轻量化卷积神经网络-Mobile Net V1 简介
大纲
- Mobile Net V1简介
- 分组卷积
- 串联信息
- 分组+串联
- Mobile Net V1的深度可分离卷积
- 模型网络结构
- 代码实现
Mobile Net V1简介
随着2012年的AlexNet在ImageNet竞赛中获得冠军,越来越多的深度神经网络被人们提出,例如优秀的VGG系列、GoogleNet、Resnet系列等等。这些深度学习算法相较于传统机器学习分类算法而言,已经相当的出色,但是随着人们不断的加深网络,模型计算量产生的巨大存储压力和计算开销,已经开始严重影响深度神经网络在一些低功率领域的应用,例如ResNet系列中的ResNet152,网络层数已经达到152层,模型权重大小达到上百兆,这也使得我们几乎不可能在ARM芯片上跑ResNet152。
近些年,使用AI系统的机器人、无人驾驶、智能手机以及各类可穿戴设备的发展日新月异,急需一种能在算法层面有效的压缩存储和计算量的方法,使AI算法能在有限的计算平台上有效运转。而Mobile Net对传统卷积模块进行了改进,该结构更高效,为在移动设备上部署带来了可能。

Mobile Net V1是2017年Google发布的网络架构,正如其名,它是一种模型体积较小、可训练参数及计算量较少并适用于移动设备的卷积神经网络。旨在充分利用有限的计算资源,最大化模型的准确性,以满足有限资源下的各种应用案例,是部署至边缘侧常用的模型之一。mobileNet V1的主要创新点是用深度可分离卷积(depthwise separable convolution)代替普通的卷积,并使用宽度乘数(width multiply)减少参数量,它可在牺牲极少精度的同时去换取更好的数据吞吐量。
分组卷积
如果想要学习深度可分离卷积,首先要了解什么是分组卷积(Group Convolution),可以说,看懂了分组卷积,也就明白了什么是深度可分离卷积。分组卷积最早见于AlexNet,当时使用分组卷积的目的是将整个模型拆分成两块,这样就可以放到2个GPU上进行并行运算。
首先我们假设卷积的输入特征图尺寸为 W ∗ H ∗ C i n W*H*C_{in} W∗H∗Cin ,在padding为same,stride为1的情况下,输出特征图尺寸为 W ∗ H ∗ C o u t W*H*C_{out} W∗H∗Cout 。
首先我们先看看标准卷积的计算:
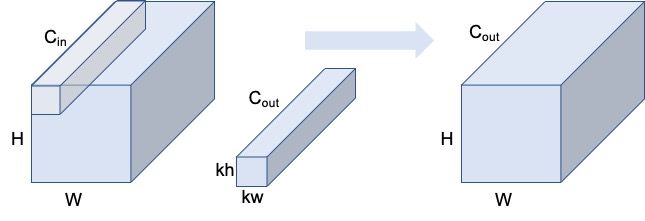
如果使用标准卷积进行计算,我们可知,此时的理论计算量FLOPs为:
F L O P s = k w ∗ k h ∗ C i n ∗ C o u t ∗ W ∗ H \begin{aligned} FLOPs=k_{w} * k_{h}*C_{in}*C_{out}*W*H\\ \end{aligned}\\ FLOPs=kw∗kh∗Cin∗Cout∗W∗H
而分组卷积就是将输入的拆分为g个独立分组(假设可整除),分别进行卷及计算,可表示为:
- 把输入特征图拆分为g组,每组尺寸为 W ∗ H ∗ ( C i n / g ) W*H*(C_{in}/g) W∗H∗(Cin/g) ;
