Mybatis/Mybatis-Plus 使用流式查询优化大量数据导出
前言
相信小伙伴们工作当中肯定会经常遇到导出数据的需求,做这个导出需求的话相信大家肯定很多人用easypoi工具包,这个工具包用起来是真的方便,爽。但是如果数据量大,产品又要你导出很多数据,这时候就不爽了,因为如果数据量大的话,服务器配置又不是很高,那么很容易就把服务器导挂了。今天就教大家一招(有能力的小伙伴也可以自行研究使用其它方式优化导出),使用mybatis/mybatis-plus中的流式查询结合阿里的easyexcel做到一边查询一边写入流的方式优化大量数据导出,这样做写入流后的数据内存就可以释放出来,从而降低jvm的内存使用率。
测试
普通导出,JVM垃圾回收图

看看代码:
@RestController
@RequestMapping("/order")
@Slf4j
public class OrderController {
@Autowired
private IOrderService orderService;
@GetMapping("/commonExport")
// http://localhost:9091/api-dev/order/commonExport?orderStatus=2
public void commonExport(QueryOrderDTO queryDTO, HttpServletResponse response) throws InterruptedException {
log.info("======>start download excel");
long start = System.currentTimeMillis();
List orderList = orderService.lambdaQuery()
.eq(Objects.nonNull(queryDTO.getOrderStatus()), Order::getOrderStatus, queryDTO.getOrderStatus()).list();
log.info("======>date query end! begin export");
ExcelUtil.exportExcel("订单信息表","订单信息表","订单信息表",orderList, Order.class,response);
log.info("======>end download excel,use time is {} 秒", (System.currentTimeMillis()-start)/1000.0);
Thread.sleep(10000);
System.gc();
}
} 导出66万多条数据,从查询到导出一共花了141.327秒
在看一下jvm垃圾回收状态: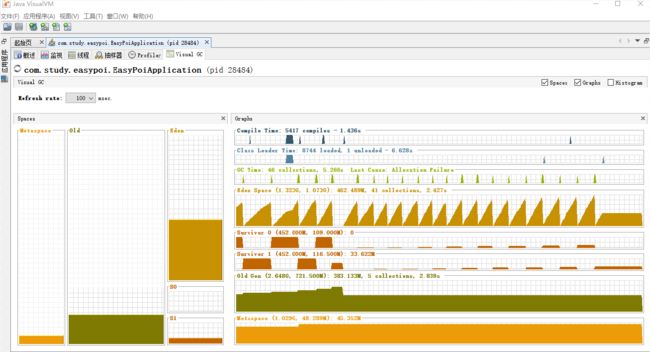
可以看出,eden区垃圾回收很均匀,而且很快。old区的空间也是在均匀的增加。
直接看一下视频:
kk 2021-07-27 18-28-29
流式查询,JVM垃圾回收图
先看代码:
@RestController
@RequestMapping("/order")
@Slf4j
public class OrderController {
@Autowired
private IOrderService orderService;
@GetMapping("/streamExport")
// http://localhost:9091/api-dev/order/streamExport?orderStatus=2
public void streamExport(QueryOrderDTO queryDTO, HttpServletResponse response) throws IOException {
ServletOutputStream out = null;
try {
// 生成EXCEL并指定输出路径
out = response.getOutputStream();
ExcelWriter writer = new ExcelWriter(out, ExcelTypeEnum.XLSX);
// 设置EXCEL名称
String fileName = new String(("订单信息").getBytes(), "UTF-8");
// 设置SHEET
Sheet sheet = new Sheet(1, 0);
sheet.setSheetName("订单信息");
// 设置标题
Table table = new Table(1);
List> titles = new ArrayList>();
titles.add(Arrays.asList("ID"));
titles.add(Arrays.asList("创建人"));
titles.add(Arrays.asList("修改人"));
titles.add(Arrays.asList("创建时间"));
titles.add(Arrays.asList("修改时间"));
titles.add(Arrays.asList("订单ID"));
titles.add(Arrays.asList("订单金额"));
titles.add(Arrays.asList("支付时间"));
titles.add(Arrays.asList("订单状态"));
table.setHead(titles);
log.info("======>stream export excel start excel");
response.setHeader("Content-Disposition", "attachment;filename=" + new String((fileName).getBytes("gb2312"), "ISO-8859-1") + ".xlsx");
response.setContentType("multipart/form-data");
response.setCharacterEncoding("utf-8");
long start = System.currentTimeMillis();
List> orderList = new ArrayList<>(1);
orderService.streamQuery(queryDTO, new ResultHandler() {
@SneakyThrows
@Override
public void handleResult(ResultContext resultContext) {
Order order = resultContext.getResultObject();
orderList.add(Arrays.asList(
order.getId().toString(),order.getCreator(),order.getEditor(),order.getCreateTime().toString(),
order.getOrderId(),order.getAmount().toString(),order.getPaymentTime().toString(),order.getOrderStatus().toString()));
writer.write0(orderList, sheet, table);
orderList.clear();
}
});
writer.finish();
out.flush();
log.info("======>date query end! begin export");
log.info("======>end download excel,use time is {} 秒", (System.currentTimeMillis()-start)/1000.0);
} finally {
if (out != null) {
try {
out.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
} 再补充一下streamQuery方法的实现:
public interface OrderMapper extends BaseMapper {
@Select("select t.* from t_order t where t.order_status = #{map.orderStatus}")
@Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = Integer.MIN_VALUE)
@ResultType(Order.class)
