【三维目标检测】3DSSD(二)
数据和源码请参考上一篇博文:【三维目标检测】3DSSD(一)_Coding的叶子的博客-CSDN博客。
3DSSD三维目标检测模型发表在CVPR2020《3DSSD: Point-based 3D Single Stage Object Detector》。目前,基于体素的 3D 单级检测器已经有很多种,而基于点的单级检测方法仍处于探索阶段。3DSSD是一种轻量级且有效的基于点的 3D 单级目标检测器,在精度和效率之间取得了良好的平衡。所有现有的基于点的方法中必不可少的所有上采样层和refine操作都被放弃了,以减少大量的计算成本。3DSSD在下采样过程中提出了一种新的融合采样策略,以使对较少代表性点的检测变得可行。3DSSD大大优于现有的基于体素的单阶段方法,并且具有与两阶段基于点的方法相当的性能,推理速度超过 25 FPS,比类似的目标检测方法要快 2 倍左右。

1 3DSSD模型总体过程

2 主要模块解析
2.1 最远点采样FPS
详见博文:【最远点采样FPS】点云采样方式(一) — 最远点采样_Coding的叶子的博客-CSDN博客_点云最远点采样。
2.2 主干网络 backbone
主干网络采用PointNet2SAMSG来进行特征提取,模型结构如下图所示,主要代码路径: mmdet3d/pointnet_modules/point_sa_module.py。

输入点云特征,Nx4,N=16384。
SA(Set Abstract)层:SA层相当于二维图像的卷积层,逐层进行特征提取,使得特征图尺寸不断缩小,特征维度不断增加。SA层的详细介绍可以参考之前PointNet++博文:【三维目标分类】PointNet++详解(一)_Coding的叶子的博客-CSDN博客_pointnet++目标识别。
MSG:在SA层中,会对最远点采样得到的点的周围点进行分组采样。例如A是最远点采样中的一个点,分组会对其周围M个点进行分组,然后采用PointNet进行特征提取,将提取到的特征作为A的特征。MSG详细介绍请参考博文:【三维深度学习】PointNet++(三):多尺度分组MSG详解_Coding的叶子的博客-CSDN博客_多尺度组合分组。
(1)将16384x4维输入点云数据转换成16384x3坐标xyz和16384x1特征features。
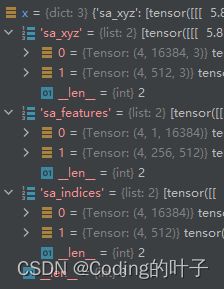
(2)SA1(第一层SA):采样点数4096,采样方式D-FPS(坐标距离最远点采样),MSG半径分别为0.2、0.4、0.8。以半径为0.2分组且分组点数为32时,得到特征维度为1x4096x32,进而与xyz坐标拼接得到新的特征维度为4x4096x32 features。经过连续MLP层Conv2d(4, 16)、Conv2d(16, 16)、Conv2d(16,32)后features特征维度为32x4096x32,最后采用最大池化得到特征维度为32x4096。类似地,MSG分组半径为0.4和0.8时得到的特征维度分别为32x4096和64x4096。将三种尺寸的特征拼接得到128x4096新特征features,进一步经过Conv2d(128, 64)卷积将features维度转变为64x4096。因此,上图中N1=4096、C1=64。
(3) SA2(第二层SA):采样点数1024,采样方式FS,即D-FPS(坐标距离最远点采样)和F-FPS(特征距离最远点采样)分别采样512个点,其中D-FPS输入为坐标,维度为4096x3;F-FPS的输入分别为坐标与特征拼接后的新特征,维度为4096x67。MSG半径分别为0.4、0.8、1.6。以半径为0.4分组且分组点数为32时,得到特征维度为64x1024x32,进而与xyz坐标拼接得到新的特征维度为67x4096x32 features。经过连续MLP层Conv2d(67, 64)、Conv2d(64, 64)、Conv2d(64,128)后features特征维度为128x1024x32,最后采用最大池化得到特征维度为128x1024。类似地,MSG分组半径为0.8和1.6时得到的特征维度分别为128x1024和128x1024。将三种尺寸的特征拼接得到384x1024新特征features,进一步经过Conv2d(384, 128)卷积将features维度转变为128x1024。因此,上图中N2=1024、C2=128。
(4)SA3(第三层SA):采样点数512,即D-FPS(坐标距离最远点采样)和F-FPS(特征距离最远点采样)分别采样256个点。如上所述,(3)中输出特征1024x128,一半来源于D-FPS,一半来源于F-FPS。因此,将1024x128拆分为512x128和512x128,然后分别对应进行D-FPS和F-FPS。D-FPS输入为坐标,维度为512x3;F-FPS的输入分别为坐标与特征拼接后的新特征,维度为512x131。MSG半径分别为1.6、3.2、4.8。以半径为1.6分组且分组点数为32时,得到特征维度为128x512x32,进而与xyz坐标拼接得到新的特征维度为131x512x32 features。经过连续MLP层Conv2d(131, 128)、Conv2d(128, 128)、Conv2d(128, 256)后features特征维度为256x512x32,最后采用最大池化得到特征维度为256x512。类似地,MSG分组半径为0.8和1.6时得到的特征维度分别为256x512和256x512。将三种尺寸的特征拼接得到768x512新特征features,进一步经过Conv2d(768, 256)卷积将features维度转变为256x512。因此,上图中Nm=512、Cm=256。
主干网络最终输出如下图所示:
2.3 Candidate Generation Layer
Candidate Generation Layer这一部分主要是基于VoteNet得到投票中心点和特征。核心思想是,利用Backbone等网络提取关键点的特征,并用其中的一部分来进行投票,投票结果进一步用PointNet++ MSG SA层进行特征提取,最后利用该特征对检测框的种类和位置进行预测。

