K邻近算法概述、欧式距离、Scikit-learn使用 、kNN邻近算法距离度量、曼哈顿距离、切比雪夫距离、闵可夫斯基距离、标准化欧氏距离、余弦距离、汉明距离、杰卡德距离、马氏距离
一、K-邻近算法概述
K邻近算(K Nearest Neighbor算法,KNN算法):如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别
KNN是机器学习中比较经典的分类算法,最早是由Cover和Hart在1968年提出,应用场景有字符识别、文本分类、图像识别等领域,根据邻居来推断类型
1.1 KNN实现流程
- 计算已知类别数据集中的点与当前点之间的距离
- 按距离递增次序排序
- 选取与当前点距离最小的k个点
- 统计前k个点所在的类别出现的频率
- 返回前k个点出现频率最高的类别作为当前点的预测分类
1.2 欧氏距离
两个样本间的距离可以通过距离公式计算,又叫欧式距离

使用K邻近算法可以预测电影类型,根据每部电影和被预测电影中的搞笑镜头、拥抱镜头和打斗镜头等的数量来进行距离计算,从而预测电影类型为喜剧片、爱情片或是动作片等
1.3 机器学习流程
- 获取数据集
- 数据基本处理
- 特征工程
- 机器学习
- 模型评估
二、Scikit-learn使用
Scikit-learn是Python语言的机器学习工具,包括许多知名的机器学习算法的实现,文档完善,容易上手,具有丰富的API
2.1 scikit-learn安装
安装:切换到指定虚拟环境下,执行以下命令(安装scikit-learn需要先安装Numpy, Scipy等库),如下
pip install scikit-learn
Scikit-learn包含的内容:分类、聚类、回归、特征工程、降维、模型选择、调优等
2.2 K-近邻算法API
- sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)
- n_neighbors:int,可选,默认为5,k_neighbors查询默认使用的邻居数,即选定参考几个邻居
使用代码如下
from sklearn.neighbors import KNeighborsClassifier
# 构造数据集
x = [[1], [3], [5], [0], [-1]] # 创建数据
y = [1, 1, 1, 0, 0] # 指定分类为1和0,两个类别
model = KNeighborsClassifier(n_neighbors=2) # 实例化训练模型
model.fit(x, y) # 调用fit方法进行训练
print(model.predict([[5]])) # 预测其他值,特征值加两个中括号,分类为1
print(model.predict([[-5]])) # 预测其他值,特征值加两个中括号,分类为0
print(model.predict([[0]])) # 预测其他值,特征值加两个中括号,分类为0
输出:
[1]
[0]
[0]三、距离度量
除了上述所说的欧氏距离,常见的还有以下距离度量
3.1 曼哈顿距离
在曼哈顿街区要从一个十字路口开车到另一个十字路口,驾驶距离显然不是两点间的直线距离。这个实际驾驶距离就是“曼哈顿距离”。曼哈顿距离也称为“城市街区距离”(City Block distance)

3.2 切比雪夫距离
国际象棋中,国王可以直行、横行、斜行,所以国王走一步可以移动到相邻8个方格中的任意一个。国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?这个距离就叫切比雪夫距离(维度的最大值)
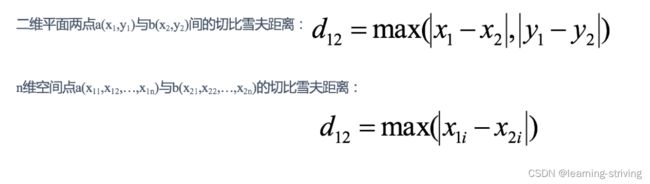
3.3 闵可夫斯基距离(Minkowski Distance)
闵氏距离不是一种距离,而是一组距离的定义,是对多个距离度量公式的概括性的表述,两个n维变量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的闵可夫斯基距离定义为
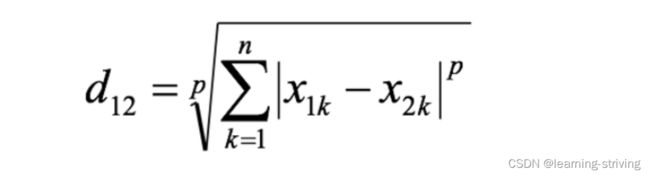
- 其中,p是一个变参数:
- p=1时:为曼哈顿距离
- p=2时:为欧氏距离
- p→∞时:为切比雪夫距离
- 根据p的不同,闵氏距离可以表示某一类/种的距离
- 闵氏距离缺点:将各个分量的量纲(scale),也就是“单位”相同的看待了,未考虑各个分量的分布(期望,方差等)可能是不同的,如二维样本(身高[单位:cm],体重[单位:kg])中身高与体重单位不能划等号
欧氏距离、曼哈顿距离、切比雪夫距离和闵可夫斯基距离都是将单位相同看待
3.4 标准化欧氏距离 (Standardized EuclideanDistance)
标准化欧氏距离是针对欧氏距离的缺点而作的一种改进,思路:既然数据各维分量的分布不一样,那先将各个分量都“标准化”到均值、方差相等。假设样本集X的均值(mean)为m,标准差(standard deviation)为s,X的“标准化变量”表示为

