卷积神经网络发展历程——轻量级网络模型(自己学习的笔记分享)
轻量级网络模型
SqueezeNet
2016
https://arxiv.org/abs/1602.07360
SqueezeNet 的目标就是在保持和 AlexNet 同样的准确度上,参数比它少 50 倍,模型文件可比它小510倍(AlexNet 共有6千万个参数)
模型压缩使用了三个策略:
-
将3 * 3卷积替换成1 * 1卷积:通过这一步,一个卷积操作的参数数量减少了9倍;
-
减少3 * 3卷积的通道数:一个3 * 3卷积的计算量是3 * 3 * M * N(M、N分别是输入特征图和输出特征图的通道数),作者希望将M、N减小以减少参数数量;
-
将下采样后置:作者认为大的特征图含有更多的信息,因此将下采样往分类层移动。(这样虽然会提升网络的精度,但是会增加网络的计算量)
Fire块:
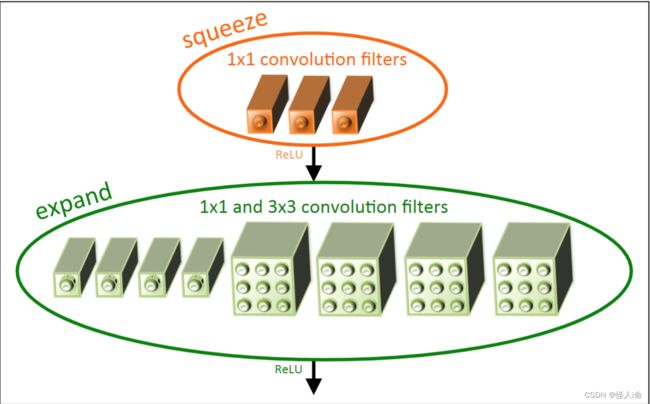

SqueezeNet开创了模型压缩的方向。
SqueezeNet通过更深的深度置换更少的参数数量虽然能减少网络的参数,但是其丧失了网络的并行能力,时间反而会更长。50倍的参数主要在于AlexNet的全连接层,和SqueezeNet设计关系不大,0.5MB的模型主要得益于Deep Compression。
ENet
2016
https://arxiv.org/pdf/1606.02147.pdf
相比SegNet(2016,https://arxiv.org/abs/1511.00561,提出基于索引的上池化进行上采样),速度提升18倍,计算量减少75倍,参数量减少79倍。
ENet中Encoder > Decoder(在不影响精度的情况下尽可能缩小网络体积,减少参数。作者认为编码结构用于提取深度特征,并且用于操作更小的解析度,而解码结构仅仅用于上采样编码的输出,仅用于微调边缘细节,所以并不需要特别深)。
initial block:压缩图像,特征提取,去除冗余信息。
特征解析度:
对图像进行连续的下采样会造成图像解析度的下降,使得空间信息损失,同时需要对应连续的上采样,将会增大模型尺寸和计算成本。针对这个问题,FCN网络提出了跳跃结构,即不同卷积层次的特征图都用于最后的上采样,结合了深层语义信息和浅层边缘细节信息;SegNet提出了池化索引方法,即每次池化时记录池化结果的位置,在上采样时根据池化结果和池化索引进行上池化操作;ENet使用了SegNet的池化索引方法,因为它不需要保存整个池化前特征图,而只需要保存池化索引,可以极大减少计算量。
提前下采样:
ENet在一开始就进行了两次下采样,图像解析度降了4倍,大大的减少了计算量。因为输入的图像本身就是解析度过高,只要下采样后图像的解析度仍然大于等于标签的解析度,理论上就不会产生什么影响。
非对称卷积:
每一个nxn的卷积核都可以被分解为nx1和1xn的两层卷积核,在本文中,作者使用了n=5的非对称卷积,在参数量上,5x5的非对称卷积仅仅比3x3的常规卷积多了一个参数,但是它们的感受野扩大了一倍,并且在网络中增加了函数的多样性,减小过拟合。
正则化:
使用了空间Dropout,而不是普通的Dropout。


ERFNet
2017
http://www.robesafe.uah.es/personal/eduardo.romera/pdfs/Romera17tits.pdf

提出了一个新的层:使用残差连接和分解卷积来保持高效和准确。
Factorized Residual Layers:
![]()
使用一维因式分解来加速和降低参数量,称为non-bottleneck-1D。


