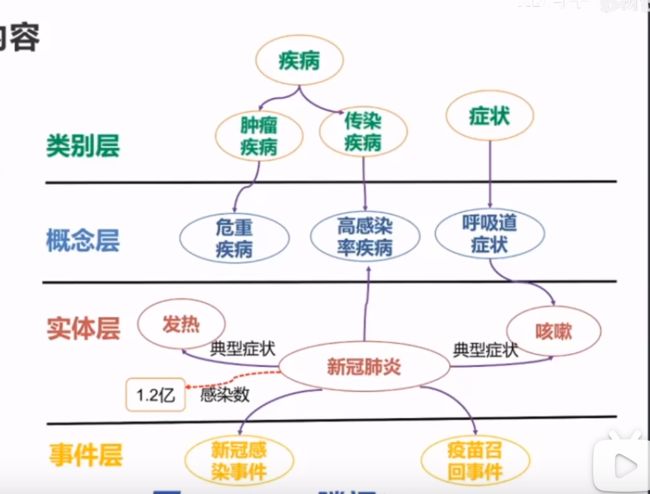
将上述知识抽取进行简化,主要就是对关系和实体的抽取;
实体关系抽取问题定义
输入句子X,句子的起始位置SATRT(i), 终止位置END(i), 某个span  ;
;
句子span: ![]() ;
;
预定义的实体类型E;
预定义的关系类型R;
实体识别![]() , 识别出每个span的实体类型;
, 识别出每个span的实体类型;
关系抽取![]() , tuple,获得实体对之间的关系
, tuple,获得实体对之间的关系
实体关系抽取方法
pipeline方法:
命名实体识别: 序列标注、指针标注、span标注;
关系分类:监督方法、远程监督、无监督方法;
灵活性高,子任务高度解耦,可以分别使用独立的数据集和模型;
缺点:实体冗余、交互缺失、误差累积;
Joint方法:
共享参数多任务学习;
联合解码的结构化预测;
联合建模实体关系的内在联系;缓解误差累积;
缺点:耦合度高,模型复杂,较难针对某个字子任务进行针对性改进;
pipeline方法:实体识别、关系分类
实体识别挑战: 实体嵌套
三种实体类型;
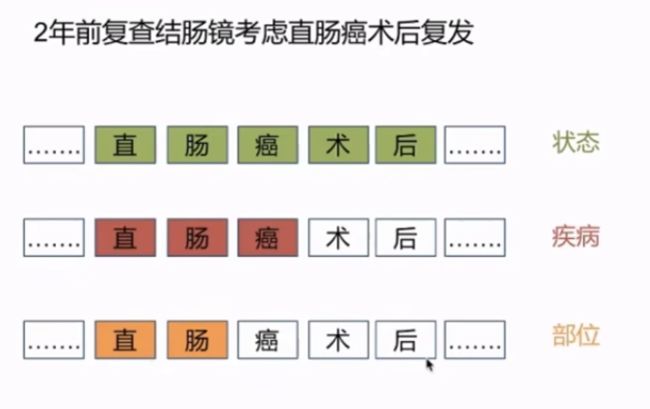
解决方案:
序列标注、指针标注、span标注
序列标注
多标签标注:
直属于状态、疾病实体类型的begin;
肠属于状态、疾病实体类型的internal;
以此类推。。。

单标签标注:
一条句子,对于每一类实体类型都进行预测其在该实体类型中所处的位置;
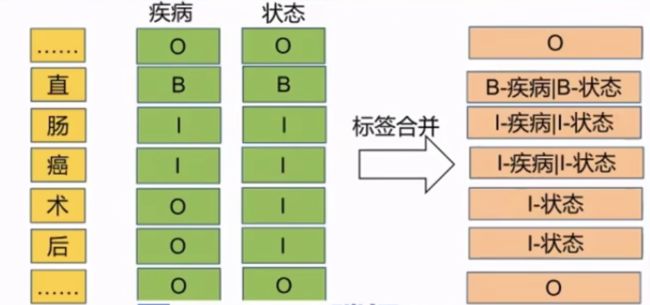
缺点:
标注与训练复杂;解码依赖缺失、稀疏标签、准确度待提升;
指针标注
对每一个实体类别确定一个指针网络,对指针网络的解码,得到实体类别的start 和 end,不需要对每个char进行预测;
也有使用问答的方式对针织网络类别进行划分,如给出问题 疾病实体是什么,目标是从answer中找到span,识别start和end;
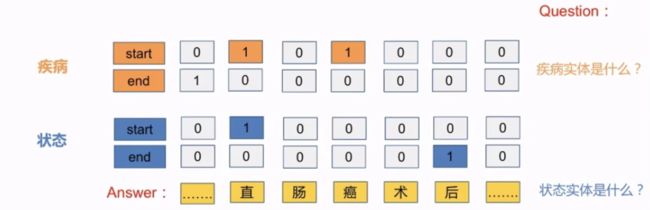
缺点:
对识别边界比较敏感,识别不稳定;
span标注
枚举出所有可能的span,对每个span进行类别的预测(也可以通过构造span矩阵的方法):