若将方差的倒数看成一个权重,也可称之为加权欧氏距离(Weighted Euclidean distance)
3.5 余弦距离
几何中,夹角余弦可用来衡量两个向量方向的差异,机器学习中,借用这一概念来衡量样本向量之间的差异

- 夹角余弦取值范围为[-1,1]
- 余弦越大表示两个向量的夹角越小
- 余弦越小表示两向量的夹角越大
- 当两个向量的方向重合时余弦取最大值1
- 当两个向量的方向完全相反余弦取最小值-1
3.6 汉明距离(Hamming Distance)
两个等长字符串s1与s2的汉明距离为:将其中一个变为另外一个所需要作的最小字符替换次数
汉明重量:是字符串相对于同样长度的零字符串的汉明距离,也就是说,它是字符串中非零的元素个数:对于二进制字符串来说,就是 1 的个数,所以 11101 的汉明重量是 4。因此,如果向量空间中的元素a和b之间的汉明距离等于它们汉明重量的差a-b
3.7 杰卡德距离(Jaccard Distance)
杰卡德相似系数(Jaccard similarity coefficient):两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示
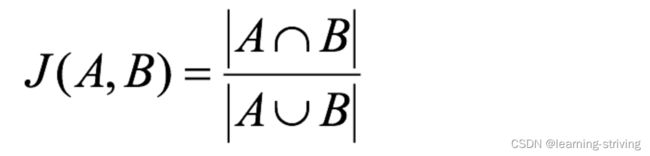
杰卡德距离(Jaccard Distance):与杰卡德相似系数相反,用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度
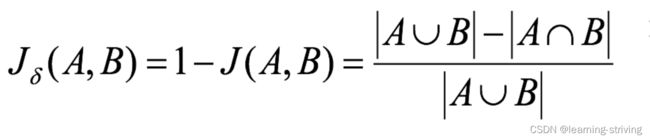
3.8 马氏距离(Mahalanobis Distance)
马氏距离是基于样本分布的一种距离,由印度统计学家马哈拉诺比斯提出的,表示数据的协方差距离,是一种有效的计算两个位置样本集的相似度的方法。与欧式距离不同的是,它考虑到各种特性之间的联系,即独立于测量尺度
马氏距离定义:设总体G为m维总体(考察m个指标),均值向量为μ=(μ1,μ2,…,μm),协方差阵为∑=(σij),则样本X=(X1,X2,…,Xm),与总体G的马氏距离定义为:
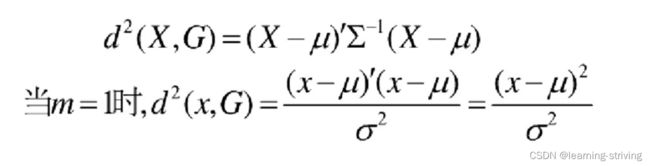
马氏距离也可以定义为两个服从同一分布并且其协方差矩阵为∑的随机变量的差异程度:
- 若协方差矩阵为单位矩阵,马氏距离就简化为欧式距离
- 若协方差矩阵为对角矩阵,则其也可称为正规化的欧式距离
马氏距离特性:
- 量纲无关,排除变量之间的相关性的干扰
- 马氏距离的计算是建立在总体样本的基础上的,如果拿同样的两个样本,放入两个不同的总体中,最后计算得出的两个样本间的马氏距离通常是不相同的,除非这两个总体的协方差矩阵碰巧相同
- 计算马氏距离过程中,要求总体样本数大于样本的维数,否则得到的总体样本协方差矩阵逆矩阵不存在,这种情况下,用欧式距离计算即可
- 还有一种情况,满足了条件总体样本数大于样本的维数,但是协方差矩阵的逆矩阵仍然不存在,比如三个样本点(3,4),(5,6),(7,8),这种情况是因为这三个样本在其所处的二维空间平面内共线。这种情况下,也采用欧式距离计算
学习导航:http://xqnav.top/