Non-Local Neural Networks
一.摘要
卷积操作和循环神经元操作都是建立了一个处理一个局部范围信息的一个过程.本文呈现了一种非局部(non-local)操作,可以作为用于捕获长范围依赖的一类模块.本文提出的non-local操作在计算feature map上某点的响应值时就是通过对feature map上所有点与当前点的关系加权求和的一个结果.本文提出的non-local模块可以插入到许多计算机视觉网络结构中并取得不错的效果.
二.Non-Local Neural Networks
接下来首先给出non-local操作的定义,然后给出几个具体的non-local的实例.
2.1公式
定义通用的non-local操作如下公式所示:
![]()
对于上式子non-local操作的通用定义有如下解释:
(1) 表示non-local操作的输出,与输入形状相同;
表示non-local操作的输出,与输入形状相同;
(2) 表示non-local操作的输入,与输出形状相同;
表示non-local操作的输入,与输出形状相同;
(3) 是输出或输入上的某个点的坐标(可以是空间坐标,时间坐标,或时空坐标);
是输出或输入上的某个点的坐标(可以是空间坐标,时间坐标,或时空坐标);
(4)位置的响应值(non-local操作的的输出)就是 ;
;
(5) 依次枚举(遍历)上或上的所有点的坐标位置,
依次枚举(遍历)上或上的所有点的坐标位置, 表示输入数据上位置的值;
表示输入数据上位置的值;
(6)函数![]() 计算输入数据的位置和位置的两个量之间的关系,例如相似度;
计算输入数据的位置和位置的两个量之间的关系,例如相似度;
(7)函数![]() 计算输入数据的位置的一个表示,在这里可以理解为
计算输入数据的位置的一个表示,在这里可以理解为![]() 的一个系数或权重;
的一个系数或权重;
(8)non-local的位置最终响应结果就是对每个位置相对于当前位置的关系![]() 进行加权
进行加权![]() 求和,最后通过归一化因子
求和,最后通过归一化因子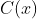 进行归一化操作.
进行归一化操作.
通过定义可以看出,非局部(non-local)操作在计算点的响应值时得益于考虑了所有位置关于当前位置的关系,因而叫做非局部操作.而普通卷积操作之考虑了局部的一些相邻点,以及循环神经网络中某些点的计算也只考虑了当前时刻和上一时刻.
上式中的non-local操作与全连接操作是不同的,non-local操作是对所有位置对于当前计算位置的相关性![]() 进行加权求和,而全连接并没有考虑不同神经元之间的相关性,只是简单的对不同神经元的输出进行了加权求和.换言之就是说,全连接层并没有上式non-local操作中计算不同神经元输出之间关系的函数
进行加权求和,而全连接并没有考虑不同神经元之间的相关性,只是简单的对不同神经元的输出进行了加权求和.换言之就是说,全连接层并没有上式non-local操作中计算不同神经元输出之间关系的函数 .进一步地,上式的non-local操作支持多种尺寸的输入并输出相同的尺寸,并且保留了输入输出的位置对应关系(例如在位置,输入
.进一步地,上式的non-local操作支持多种尺寸的输入并输出相同的尺寸,并且保留了输入输出的位置对应关系(例如在位置,输入 对应输出的),但全连接层只能支持固定尺寸的输入,并且输出失去了与输入的位置对应关系.
对应输出的),但全连接层只能支持固定尺寸的输入,并且输出失去了与输入的位置对应关系.
non-local操作可以灵活并容易的应用于卷积/循环神经网络.并且non-local操作可以使用在网络的浅层,不像全连接层只能应用于网络末端.这就能够建立更加丰富的层级,从而结合局部和非局部信息.
2.2实例
尝试了多种不同的函数和 函数的定义,通过实验发现对不同的和的选择,non-local操作的结果并没有明显变化,表明了通用的non-local操作是模型提升的主要原因.
函数的定义,通过实验发现对不同的和的选择,non-local操作的结果并没有明显变化,表明了通用的non-local操作是模型提升的主要原因.