优点: 召回高
缺点:复杂度高,大量负采样;
关系分类
无监督: 规则模版, bootstrapping;
优点: 查准率(Precision)高,尤其是合作特定领域的关系抽取;
缺点: 查全率低(recall),针对每一种关系,需要手写大量的规则;
有监督: 传统ML,深度模型;
优点:准确率、召回率较高;
缺点:标注成本高,泛化能力弱,增加新的关系成本高;
半监督(远程监督): 远程监督
优点:标注成本低;
缺点:准度不可控,效果严重依赖数据、关系类型和领域;
非监督方法
规则模版:

bootstrapping:通过一个模版扩展到多个模版

监督方法
PCNN网络识别+ soft Max --> 分类,增加特征 提升关系分类效果
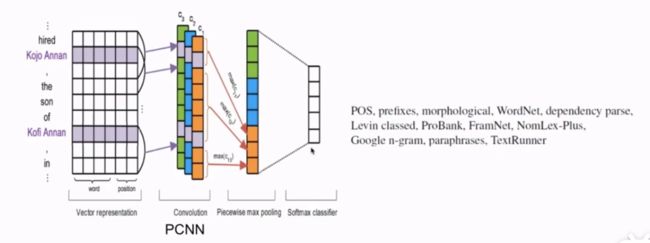
远程监督
主要是为了解决关于标注的问题
选取高质量的种子,远程标记,只要包含这两个实体,就假设是知识图谱中的那种关系 ,通过pattern学习,获取更多这个pattern的文本,提取出更多的tuple加到种子库中;

多实例学习的方式处理:
单句标注,找更多的句子,更多的句子对应更多的样本,更多的样本可能会有正确的样本;
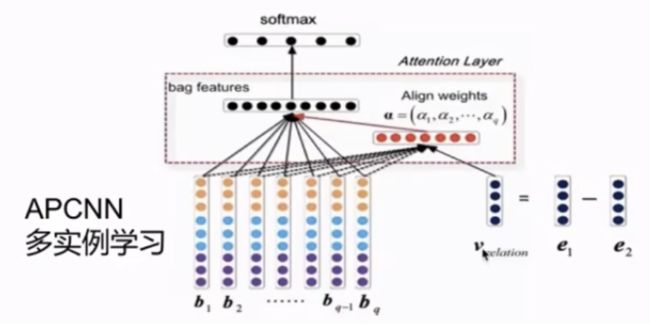
单句标注 -- > Bag标注 APCNN方法
先从知识库找到种子,通过种子找到sentences,把sentences进行bag级别的标注,通过设计模型选择sentence,这些sentence更容易表达子类的关系;

APCNN是一种多实例学习的方法:
最重要的就是实例的选择,使用了relation specific方法;
relation的计算是通过头实体和尾实体向量的计算,得到relation的表达;
之后将每一个relation和sentences进行attention的计算,最后经过多分类;
关系重叠
Single Entity Overlap(SEO): 不同三元组共享头实体或尾实体;
Entity pair Overlap(EPO): 不同三元组共享头实体和尾实体;
现在很多的关系抽取方法,都是围绕着关系重叠的问题来设计;
另外一个pipeline方法
Joint方法
pipeline存在的主要问题: 关系嵌套、实体嵌套; 错误累积、任务关联补充;
解决思路: 共享参数encoder, 联合/分开decoder,目标函数损失叠加loss;
方法介绍 Joint-CasRel
论文链接: https://arxiv.org/abs/1909.03227
基本思路:

建模给定句子三元组的概率;
首先给定一句话,经过Bert encoder,先进性Subject Tagger的识别,通过指针网络的方法,识别一个start 和 end ,计算出 下的subject的概率;
下的subject的概率;
之后会将subject的信息输入到下一层的网络,下一层网络是对每一个relation进行了划分,在识别relation的时候识别相应的object,
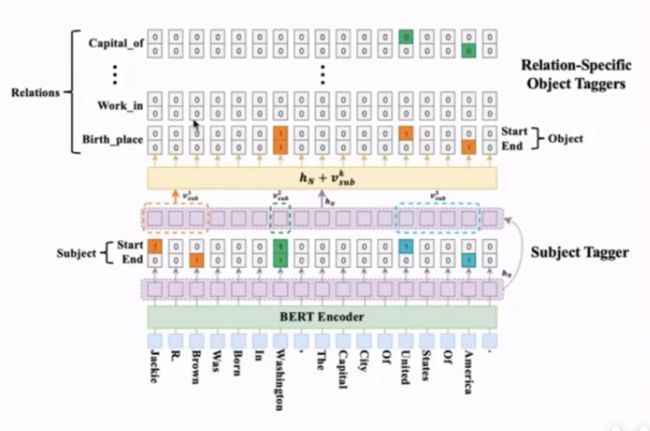
公式6,7 是通过指针网络识别subject;
公式9,10 是计算在相应的关系下的object

这个模型对于关系重叠的处理更加有优势;
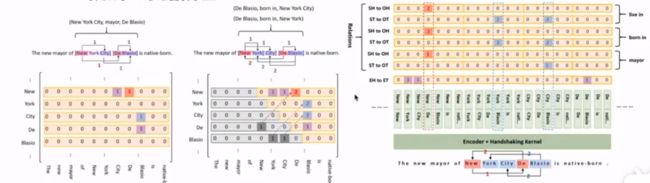
方法介绍 TPLinker
TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
通过结构化预测,解决了关系重叠和暴露偏差的问题;
暴露偏差:指在训练阶段是gold实体输入进行关系预测,而在推断阶段是上一步的预测实体输入进行关系判断;导致训练和推断存在不一致;
论文链接: AP-CNN: Weakly Supervised Attention Pyramid Convolutional Neural Network for Fine-Grained Visual Classification | IEEE Journals & Magazine | IEEE Xplore
论文解读: 实体关系抽取新范式!TPLinker:单阶段联合抽取,并解决暴漏偏差~ - 知乎
方法介绍 - PRGC
论文链接:https://arxiv.org/pdf/2106.09895.pdf
论文解读: PRGC:一种新的联合关系抽取模型_NLP论文解读的博客-CSDN博客