(1)生成投票点(generate vote_points from seed_points):主干网络backbone中得到512x3个采样点坐标和512x256特征features,选择其中前256个点的坐标和特征作为seed。Seed features 256x256经过Conv1d(256, 128)、Conv1d(128, 3)得到256x3,这个作为预测目标点相对于投票点的偏移,即图中的Shifts。偏移量加上投票点坐标即为预测的目标中心点坐标,即图中的Candidate Points 256x3。
# 1. generate vote_points from seed_points
vote_points, vote_features, vote_offset = self.vote_module(seed_points, seed_features)
results = dict(
seed_points=seed_points,
seed_indices=seed_indices,
vote_points=vote_points,
vote_features=vote_features,
vote_offset=vote_offset)(2)投票点特征聚合(aggregate vote_points):这一步骤是为了获取投票点的特征,采用的方式仍然是PointNet2SAMSG。输入为seed 512个种子点,采样256个点,但这256个点不再是通过最远点采样得到,而直接是预测的目标中心点。分别用两种不同的分组半径进行特征提取,提取后的特征维度分别为512x256和1024x256,然后拼接得到1536x256特征,对应上图中的Group、MLP和MaxPool操作。
# 2. aggregate vote_points
vote_aggregation_ret = self.vote_aggregation(**aggregation_inputs)
aggregated_points, features, aggregated_indices = vote_aggregation_ret
results['aggregated_points'] = aggregated_points
results['aggregated_features'] = features
results['aggregated_indices'] = aggregated_indices2.4 预测Head(Prediction Head)
(1)生成预测框和置信度得分:首先对上述1536x256特征采用卷积Conv1d(1536, 512)、Conv1d(512, 128)继续进行特征提取,得到128x256维特征。然后,利用分类卷积Conv1d(128, 1),得到256x1个分类预测置信度得分。由于该源码中仅对汽车Car这一个类别进行了预测,所以类别维度为1。采用位置卷积Conv1d(128, 128)、Conv1d(128, 30)得到256x30维度得到位置与猜测。
# 3. predict bbox and score
cls_predictions, reg_predictions = self.conv_pred(features)
BaseConvBboxHead(
(shared_convs): Sequential(
(layer0): ConvModule(
(conv): Conv1d(1536, 512, kernel_size=(1,), stride=(1,))
(bn): BatchNorm1d(512, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(layer1): ConvModule(
(conv): Conv1d(512, 128, kernel_size=(1,), stride=(1,))
(bn): BatchNorm1d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(cls_convs): Sequential(
(layer0): ConvModule(
(conv): Conv1d(128, 128, kernel_size=(1,), stride=(1,))
(bn): BatchNorm1d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(conv_cls): Conv1d(128, 1, kernel_size=(1,), stride=(1,))
(reg_convs): Sequential(
(layer0): ConvModule(
(conv): Conv1d(128, 128, kernel_size=(1,), stride=(1,))
(bn): BatchNorm1d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(conv_reg): Conv1d(128, 30, kernel_size=(1,), stride=(1,))
)(2)对置信度得分和位置进行decoder:
1)results['obj_scores']为(1)中置信度得分。
2)results['center_offset']为(1)中位置预测30个维度中的前3个,即目标中心位置坐标偏移。
3)results['center']为results['center_offset']坐标偏移加上Vote投票点坐标。
4)results['size']为目标三个维度的尺寸大小,即(1)中位置预测30个维度中的4-6个。
5)results['dir_class']为预测的12个目标方向分类,即(1)中位置预测30个维度中的7-18个。
6)results['dir_res']为预测的12个目标方向偏差,即(1)中位置预测30个维度中的19-30个。
# 4. decode predictions
decode_res = self.bbox_coder.split_pred(cls_predictions,
reg_predictions,
aggregated_points)2.5 损失函数
目标中心分类损失函数:CrossEntropyLoss
目标中心偏移损失函数:SmoothL1Loss
目标方向分类损失函数:CrossEntropyLoss
目标方向偏差损失函数:SmoothL1Loss
目标中心尺寸损失函数:SmoothL1Loss
目标位置顶点损失函数:SmoothL1Loss
Vote Offset损失函数:SmoothL1Loss
2.6 顶层结构
顶层结构主要包含以下三部分:
(1)特征提取:self.extract_feat,得到384x248x216特征,见2.5节。
(2)检测头:见2.4节。
(3)损失函数:见2.5节。
def forward_train(self, points, img_metas, gt_bboxes_3d, gt_labels_3d, pts_semantic_mask=None, pts_instance_mask=None, gt_bboxes_ignore=None):
points_cat = torch.stack(points)
x = self.extract_feat(points_cat)
bbox_preds = self.bbox_head(x, self.train_cfg.sample_mod)
loss_inputs = (points, gt_bboxes_3d, gt_labels_3d, pts_semantic_mask, pts_instance_mask, img_metas)
losses = self.bbox_head.loss(bbox_preds, *loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
return losses
def extract_feat(self, points, img_metas=None):
x = self.backbone(points)
if self.with_neck:
x = self.neck(x)
return x3 训练命令
python tools/train.py configs/3dssd/3dssd_4x4_kitti-3d-car.py4 运行结果

5 【python三维深度学习】python三维点云从基础到深度学习_Coding的叶子的博客-CSDN博客_python点云分割
更多三维、二维感知算法和金融量化分析算法请关注“乐乐感知学堂”微信公众号,并将持续进行更新。