SeNet
2017
https://arxiv.org/abs/1709.01507
SeNet主要由两部分组成:
- Squeeze部分。将H * W * C的特征图压缩为1 * 1 * C (全局平均池化实现)。这样能够得到全局的感受野。
- Excitation部分。在1 * 1 * C之后加入FC层,对每个通道的重要性进行预测,得到不同通道的重要性大小。(特征通道之间的相关性)
- 然后将激发的输出通过乘法逐通道的加权到先前的特征上,完成在通道维度上的对原始特征的重标定。

作用在inception块中:

通过两个FC层来构建通道间的相关性。论文中r = 16 ,先将特征维度降低到输入的1/16,再经过ReLU激活后接上一个FC层,回到输入的维度,这样做比直接用一个FC层的好处在于:
1)具有更多的非线性,可以更好的拟合通道间复杂的相关性;
2)减少了参数量和计算量。
最后通过Sigmoid进行归一化,再通过Scale操作将权重加权到每个通道特征上。
作用在resnet块中:

SeNet很方便的集成到现有的网络中,提升网络性能,并且代价很小。
Xception
2017
https://arxiv.org/abs/1610.02357
极致的Inception(Extream Inception),并不是真正意义上的轻量化模型
将通道相关性和空间相关性分开处理,采用depthwise separable convolution替换Inception v3中的卷积操作
Xception模块:
Conv(1*1) + BN + ReLU + Depthconv(3*3) + BN + ReLU
depthwise separable convolution
Depthconv(3*3) + BN + Conv(1*1)+ BN + ReLU
再加上residual connects

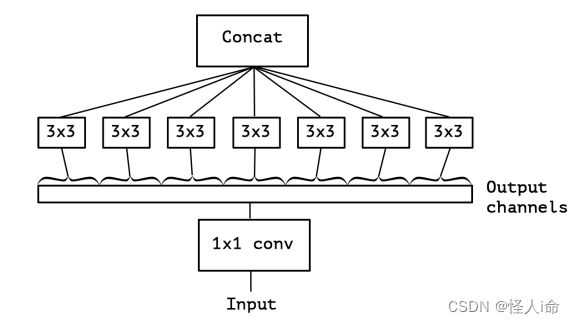
ShuffleNet
ShuffleNet V1
2017
https://arxiv.org/abs/1707.01083
特点:
pointwise group convolution
channel shuffle(消除原来组卷积中存在的副作用:阻碍了信息在通道组之间的信息流动。channel shuffle 可促进通道间信息的融合)
能够保持精度的同时减少计算成本。
Xception和ResNeXt将深度可分离卷积或组卷积引入构建的block中,有效的在表示能力和计算消耗之间折中,但是并没有充分考虑1x1的逐点卷积。(逐点卷积需要较大的计算量)所以对1x1卷积使用组卷积。


-
shuffle group convolution = group convolution + channel shuffle
-
pointwise group convolution = 1x1 convolution + group convolution
-
depthwise separable convolution = depthwise convolution + pointwise convolution
文中提到两次,对于小型网络,多多使用通道,会比较好,所以可以考虑提升通道效率这个点。
ShuffleNet V2
2018
https://arxiv.org/pdf/1807.11164.pdf
提出了四种有效的网络设计原则:
G1) Equal channel width minimizes memory access cost (MAC).(相等的通道宽度使内存访问成本最小化)
G2) Excessive group convolution increases MAC. (过度的组卷积会增加 MAC)
G3) Network fragmentation reduces degree of parallelism.(网络碎片降低了并行度)
G4) Element-wise operations are non-negligible.(逐元素操作是不可忽略的)
ShuffleNet V1引用的pointwise group convolution增加了MAC,违反了G2;MobileNet v2 利用了反转瓶颈结构,违反了 G1;在通道数较多的扩展层使用 ReLU和深度卷积不符合G4;NAS 网络生成的结构碎片化很严重,不符合G3。
ShuffleNet V2引入通道分割
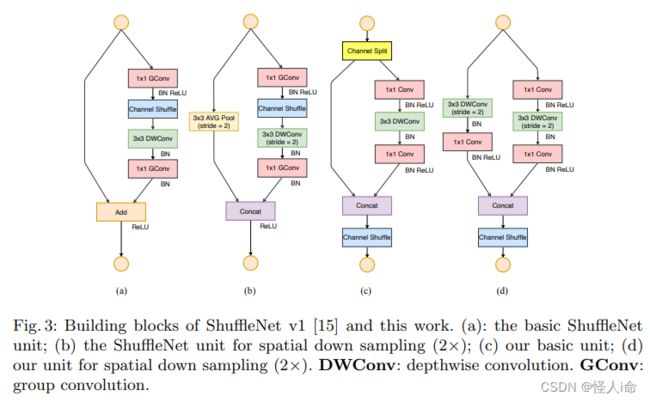
高效而且精度也高的理由:
一、高效的卷积block结构能够使用更多的特征通道,网络容量较大。
二、c’ = c/2时,有一半的特征通图直接经过当前卷积块并进入下一个块。
两个 block 之间特征复用的数量是随着两个块之间的距离变大而呈指数级衰减的。
MobileNet
MobileNet V1
2017
https://arxiv.org/abs/1704.04861
深度可分离卷积
https://blog.csdn.net/evergreenswj/article/details/92764387
https://towardsdatascience.com/a-basic-introduction-to-separable-convolutions-b99ec3102728