- 把输出特征图也拆分为g组,每组尺寸为 W ∗ H ∗ ( C o u t / g ) W*H*(C_{out}/g) W∗H∗(Cout/g) ;
- 按顺序对每组内的特征图做普通卷及计算,输出g个 W ∗ H ∗ ( C o u t / g ) W*H*(C_{out}/g) W∗H∗(Cout/g) 的特征图,总的输出和最开始定义的 W ∗ H ∗ C o u t W*H*C_{out} W∗H∗Cout 的输出尺寸一致。

此时我们的理论计算量FLOPs为:
F L O P s = ( k w ∗ k h ∗ C i n / g ∗ C o u t / g ∗ W ∗ H ) ∗ g = k w ∗ k h ∗ C i n ∗ C o u t ∗ W ∗ H g \begin{aligned} FLOPs&=(k_{w} * k_{h}*C_{in}/g*C_{out}/g*W*H)*g\\ &=\frac{k_{w} * k_{h}*C_{in}*C_{out}*W*H}{g} \end{aligned}\\ FLOPs=(kw∗kh∗Cin/g∗Cout/g∗W∗H)∗g=gkw∗kh∗Cin∗Cout∗W∗H
串联信息
经过刚才的分组卷积计算,我们最终得到的输出虽然尺寸与原始假设的尺寸一致,并成功将理论计算量成果缩减了g倍,但是每一个分组之间并没有关联,不能共享信息,这是一个致命的缺陷,是我们所不能接受的。那么怎么才能让各个组之间进行信息整合呢?这时我们可以使用卷积核大小为(1,1)的普通卷积,在对上述所得结果进行一次卷积操作,这样就可以把原本不关联的信息串在一起整合起来。
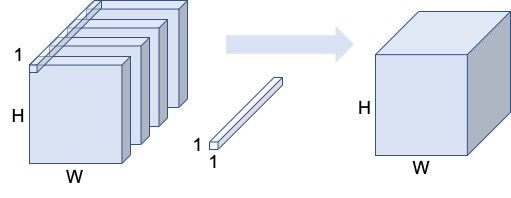
此时我们的理论计算量FLOPs为:
F L O P s = 1 ∗ 1 ∗ C i n ∗ C o u t ∗ W ∗ H = C i n ∗ C o u t ∗ W ∗ H \begin{aligned} FLOPs&=1 * 1*C_{in}*C_{out}*W*H\\ &=C_{in}*C_{out}*W*H \end{aligned}\\ FLOPs=1∗1∗Cin∗Cout∗W∗H=Cin∗Cout∗W∗H
分组+串联
把前面两节的计算合并在一起,我们就完成了一套先分组、后串联的双重卷积操作,这使我们在减少理论计算量的同时,还能保持卷积神经网络的可用性。那么首先,我们来计算一下分组+串联卷积的总理论计算量
F L O P s = k w ∗ k h ∗ C i n ∗ C o u t ∗ W ∗ H g + C i n ∗ C o u t ∗ W ∗ H = k w ∗ k h ∗ C i n ∗ C o u t ∗ W ∗ H + g ∗ C i n ∗ C o u t ∗ W ∗ H g = ( C i n ∗ C o u t ∗ W ∗ H ) ∗ ( k w ∗ k h + g ) g \begin{aligned} FLOPs&=\frac{k_{w} * k_{h}*C_{in}*C_{out}*W*H}{g}+C_{in}*C_{out}*W*H\\ &=\frac{k_{w} * k_{h}*C_{in}*C_{out}*W*H+g*C_{in}*C_{out}*W*H}{g}\\ &=\frac{(C_{in}*C_{out}*W*H)*(k_{w} * k_{h}+g)}{g} \end{aligned}\\ FLOPs=gkw∗kh∗Cin∗Cout∗W∗H+Cin∗Cout∗W∗H=gkw∗kh∗Cin∗Cout∗W∗H+g∗Cin∗Cout∗W∗H=g(Cin∗Cout∗W∗H)∗(kw∗kh+g)