为了简化,本文将函数简单的构造为线性形式:![]() ,其中
,其中![]() 为可学习参数,在实施过程中针对空间问题(2维图片)则通过1*1的卷积操作进行实现,针对时空问题(3维,例如视频)采用1*1*1卷积进行实现.
为可学习参数,在实施过程中针对空间问题(2维图片)则通过1*1的卷积操作进行实现,针对时空问题(3维,例如视频)采用1*1*1卷积进行实现.
接下来具体讨论不同形式的函数:
高斯
将函数定义为高斯函数,形式如下式:
![]()
这里![]() 表示与的点积相似度(近似余弦相似度).当然点积也可以用与的欧式距离替代,但是在现在已有的深度学习平台中,点积在实施方面更加友好.归一化因子被定义为
表示与的点积相似度(近似余弦相似度).当然点积也可以用与的欧式距离替代,但是在现在已有的深度学习平台中,点积在实施方面更加友好.归一化因子被定义为![]() .
.
编码后高斯
对于上面的高斯函数进行进一步的扩展,将原始输入与首先进行编码,的到编码后的结果![]() 与
与![]() ,之后对编码后的结果求取高斯函数结果,公式如下所示:
,之后对编码后的结果求取高斯函数结果,公式如下所示:
![]()
与 的编码函数就是简单的线性操作,其中![]() ,
,![]() .归一化因子的定义与高斯函数形式相同为
.归一化因子的定义与高斯函数形式相同为![]() .
.
以上两种 函数定义方式中归一化因子形式相同,带回到non-local操作通用定义公式中发现,本质上就是一个softmax操作,non-local操作的定义便成为了如下式所示:

其中![]() 本质上就是softmax操作,可以记做
本质上就是softmax操作,可以记做![]() ,其取值范围为0到1之间.则
,其取值范围为0到1之间.则![]() .所以也就能够发现,本质上就是通过对所有
.所以也就能够发现,本质上就是通过对所有![]() 进行了一个注意力操作(加权求和)后得到了最终的输出,这个注意力强度取决与当前被计算位置与所遍历到的位置的关系强度,也就是前面 函数的计算结果大小.这种注意力的思想在之前的研究self-attention中已经提出了,因此自注意力可以形式为如下所示:
进行了一个注意力操作(加权求和)后得到了最终的输出,这个注意力强度取决与当前被计算位置与所遍历到的位置的关系强度,也就是前面 函数的计算结果大小.这种注意力的思想在之前的研究self-attention中已经提出了,因此自注意力可以形式为如下所示:
![]()
但需要注意,这并不是本文提出的non-local操作,只是自注意力操作,因为其缺少了求和那一步(在上式子中最左端加入求和符号便是本文的non-local操作).因此本文通过将自注意力和非局部均值方法想结合提出了本文的non-local操作.
随后本文发现由softmax操作进行attention操作并非是必须的,接下来给出2种non-local操作的可替换版本.
点积
函数可定义为点积相似度.如下式所示:
![]()
这里采用对输入编码后的结果的点积相似度.与前两种方式不同的是,这里归一化因子![]() ,
, 表示non-local操作的输入的位置数目,而非
表示non-local操作的输入的位置数目,而非![]() 的求和结果,所以这也就取消了softmax操作,同时简化了梯度的计算.
的求和结果,所以这也就取消了softmax操作,同时简化了梯度的计算.
拼接
函数还可定义为输入的拼接形式,如下式所示:
![]()
式中![]() 表示拼接操作,
表示拼接操作,![]() 是一个权重向量,对拼接后的结果向量进行线性计算,然后的到一个标量.这里的归一化因子
是一个权重向量,对拼接后的结果向量进行线性计算,然后的到一个标量.这里的归一化因子![]() 和上面点积的形式一样.最后将线性计算后的结果进行ReLU激活函数激活.
和上面点积的形式一样.最后将线性计算后的结果进行ReLU激活函数激活.
2.3Non-Local模块

上图为一个时空(3维数据,例如视频流)的non-local模块整体架构图,其中non-local操作选用的函数是编码后高斯的形式,上图中 表示矩阵相乘,
表示矩阵相乘, 表示对应元素相加,蓝色底色的框表示1*1*1的卷积操作,上图中绿色箭头表示reshape操作.
表示对应元素相加,蓝色底色的框表示1*1*1的卷积操作,上图中绿色箭头表示reshape操作. ,
, 以及表示对输入数据的编码操作(空间映射).上图中从输入到两个计算结束则完成了前文定义的non-local操作.
以及表示对输入数据的编码操作(空间映射).上图中从输入到两个计算结束则完成了前文定义的non-local操作.
这部分将介绍non-local模块的构造,non-local模块将前文提到的non-local操作包括在内,non-local模块能够应用于许多当前的网络结构中.本文定义non-local模块的数学表示如下所示:
![]()
式子中表示前文所说的non-local操作的输出结果,"![]() "表示残差连接,残差连接的形式可以允许在不改变被插入网络的主体(初始网络计算流程)的基础上插入本文提出的non-local模块,例如上式中将
"表示残差连接,残差连接的形式可以允许在不改变被插入网络的主体(初始网络计算流程)的基础上插入本文提出的non-local模块,例如上式中将![]() 改为0就是未被插入non-local模块的原网络,模型会自主学习
改为0就是未被插入non-local模块的原网络,模型会自主学习![]() 去判断non-local操作的重要性,
去判断non-local操作的重要性,![]() 就是2.3开始流程图中最顶端的1*1*1的卷积核.整个Non-Local模块结构如2.3开始的图.
就是2.3开始流程图中最顶端的1*1*1的卷积核.整个Non-Local模块结构如2.3开始的图.
当输入特征是高级别(深层特征)并降采样的feature时,non-local模块中的函数是轻量级的,通过以下两种方式来使得其计算更加高效.
Non-Local模块的实现
对输入的编码操作后通道数均变为原来的一半,包括函数,和,目的是为了减小计算量.non-local模块公式中的![]() 操作通过一个1*1*1的卷积(2.3图片中最顶层的1*1*1的卷积操作)来实现并将卷积结果通道书恢复为与non-local模块的输入相同从而能够进行残差连接操作.
操作通过一个1*1*1的卷积(2.3图片中最顶层的1*1*1的卷积操作)来实现并将卷积结果通道书恢复为与non-local模块的输入相同从而能够进行残差连接操作.
还有另一个降采样操作去减小non-local操作的计算量,首先将2.1中non-local操作的公式重新写为如下形式:
![]()
式子中![]() 是输入降采样后的结果(例如使用池化操作进行降采样).也就是说,在计算non-local操作在每一点的响应值时,不需要当前被计算点和所有点都进行函数的计算,只需要和某些点进行计算即可,这样就可以大大减小计算量,文中表明这种做法并不会改变non-local行为.具体实现可以在2.3中non-local模块图中在和操作后加入池化操作即可.
是输入降采样后的结果(例如使用池化操作进行降采样).也就是说,在计算non-local操作在每一点的响应值时,不需要当前被计算点和所有点都进行函数的计算,只需要和某些点进行计算即可,这样就可以大大减小计算量,文中表明这种做法并不会改变non-local行为.具体实现可以在2.3中non-local模块图中在和操作后加入池化操作即可.
三.试验结果
下面为论文中一部分实验的结果数据:

上图中实例a表示在C2D模型中插入一个non-local模块,但是基于上文中提到的四种不同的函数分别做了实验,并与C2D的baseline进行了对比,发现点积形式的函数效果最好,并且所有使用了non-local模块效果都要由于baseline.
表b展示了分别对基于ResNet50和ResNet101的C2D插入不同数量的non-local模块的实验结果,基于ResNet50的C2D插入10个non-local模块效果最好,基于ResNet101的插入5个和10个non-local模块效果最好.
表d展示了分别在ResNet50以及ResNet101中,分别在时间,空间以及时空维度插入5个non-local模块的结果,发现ResNet50与ResNet101中均在时空维度下插入效果最好.