MobileNet V2
2018
https://openaccess.thecvf.com/content_cvpr_2018/papers/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.pdf
特点:
-
Inverted Residuals 倒残差结构
-
Linear Bottlenecks 最后一层采用线性层
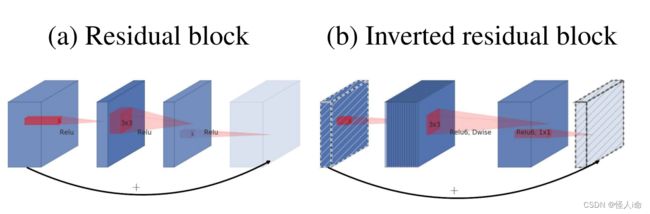
ResNet残差结构是先用1*1的卷积降维,再升维(两头大,中间小);MobileNet V2是先升维,再降维(中间大,两头小)。(是因为 MobileNetV2 将residuals block 的 bottleneck 替换为了 Depthwise Convolutions,因其参数少,提取的特征就会相对的少,如果再进行压缩的话,能提取的特征就更少了,因此MobileNetV2 就执行了扩张→卷积特征提取→压缩的过程。)
还采用了新的激活函数ReLU6,使模型在低精度计算下具有更强的鲁棒性;
在最后一层的卷积层中,采用线性的激活函数,而不是ReLU。
一个解释:ReLU激活函数对于低维的信息可能会造成比较大的损失,而对于高维的特征信息造成的损失很小。由于倒残差结构输出的是一个低维的特征信息,所以使用一个线性的激活函数避免特征损失。(为了避免Relu对特征的破坏 )

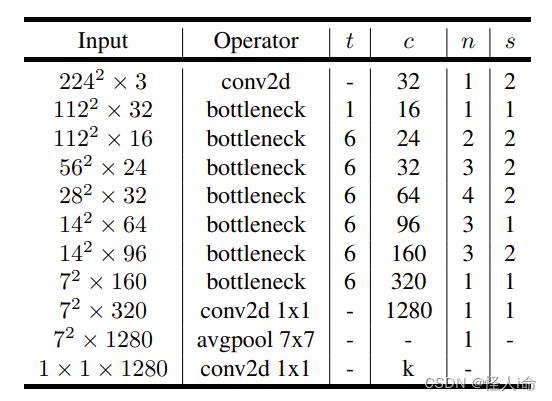
https://blog.csdn.net/u011995719/article/details/79135818?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-2-79135818-blog-123321670.pc_relevant_multi_platform_whitelistv1&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-2-79135818-blog-123321670.pc_relevant_multi_platform_whitelistv1&utm_relevant_index=3
MobileNet V3
2019
https://arxiv.org/abs/1905.02244
使用 AutoML 为给定的问题找到最佳的神经网络架构。
MobileNetV3 利用了两种 AutoML 技术:
MnasNet:一种自动移动神经体系结构搜索(MNAS)方法
NetAdapt:适用于移动应用程序的平台感知型算法
NAS执行模块级搜索,NetAdapt执行局部搜索。
MobileNetV3 首先使用 MnasNet 进行粗略结构的搜索,然后使用强化学习从一组离散的选择中选择最优配置。之后,MobileNetV3 再使用 NetAdapt 对体系结构进行微调,这体现了 NetAdapt 的补充功能,它能够以较小的降幅对未充分利用的激活通道进行调整。
引入SeNet的结构,将其作为搜索空间的一部分。

