腾讯SkillNet|NLU任务全能网络,对Pathways架构的初步尝试
卷友们好,我是rumor。
21年10月的时候,谷歌大佬Jeff Dean提出了下一代AI架构的Pathways概念[1],旨在通过一个大模型完成各种不同的任务。对于较早关注AI领域的同行们来说,这其实类似17年就提出的MoE(Mixture-of-Experts)概念。不管现在预训练大模型效果多好,始终存在着三个重要问题:
目前的模型都只能处理单一任务
目前的模型大部分只专注一种感知输入,比如文本、图像
目前的模型都是dense的,已经有一些研究显示,很多参数都是无用的,比如12个注意力头去掉几个影响并不大。这就导致了计算的效率低下
其实我个人认为,前两个问题大模型都是可以解决的,真正的瓶颈是第三点。现在大模型虽然效果不错,但训练、落地对于普通团队都很不友好,要达到真正的应用,必须「瘦身」,目前有三种方法:
量化:把FP32转换成FP16、INT8进行计算,而这种方法的天花板也比较明显(总不能压缩到Bool吧)
蒸馏:前两年很火的方法,但压缩到小的dense模型,由于参数量的限制,也存在效果天花板,同时也存在无效的参数
剪枝:去掉一些层、神经元或者权重。前几年稀疏计算的底层支持不好,而目前排除下来,这反倒是最有可能的方法
Pathways给出的概念则更模拟人脑的逻辑,用不同部分负责不同功能。在训练中,模型动态的学习如何用特定的子网络去解决特定任务,这样在推理时只需要用部分网络就可以处理任务了。 如下图所示,这种做法在保持了整个模型容量(参数量)的同时,极大地缩短了预测时间。
往更远来看,Pathways给持续学习提供了一种可能性,当有新的任务时,可能只需要在现有模型上增加一些网络就可以了,不会影响到以前的网络参数,同时多任务学习下也能提升整个网络的泛化能力。
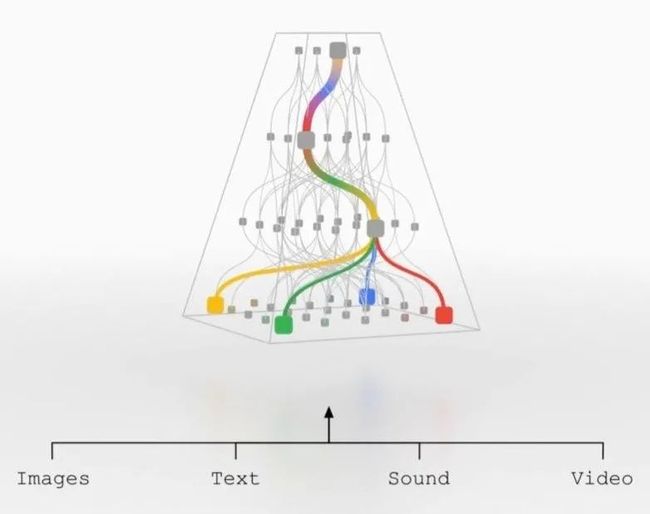
SkillNet
遗憾的是,Jeff Dean并没有公布更详细的方案,但最近腾讯AI Lab在这个概念的启发下进行了一些尝试,让我这个坐等群众来和大家一起尝尝鲜。
One Model, Multiple Tasks: Pathways for Natural Language Understanding
https://arxiv.org/abs/2203.03312SkillNet的做法是,给每个子网络定义一个Skill,在预测时只激活和任务相对的Skill:
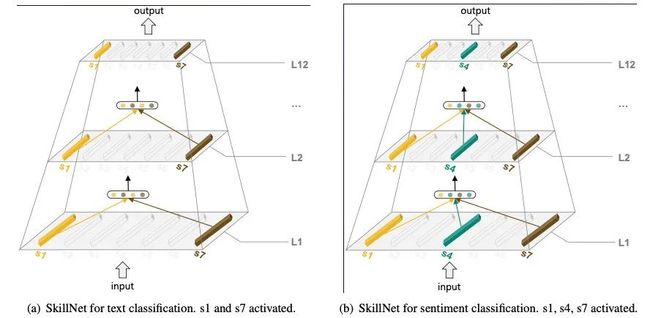
添加的方式参考了Switch Transformer,直接加到FFN层。如果激活了多个Skill,就使用平均池化进行融合:

在训练时,每次从一个任务中采样一个batch,根据任务目标优化对应的Skill。由于不同任务的样本数量不一样,在采样时制定了一个超参数,来控制采样的分布,实验证明直接遵从数据本事的分布效果最好,即数据多的任务多采,少的少采。
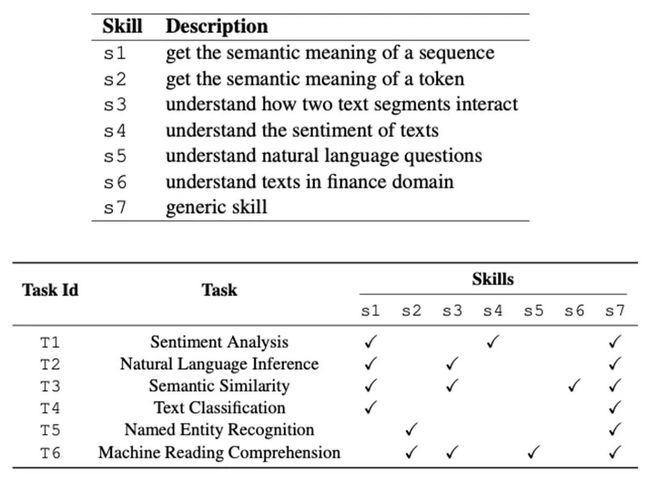
同时,SkillNet的网络结构是支持预训练的,比如MLM任务可以训练S2、S7,NSP任务可以训练S1、S3、S7。
SkillNet在6个中文数据集上做了实验,结果显示整体效果要好于纯精调,同时也超过了dense模型Multi-task和MoE的设置:
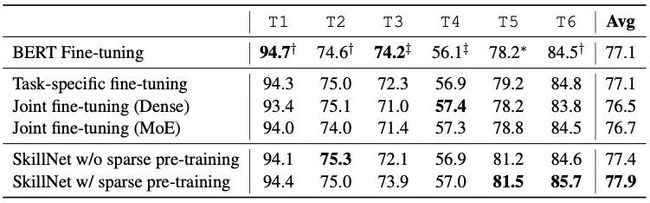
与多任务学习相比,SkillNet效率更高,同时是在skill层面进行定义,再通过skill的结合解决不同任务。
与MoE相比,SkillNet具有更强的可解释性,同时也不需要复杂的路由策略去选取合适的Expert。
总结
SkillNet是对Pathways的一个初步尝试,这种结构一个很大优点是Skill的复用和新增,在增加一个新任务时,可以直接复用以前训练好的模块,也可以新增一个与任务更相关的Skill。我之前一直纠结多任务的一个点是,对于模型来说泛化性和专业性是有些矛盾的,当我们想做一个通用的、完美的模型时,引入另外一个目标可能对其他目标效果产生影响。而SkillNet的做法就是,把目标进行拆解,解耦成一些「底层能力」,从而避免多任务的相互影响。
不过个人觉得这样的解藕还是有些硬,且需要不少的人工介入(把task拆解为合适的skill),对比下来让模型自动解藕的MoE还是更「智能」一些。
另外还有不少值得探索的地方,比如是否可以动态选择更少的attention head、以及这种架构下是否有除了Transformer外更好的模块等。SkillNet是基于BERT-base做的,往这个方向探索下去,也衍生了一条比大模型少些卷的赛道。
再往后看,神经网络离人脑的模式还有很大距离,比如MindSpore的金雪锋大佬提到的[2],人脑中很重要的一个特征是局部BP,只有某个module进行单独的学习优化,而Pathways架构虽然拆分出了module,本质还是全局BP。
参考资料
[1]
https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/: Pathways
[2]https://www.zhihu.com/question/495386434/answer/2200453530: 如何看待Google下一代人工智能架构Pathways?
欢迎对NLP感兴趣的朋友加入我们的「NLP卷王养成」群,一起学习讨论~
扫码添加微信备注「NLP」即可⬇️


大家好我是rumor
一个热爱技术,有一点点幽默的妹子
欢迎关注我
带你学习带你肝
一起在人工智能时代旋转跳跃眨巴眼
「今天你BP了吗?」