void streamQuery(@Param("map") QueryOrderDTO queryDTO, ResultHandler handler);
} 同样导出66万多条数据,从查询到导出一共花了55.465秒
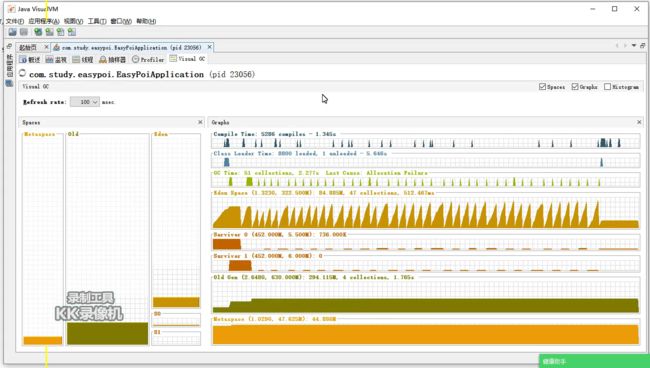
同样看一下流式导出jvm垃圾回收状态:
可以看出,eden区垃圾回收也很均匀,比普通导出更快。old区的空间也是在均匀的增加。但是流式导出eden区占用的内存并不像普通导出那样越来越大。始终稳定维持在最高280M,s0 和 s1 区则更小,都远远小于普通导出。
看一下视频:
kk 2021-07-27 18-35-13
OOM测试
接下来,把jvm最大内存固定,我就设置500M吧。看哪一种会导致OOM。

普通查询导出
kk 2021-07-29 19-39-25
可以看出,普通查询导出的full gc频率很高,eden区,old区内存都用满释放不出来了。所以内存小的话普通查询导出是会导致oom的。
流式查询导出
废话不多说,相同内存分配配置,直接看视频:
kk 2021-07-29 19-51-13
从视频可以看出,流式查询导出没有oom,只是时间有点慢,导出60w数据花了182.378 秒,但是比起程序oom来说,多花点时间也不是啥大事。谁让我们配置内存太小了呢。视频中eden区和old区的内存占用都非常稳定。而且 占用的内存很小 ,流式查询导出大量数据还是很有优势的。
后来我又 测试了分配300M内存 ,普通导出一会就跪了,流式查询居然还能正常导出。只是时间要长一些,不得不说流式查询导出大数据真的很强大啊!!!
结论
通过以上实验可以得出,需要导出大量数据的情况下,使用普通查询导出是因为一次性把所有数据查询出来放在集合中,这时候gc释放不了这一部分内存,就会是堆内存用尽导致程序oom。使 用mybatis的流式查询配合alibaba的easypoi 工具, 一边查询一边导出 ,这样用过的数据写入流之后就可以gc回收掉内存空间,使内存得到合理应用, 避免了oom的发生 。
最后
我后来把导出封装了一下,配合阿里的easyexcel写了一个通用工具类,导出是真的方便!贴一下工具类代码及使用demo:
CommonResultHandler通用抽象类:
import com.alibaba.excel.EasyExcel;
import com.alibaba.excel.ExcelWriter;
import com.alibaba.excel.write.metadata.WriteSheet;
import lombok.Getter;
import lombok.SneakyThrows;
import org.apache.ibatis.session.ResultContext;
import org.apache.ibatis.session.ResultHandler;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* @Description:
* @Date: 2021/7/28 10:22
*/
@Getter
public abstract class CommonResultHandler implements ResultHandler {
protected final HttpServletResponse response;
protected final ExcelWriter writer;
protected WriteSheet sheet;
protected final List rowDataList;
public CommonResultHandler(HttpServletResponse response, Class clazz) throws IOException {
this.response = response;
this.writer = EasyExcel.write(response.getOutputStream(), clazz).build();
rowDataList = new ArrayList<>(1);
this.initSheet();
}
public void initSheet(){
this.sheet = EasyExcel.writerSheet().build();
}
@Override
@SneakyThrows
public void handleResult(ResultContext resultContext){
T obj = resultContext.getResultObject();
rowDataList.add(processing(obj));
writer.write(rowDataList,sheet);
rowDataList.clear();
}
public abstract T processing(T t);
} 导出工具类StremExportUtil:
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
/**
* @Description:
* @Date: 2021/7/28 10:14
*/
public class StremExportUtil {
static ServletOutputStream out = null;
public static void download(String fileName, CommonResultHandler resultHandler) throws IOException {
try {
init(fileName, resultHandler.getResponse());
resultHandler.getWriter().finish();
out.flush();
} finally {
if (out != null) {
try {
out.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
public static void init(String fileName, HttpServletResponse response) throws IOException {
out = response.getOutputStream();
response.setHeader("Content-Disposition", "attachment;filename=" + new String((fileName).getBytes("gb2312"), "ISO-8859-1") + ".xlsx");
response.setContentType("multipart/form-data");
response.setCharacterEncoding("utf-8");
}
}使用demo:
@GetMapping("/utilExport")
public void utilExport(QueryOrderDTO queryDTO, HttpServletResponse response) throws IOException {
CommonResultHandler resultHandler = new CommonResultHandler(response, Order.class) {
@Override
public Order processing(Order order) {
return order;
}
};
orderService.streamQuery(queryDTO, resultHandler);
StremExportUtil.download("hello", resultHandler);
} 再看看streamQuery 方法实现:
public interface OrderMapper extends BaseMapper {
@Select("select t.* from t_order t where t.order_status = #{map.orderStatus}")
@Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = Integer.MIN_VALUE)
@ResultType(Order.class)
void streamQuery(@Param("map") QueryOrderDTO queryDTO, ResultHandler handler);
} 好了,今天的文章就分享到这里,如果有不明白的地方欢迎留言探讨,我会第一时间回复!小伙伴们帮忙点赞哦!