修改尾部结构:
为了减少计算量,去掉了纺锤型卷积中的3x3以及1x1卷积,将avg pooling之前的1x1卷积层放在其后面,先利用avg pooling将特征图大小由7x7降到了1x1,降到1x1后,然后再利用1x1提高维度,这样就减少了7x7=49倍的计算量。
精度并没有得到损失,降低了大约15ms的速度。
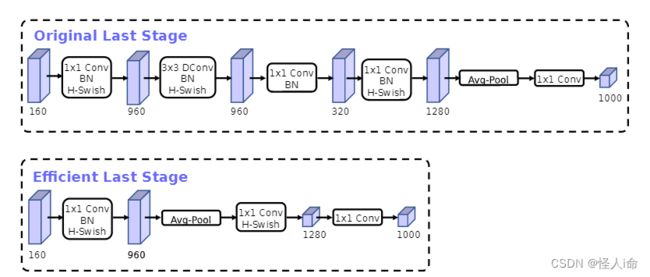
在MobileNet V2中,头部卷积核通道数是32,改成16,保证精度的前提下,降低了3ms的速度。
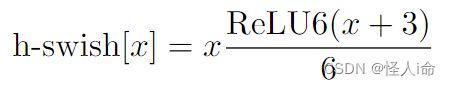
激活函数。(用于轻量化网络的激活函数)
BiSeNet
BiSeNet V1
2018
https://arxiv.org/abs/1808.00897
网络包含两个主干分支:Spatial Path 和 Context Path。
(SP用于保留语义信息生成较高分辨率的特征图;CP采用快速下采样,用于获取充足的感受野)
设计了两个特殊的特征融合模块:Feature Fusion Module 和 Attention Refinement Module。

(b):U型网络通过融合backbone不同层次的特征,在U型结构中逐渐增加空间分辨率,保留更多的细节特征。有两个缺点:
- 高分辨率特征图计算量非常大,影响计算速度;
- 由于resize或者减少网络通道而丢失的空间信息无法通过引入浅层而轻易复原。

ARM:类似SE模块,优化特征信息。
FFM:融合两个路径的特征信息。先将两个部分的特征图通过concatenate方式叠加,然后通过类似SE模块的方式计算加权特征,起到特征选择和结合的作用。
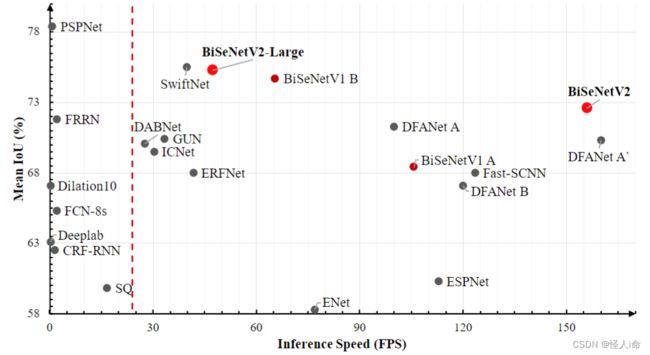
BiSeNet V2
2020
https://arxiv.org/abs/2004.02147
Detail Branch 细节分支:负责空间细节。(关注底层细节,大的空间尺寸、低通道)
Semantic Branch 语义分支:负责捕获高级语义。(高级语义需要较大的感受野)
Aggregation Layer 聚合层:DB和SB的特征表示是互补的,需要一个聚合层来合并。(该网络采用了双向聚合的方法Bilateral Guided Aggregation Layer)

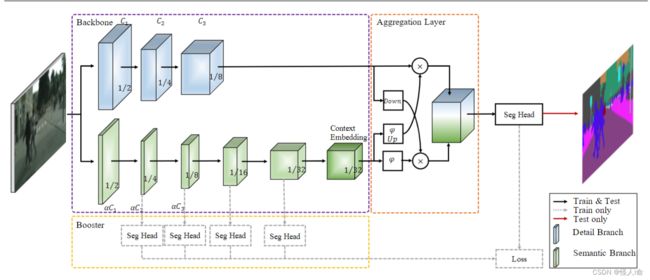
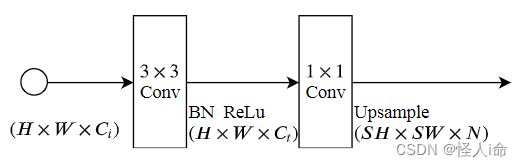
Stem Block:语义分支第一阶段采用Stem块,使用两种不同的下采样方式来缩小特征图,然后再串联输出。该结构具有高效的计算成本和有效的特征表达能力。
Context Embedding Block:上下文嵌入块使用全局平均池化和残差连接,高效的嵌入全局上下文信息。(类似SE模块)

Gather-and-Expansion Layer:
Bilateral Guided Aggregation Layer:
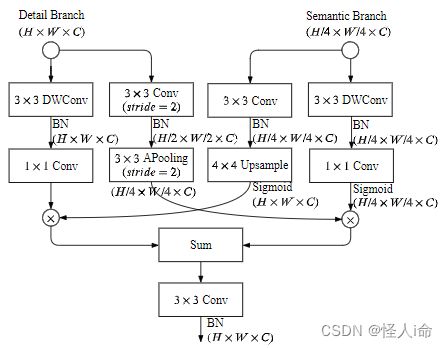
还提出了一种增强训练策略。在训练阶段增强特征表示,在推理阶段丢弃。
DFANet
2019
https://arxiv.org/pdf/1904.02216v1.pdf

