使用KNN实现MNIST数据分类(详细解释附完整程序)
数据读取
import operator
import os
import matplotlib.pyplot as plt
import numpy as np
import torchvision.datasets as dsets
from torch.utils.data import DataLoader
relative_path = os.getcwd()
batch_size = 100
train_dataset = dsets.MNIST(root=relative_path + '\pymnist', # 选择数据的根目录
train=True, # 选择训练集
transform=None, # 不使用任何数据预处理
download=False) # 从网络上下载图片
test_dataset = dsets.MNIST(root=relative_path + '\pymnist', # 选择数据的根目录
train=False, # 选择测试集
transform=None, # 不适用任何数据预处理
download=False) # 从网络上下载图片
加载数据
训练集包括60000个样本,测试数据集包括10000个样本。
在MNIST数据集中,每张图片均由28 × \times × 28的像素展开为一个一维的行向量,这些行向量就是图片数组里的行(每行784个值,或者说每行就代表了一张图片)
训练集以及测试集的标签包含了相应的目标变量,也就是手写数字的类标签
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=True)
print("train_data:", train_dataset.data.size())
print("train_labels:", train_dataset.data.size())
print("test_data:", test_dataset.data.size())
print("test_labels:", test_dataset.data.size())
先来了解一下MNIST中的图片看起来是什么,对他进行可视化处理,通过Matplotlib的imshow函数进行绘制
digit = train_loader.dataset.data[0] # 取第一个图片的数据
plt.imshow(digit, cmap=plt.cm.binary)
plt.show()
print(train_loader.dataset.targets[0])
在真正使用Python实现KNN算法之前,我们先来剖析一下思想,这里我们以MNIST的60000张图片作为训练集,我们希望对测试数据集的10000张图片全部打上标签。KNN算法将会比较测试图片与训练集中每一张图片,然后将它认为最相似的那个训练集图片的标签赋给这张测试图片
那么,具体应该如何比较这两张图片呢?在本例中,比较图片就是比较28×28的像素块。最简单的方法就是逐个像素进行比较,最后将差异值全部加起来
两张图片使用L1距离来进行比较。逐个像素求差值,然后将所有差值加起来得到一个数值。如果两张图片一模一样,那么L1距离为0,但是如果两张图片差别很大,那么,L1的值将会非常大。
def KNN_classify(k, dis, train_data, train_label, test_data):
assert dis == 'E' or dis == 'M', 'dis must be E or M, E代表欧拉距离,M代表曼哈顿距离'
num_test = test_data.shape[0] # 测试样本的数量
label_list = []
if dis == 'E':
# 欧拉距离的实现
for i in range(num_test):
distances = np.sqrt(np.sum(((train_data - np.tile(test_data[i], (train_data.shape[0], 1))) ** 2), axis=1))
nearest_k = np.argsort(distances)
top_k = nearest_k[:k] # 选取前k个距离
class_count = {}
for j in top_k:
class_count[train_label[j]] = class_count.get(train_label[j], 0) + 1
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
label_list.append(sorted_class_count[0][0])
else:
# 曼哈顿距离
for i in range(num_test):
distances = np.sum(np.abs(train_data - np.tile(test_data[i], (train_data.shape[0], 1))), axis=1)
nearest_k = np.argsort(distances)
top_k = nearest_k[:k]
class_count = {}
for j in top_k:
class_count[train_label[j]] = class_count.get(train_label[j], 0) + 1
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
label_list.append(sorted_class_count[0][0])
return np.array(label_list)
直接使用KNN
if __name__ == '__main__':
# 训练数据
train_data = train_loader.dataset.data.numpy()
train_data = train_data.reshape(train_data.shape[0], 28 * 28)
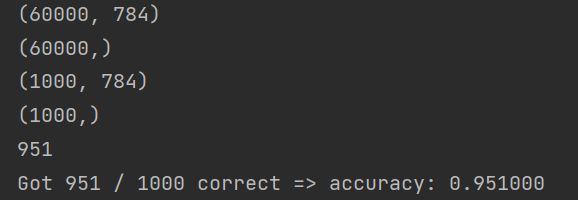
print(train_data.shape)
train_label = train_loader.dataset.targets.numpy()
print(train_label.shape)
# 测试数据
test_data = test_loader.dataset.data[:1000].numpy()
test_data = test_data.reshape(test_data.shape[0], 28 * 28)
print(test_data.shape)