我们来对比一下,普通卷积与分组+串联卷积的计算量差异有多少:
分 组 串 联 F L O P s 标 准 卷 积 F L O P s = ( C i n ∗ C o u t ∗ W ∗ H ) ∗ ( k w ∗ k h + g ) g k w ∗ k h ∗ C i n ∗ C o u t ∗ W ∗ H = k w ∗ k h + g k w ∗ k h ∗ g = 1 k w ∗ k h + 1 g \begin{aligned} \frac{分组串联_{FLOPs}}{标准卷积_{FLOPs}}&=\frac{\frac{(C_{in}*C_{out}*W*H)*(k_{w}*k_{h}+g)}{g}}{k_{w}*k_{h}*C_{in}*C_{out}*W*H}\\ &=\frac{k_{w}*k_{h}+g}{k_{w}*k_{h}*g}\\ &=\frac{1}{k_{w}*k_{h}}+\frac{1}{g} \end{aligned}\\ 标准卷积FLOPs分组串联FLOPs=kw∗kh∗Cin∗Cout∗W∗Hg(Cin∗Cout∗W∗H)∗(kw∗kh+g)=kw∗kh∗gkw∗kh+g=kw∗kh1+g1
由此可见,分组+串联卷积能极其有效的缩小理论计算量,并且在常用卷积核大小不变的情况下(常用卷积核为(3,3)),分组越多,缩小的理论计算量就也越多。
Mobile Net V1的深度可分离卷积
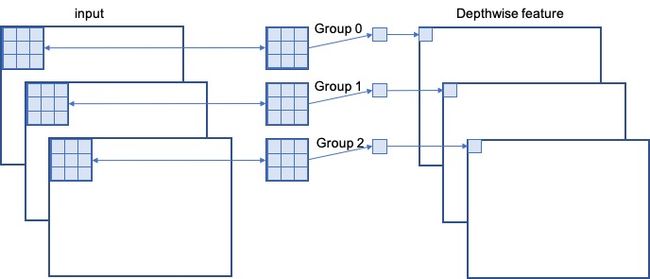
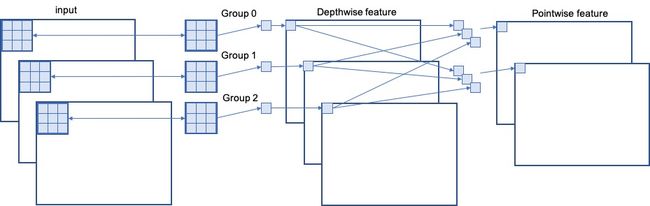
我们在一开始的时候提到过,Mobile Net V1的主要创新点是用深度可分离卷积(depthwise separable convolution)代替普通的卷积,而深度可分离卷积的核心思想在就于把普通卷积拆分为Depthwise+Pointwise两部分。其中Depthwise就对应着分组卷积,Pointwise就对应着串联信息。只不过,Mobile Net V1是分组卷积的极端表现,即“Group= C i n C_{in} Cin ”,也就是输入的每一个通道都单独当做一个组来计算。
让我们再次回顾一下之前所学的内容:
标准卷积的计算方式为:
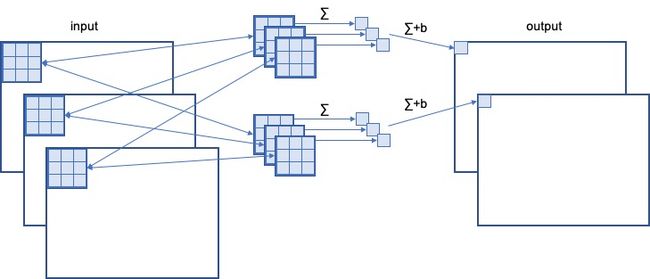
Mobile NetV1中“Group= C i n C_{in} Cin ”,所以分组卷积的计算方式为:
串联部分的计算方式为:
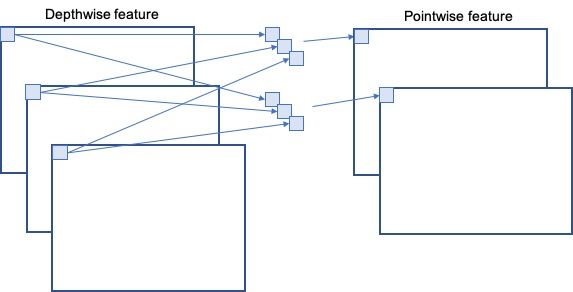
最后Mobile Net V1的“分组Depthwise+串联Pointwise”的计算方式为:
大家现在是不是就对深度可分离卷积(depthwise separable convolution)一目了然了呢?
模型网络结构
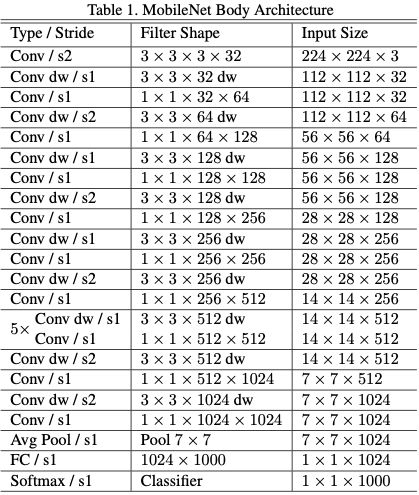
Mobile Net V1相较于其他普通卷积神经网络最大的变化就是使用了深度可分离卷积,也就是将曾经的1层卷积拆分为2步来做,并且BN层和激活层也都要做两遍:

Mobile Net V1的网络结构其实与VGG网络类似,都是一条主线叠加到底:
代码实现
深度可分离卷积既然这么好使,那在代码中该如何实现呢?其实很简单,人家早就把这个操作写进深度学习框架里了,让我们以Keras为例(torch里也有对应的):
SeparableConv2D:
keras.layers.SeparableConv2D(filters, kernel_size, strides=(1, 1), padding='valid',
data_format=None, dilation_rate=(1, 1), depth_multiplier=1, activation=None,
use_bias=True, depthwise_initializer='glorot_uniform', pointwise_initializer='glorot_uniform',
bias_initializer='zeros', depthwise_regularizer=None, pointwise_regularizer=None,
bias_regularizer=None, activity_regularizer=None, depthwise_constraint=None,
pointwise_constraint=None, bias_constraint=None)
SeparableConv2D这个api可以直接实现整个深度分离卷积过程,即分组+串联的全过程。
DepthwiseConv2D:
keras.layers.DepthwiseConv2D(kernel_size, strides=(1, 1), padding='valid',
depth_multiplier=1, data_format=None, dilation_rate=(1, 1), activation=None,
use_bias=True, depthwise_initializer='glorot_uniform', bias_initializer='zeros',
depthwise_regularizer=None, bias_regularizer=None, activity_regularizer=None,
depthwise_constraint=None, bias_constraint=None)
DepthwiseConv2D这个api则是单独计算分组(Depthwise)卷积部分。
Conv2D:
keras.layers.Conv2D(filters, kernel_size, strides=(1, 1), padding='valid',
data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True,
kernel_initializer='glorot_uniform', bias_initializer='zeros',
kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None,
kernel_constraint=None, bias_constraint=None)
卷积核为1的串联部分(Pointwise)则可直接用Conv2D来实现。
MobileNet:
keras.applications.mobilenet.MobileNet(input_shape=None, alpha=1.0,
depth_multiplier=1, dropout=1e-3, include_top=True, weights='imagenet',
input_tensor=None, pooling=None, classes=1000)
最好使的其实是这个,直接调取Keras中预训练好的MobileNet(V2也有),就可以啦。
附:
Keras中的预训练模型有这些:
- Xception
- VGG16
- VGG19
- ResNet, ResNetV2
- InceptionV3
- InceptionResNetV2
- MobileNet
- MobileNetV2
- DenseNet
- NASNet
未经同意,禁止转载!