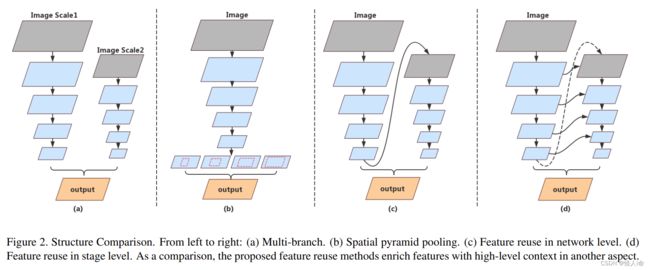
提出了一个新的具有多次连接结构的语义分割编码模块。
(a)缺乏对由并行分支结合而成的高级特征的处理,并行分支间缺乏信息交流,高分辨率图像上额外添加分支对速度有影响;
(b)SPP模块处理高级特征的方法非常耗时。
(c)随着整个结构深度的增加,高维度特征和感受野通常会出现精度损失。
(d)所有的子网络有相似的结构,stage-level方法通过concat相同分辨率的层精炼产生多阶段的上下文信息。

轻量级主干:修改Xception网络作为主干网络,在其尾部加入了全连接的注意模块。
子网络聚合:将前一个主干的高级特征映射上采样到下一个主干的输入,以细化预测结果。
子阶段聚合:相同深度的子网络中进行不同阶段的融合。前一个子网络中某一阶段的输出贡献给下一个子网络相应阶段位置的输入。
encoder由3个Xception主干的聚合,由子网络聚合和子阶段聚合组成。
EfficientNet
2020
https://arxiv.org/abs/1905.11946
通过NAS技术搜索网络的图像输入分辨率resolution,网络的深度depth以及宽度width。本文通过同时增加这三个参数来提升网络的性能。

组合缩放系数:
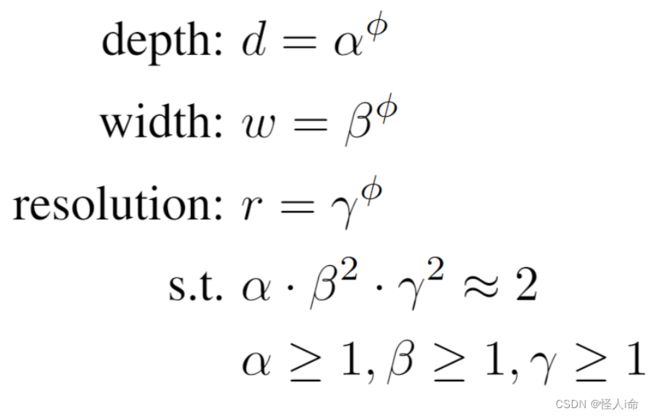
SFNet
2020
https://arxiv.org/pdf/2002.10120.pdf添加链接描述

-
在场景解析领域引入了语义流的概念,并提出了一种新的基于流的对齐模块(FAM),用于学习相邻级别的特征映射之间的语义流,并更有效地将高级特征广播到高分辨率特征;
-
将FAM插入特征金字塔框架中,并构建一个称为SFNet的特征金字塔对齐网络,用于快速准确的场景解析。

Flow Alignment Module:结合转换后的高分辨率特征图和低分辨率特征图来生成语义流场,用于将低分辨率特征图warp为高分辨率特征图。
Warp Procedure:高分辨率特征图的值是低分辨率特征图中相邻像素的双线性插值,其中邻域是根据学习的语义流场定义。(利用语义流指导上采样)
(如何在不增加计算量的情况下,更加精细化的上采样)
上下文模块:在场景解析中捕获远程上下文信息起着重要的作用。本文采用PPM(源自PSPNet)。
具有对齐模块的FPN:编码器得到特征图后送入解码器阶段,并将对齐的特征金字塔用于最终场景解析语义分割任务。在FPN的自上而下的路径中用FAM替换正常的双线性插值实现上采样。
https://mp.weixin.qq.com/s?__biz=MzUxNjcxMjQxNg==&mid=2247497693&idx=4&sn=afa946b8dec3e827a3c1f291b0dfcc89&chksm=f9a18552ced60c44bbe451b71e2a8d305e09e4e70d8a276b9026213a2eccddaeb858a3b58871&scene=21#wechat_redirect