test_label = test_loader.dataset.targets[:1000].numpy()
print(test_label.shape)
# 训练
test_label_pred = KNN_classify(5, 'M', train_data, train_label, test_data)
# 得到训练准确率
num_test = test_data.shape[0]
num_correct = np.sum(test_label == test_label_pred)
print(num_correct)
accuracy = float(num_correct) / num_test
print('Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy))
运行结果:

进行归一化处理后再进行分类
def getXmean(data):
data = np.reshape(data, (data.shape[0], -1))
mean_image = np.mean(data, axis=0)
return mean_image
def centralized(data, mean_image):
data = data.reshape((data.shape[0], -1))
data = data.astype(np.float64)
data -= mean_image # 减去图像均值,实现领均值化
return data
if __name__ == '__main__':
# 训练数据
train_data = train_loader.dataset.data.numpy()
mean_image = getXmean(train_data) # 计算所有图像均值
train_data = centralized(train_data, mean_image) # 对训练集图像进行均值化处理
print(train_data.shape)
train_label = train_loader.dataset.targets.numpy()
print(train_label.shape)
# 测试数据
test_data = test_loader.dataset.data[:1000].numpy()
test_data = centralized(test_data, mean_image) # 对测试集数据进行均值化处理
print(test_data.shape)
test_label = test_loader.dataset.targets[:1000].numpy()
print(test_label.shape)
# 训练
test_label_pred = KNN_classify(5, 'M', train_data, train_label, test_data)
# 得到训练准确率
num_test = test_data.shape[0]
num_correct = np.sum(test_label == test_label_pred)
print(num_correct)
accuracy = float(num_correct) / num_test
print('Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy))
运行结果:
完整程序
#!/usr/bin/env python
# coding: utf-8
# # 使用KNN实现MNIST数据分类
# ## 数据读取
import operator
import os
import matplotlib.pyplot as plt
import numpy as np
import torchvision.datasets as dsets
from torch.utils.data import DataLoader
relative_path = os.getcwd()
batch_size = 100
train_dataset = dsets.MNIST(root=relative_path + '\pymnist', # 选择数据的根目录
train=True, # 选择训练集
transform=None, # 不使用任何数据预处理
download=False) # 从网络上下载图片
test_dataset = dsets.MNIST(root=relative_path + '\pymnist', # 选择数据的根目录
train=False, # 选择测试集
transform=None, # 不适用任何数据预处理
download=False) # 从网络上下载图片
# ## 加载数据
# 训练集包括60000个样本,测试数据集包括10000个样本。
# 在MNIST数据集中,每张图片均由28 $\times$ 28的像素展开为一个一维的行向量,这些行向量就是图片数组里的行(每行784个值,或者说每行就代表了一张图片)
# 训练集以及测试集的标签包含了相应的目标变量,也就是手写数字的类标签
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=True)
print("train_data:", train_dataset.data.size())
print("train_labels:", train_dataset.data.size())
print("test_data:", test_dataset.data.size())
print("test_labels:", test_dataset.data.size())
# 先来了解一下MNIST中的图片看起来是什么,对他进行可视化处理,通过Matplotlib的imshow函数进行绘制
digit = train_loader.dataset.data[0] # 取第一个图片的数据
plt.imshow(digit, cmap=plt.cm.binary)
plt.show()
print(train_loader.dataset.targets[0])
# 在真正使用Python实现KNN算法之前,我们先来剖析一下思想,这里我们以MNIST的60000张图片作为训练集,我们希望对测试数据集的10000张图片全部打上标签。KNN算法将会比较测试图片与训练集中每一张图片,然后将它认为最相似的那个训练集图片的标签赋给这张测试图片
# 那么,具体应该如何比较这两张图片呢?在本例中,比较图片就是比较28×28的像素块。最简单的方法就是逐个像素进行比较,最后将差异值全部加起来
# 两张图片使用L1距离来进行比较。逐个像素求差值,然后将所有差值加起来得到一个数值。如果两张图片一模一样,那么L1距离为0,但是如果两张图片差别很大,那么,L1的值将会非常大。
def KNN_classify(k, dis, train_data, train_label, test_data):
