voc数据集格式转coco数据集格式
做一个项目时,有时候不确定到底那个算法模型在我的数据集上表现最好,所以可能需要跑几个模型然后进行对比分析,但是很多模型对数据集的格式要求不同啊,每次都要被数据转换这个烦人的工作折磨很久......所以在空了的时候决定整理记录一下,也好方便自己下次使用。
本文参考了下面这篇帖子,亲测有效!!!非常感谢。。。将VOC格式的数据集转化为coco格式(python)_奔跑的小仙女的博客-CSDN博客_voc数据集转coco数集 https://blog.csdn.net/qq_43211132/article/details/109508645
https://blog.csdn.net/qq_43211132/article/details/109508645
1.我的VOC数据集目录结构
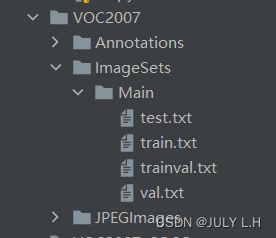
Annotations文件夹里存放的是.xml文件,每张图片的标签信息和位置信息
JPEGImages文件夹存放的是.jpg图片
2.转换后的coco数据集目录结构
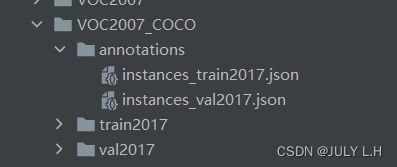
annotations文件夹存放的是划分后的train,val的.json文件
train2017,val2017存放的是对应的.jpg图片
3.转换的python代码
import os
import random
import shutil
import sys
import json
import glob
import xml.etree.ElementTree as ET
"""
修改下面3个参数
1.val_files_num : 验证集的数量
2.test_files_num :测试集的数量
3.voc_annotations : voc的annotations路径
"""
val_files_num = 64
test_files_num = 1
voc_annotations = r'D:\download\PPYOLOE_pytorch-master\VOC2007\Annotations/' # voc的annotations路径
split = voc_annotations.split('/')
coco_name = 'VOC2007'
main_path = r'D:\download\PPYOLOE_pytorch-master' + '/'
# print(main_path)
coco_path = os.path.join(main_path, coco_name + '_COCO/')
coco_images = os.path.join(main_path, coco_name + '_COCO/images')
coco_json_annotations = os.path.join(main_path, coco_name + '_COCO/annotations/')
xml_val = os.path.join(main_path, 'xml', 'xml_val/')
xml_test = os.path.join(main_path, 'xml/', 'xml_test/')
xml_train = os.path.join(main_path, 'xml/', 'xml_train/')
voc_images = os.path.join(main_path, coco_name, 'JPEGImages/')
# from https://www.php.cn/python-tutorials-424348.html
def mkdir(path):
path = path.strip()
path = path.rstrip("\\")
isExists = os.path.exists(path)
if not isExists:
os.makedirs(path)
print(path + ' ----- folder created')
return True
else:
print(path + ' ----- folder existed')
return False
# foler to make, please enter full path
mkdir(coco_path)
mkdir(coco_images)
mkdir(coco_json_annotations)
mkdir(xml_val)
mkdir(xml_test)
mkdir(xml_train)
# voc images copy to coco images
for i in os.listdir(voc_images):
img_path = os.path.join(voc_images + i)
shutil.copy(img_path, coco_images)
# voc images copy to coco images
for i in os.listdir(voc_annotations):
img_path = os.path.join(voc_annotations + i)
shutil.copy(img_path, xml_train)
print("\n\n %s files copied to %s" % (val_files_num, xml_val))
for i in range(val_files_num):
if len(os.listdir(xml_train)) > 0:
random_file = random.choice(os.listdir(xml_train))
# print("%d) %s"%(i+1,random_file))
source_file = "%s/%s" % (xml_train, random_file)
if random_file not in os.listdir(xml_val):
shutil.move(source_file, xml_val)
else:
random_file = random.choice(os.listdir(xml_train))
source_file = "%s/%s" % (xml_train, random_file)
shutil.move(source_file, xml_val)
else:
print('The folders are empty, please make sure there are enough %d file to move' % (val_files_num))
break
for i in range(test_files_num):
if len(os.listdir(xml_train)) > 0:
random_file = random.choice(os.listdir(xml_train))
# print("%d) %s"%(i+1,random_file))
source_file = "%s/%s" % (xml_train, random_file)
if random_file not in os.listdir(xml_test):
shutil.move(source_file, xml_test)
else:
random_file = random.choice(os.listdir(xml_train))
source_file = "%s/%s" % (xml_train, random_file)
shutil.move(source_file, xml_test)
else:
print('The folders are empty, please make sure there are enough %d file to move' % (val_files_num))
break
print("\n\n" + "*" * 27 + "[ Done ! Go check your file ]" + "*" * 28)
START_BOUNDING_BOX_ID = 1
PRE_DEFINE_CATEGORIES = None
"""
main code below are from
https://github.com/Tony607/voc2coco
"""
def get(root, name):
vars = root.findall(name)
return vars
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise ValueError("Can not find %s in %s." % (name, root.tag))
if length > 0 and len(vars) != length:
raise ValueError(
"The size of %s is supposed to be %d, but is %d."
% (name, length, len(vars))
)
if length == 1:
vars = vars[0]
return vars
def get_filename_as_int(filename):
try:
filename = filename.replace("\\", "/")
filename = os.path.splitext(os.path.basename(filename))[0]
return filename
except:
raise ValueError("Filename %s is supposed to be an integer." % (filename))
def get_categories(xml_files):
"""Generate category name to id mapping from a list of xml files.
Arguments:
xml_files {list} -- A list of xml file paths.
Returns:
dict -- category name to id mapping.
"""
classes_names = []
for xml_file in xml_files:
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall("object"):
classes_names.append(member[0].text)
classes_names = list(set(classes_names))
classes_names.sort()
return {name: i for i, name in enumerate(classes_names)}
def convert(xml_files, json_file):
json_dict = {"images": [], "type": "instances", "annotations": [], "categories": []}
if PRE_DEFINE_CATEGORIES is not None:
categories = PRE_DEFINE_CATEGORIES
else:
categories = get_categories(xml_files)
bnd_id = START_BOUNDING_BOX_ID
for xml_file in xml_files:
tree = ET.parse(xml_file)
root = tree.getroot()
path = get(root, "path")
if len(path) == 1:
filename = os.path.basename(path[0].text)
elif len(path) == 0:
filename = get_and_check(root, "filename", 1).text
else:
raise ValueError("%d paths found in %s" % (len(path), xml_file))
## The filename must be a number
image_id = get_filename_as_int(filename)
size = get_and_check(root, "size", 1)
width = int(get_and_check(size, "width", 1).text)
height = int(get_and_check(size, "height", 1).text)
image = {
"file_name": filename,
"height": height,
"width": width,
"id": image_id,
}
json_dict["images"].append(image)
## Currently we do not support segmentation.
# segmented = get_and_check(root, 'segmented', 1).text
# assert segmented == '0'
for obj in get(root, "object"):
category = get_and_check(obj, "name", 1).text
if category not in categories:
new_id = len(categories)
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, "bndbox", 1)
xmin = int(get_and_check(bndbox, "xmin", 1).text) - 1
ymin = int(get_and_check(bndbox, "ymin", 1).text) - 1
xmax = int(get_and_check(bndbox, "xmax", 1).text)
ymax = int(get_and_check(bndbox, "ymax", 1).text)
assert xmax > xmin
assert ymax > ymin
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {
"area": o_width * o_height,
"iscrowd": 0,
"image_id": image_id,
"bbox": [xmin, ymin, o_width, o_height],
"category_id": category_id,
"id": bnd_id,
"ignore": 0,
"segmentation": [],
}
json_dict["annotations"].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {"supercategory": "none", "id": cid, "name": cate}
json_dict["categories"].append(cat)
os.makedirs(os.path.dirname(json_file), exist_ok=True)
json_fp = open(json_file, "w")
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
xml_val_files = glob.glob(os.path.join(xml_val, "*.xml"))
xml_train_files = glob.glob(os.path.join(xml_train, "*.xml"))
convert(xml_val_files, coco_json_annotations + 'instances_val2017.json')
convert(xml_train_files, coco_json_annotations + 'instances_train2017.json')
val_images = os.listdir(xml_val)
tarin_images = os.listdir(xml_train)
# srcfile 需要复制、移动的文件
# dstpath 目的地址
def mymovefile(srcfile, dstpath): # 移动函数
if not os.path.isfile(srcfile):
print("%s not exist!" % (srcfile))
else:
fpath, fname = os.path.split(srcfile) # 分离文件名和路径
if not os.path.exists(dstpath):
os.makedirs(dstpath) # 创建路径
shutil.move(srcfile, dstpath + fname) # 移动文件
print("move %s -> %s" % (srcfile, dstpath + fname))
coco_train = os.path.join(main_path, coco_name + '_COCO')
# os.makedirs(coco_train+"\\train")
os.makedirs(coco_train + "\\val2017")
src_dir = coco_images
dst_dir = coco_train + "/val2017/" # 目的路径记得加斜杠
# src_file_list = coco_images
for val_images_wj in val_images:
val_images_wj = val_images_wj[:-4]
val_images_wj += '.jpg'
val_images_wj = coco_images + '/' + val_images_wj
mymovefile(val_images_wj, dst_dir)
# src_file_list = glob(src_dir + file_name)
train_dir_1 = os.path.join(main_path, coco_name + '_COCO/images')
train_dir_2 = os.path.join(main_path, coco_name + '_COCO/train2017')
if not os.path.exists(train_dir_1):
os.mkdir(train_dir_1)
srcDir = train_dir_1
dstDir = train_dir_2
os.rename(srcDir, dstDir)
shutil.rmtree(main_path + '/xml')