assert dis == 'E' or dis == 'M', 'dis must be E or M, E代表欧拉距离,M代表曼哈顿距离'
num_test = test_data.shape[0] # 测试样本的数量
label_list = []
if dis == 'E':
# 欧拉距离的实现
for i in range(num_test):
distances = np.sqrt(np.sum(((train_data - np.tile(test_data[i], (train_data.shape[0], 1))) ** 2), axis=1))
nearest_k = np.argsort(distances)
top_k = nearest_k[:k] # 选取前k个距离
class_count = {}
for j in top_k:
class_count[train_label[j]] = class_count.get(train_label[j], 0) + 1
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
label_list.append(sorted_class_count[0][0])
else:
# 曼哈顿距离
for i in range(num_test):
distances = np.sum(np.abs(train_data - np.tile(test_data[i], (train_data.shape[0], 1))), axis=1)
nearest_k = np.argsort(distances)
top_k = nearest_k[:k]
class_count = {}
for j in top_k:
class_count[train_label[j]] = class_count.get(train_label[j], 0) + 1
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
label_list.append(sorted_class_count[0][0])
return np.array(label_list)
if __name__ == '__main__':
# 训练数据
train_data = train_loader.dataset.data.numpy()
train_data = train_data.reshape(train_data.shape[0], 28 * 28)
print(train_data.shape)
train_label = train_loader.dataset.targets.numpy()
print(train_label.shape)
# 测试数据
test_data = test_loader.dataset.data[:1000].numpy()
test_data = test_data.reshape(test_data.shape[0], 28 * 28)
print(test_data.shape)
test_label = test_loader.dataset.targets[:1000].numpy()
print(test_label.shape)
# 训练
test_label_pred = KNN_classify(5, 'M', train_data, train_label, test_data)
# 得到训练准确率
num_test = test_data.shape[0]
num_correct = np.sum(test_label == test_label_pred)
print(num_correct)
accuracy = float(num_correct) / num_test
print('Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy))
# 进行归一化处理后再进行分类
def getXmean(data):
data = np.reshape(data, (data.shape[0], -1))
mean_image = np.mean(data, axis=0)
return mean_image
def centralized(data, mean_image):
data = data.reshape((data.shape[0], -1))
data = data.astype(np.float64)
data -= mean_image # 减去图像均值,实现领均值化
return data
if __name__ == '__main__':
# 训练数据
train_data = train_loader.dataset.data.numpy()
mean_image = getXmean(train_data) # 计算所有图像均值
train_data = centralized(train_data, mean_image) # 对训练集图像进行均值化处理
print(train_data.shape)
train_label = train_loader.dataset.targets.numpy()
print(train_label.shape)
# 测试数据
test_data = test_loader.dataset.data[:1000].numpy()
test_data = centralized(test_data, mean_image) # 对测试集数据进行均值化处理
print(test_data.shape)
test_label = test_loader.dataset.targets[:1000].numpy()
print(test_label.shape)
# 训练
test_label_pred = KNN_classify(5, 'M', train_data, train_label, test_data)
# 得到训练准确率
num_test = test_data.shape[0]
num_correct = np.sum(test_label == test_label_pred)
print(num_correct)
accuracy = float(num_correct) / num_test
print('Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy))