图像质量评价(IQA)综述
文章目录
- 背景介绍
- 方法介绍
-
- 1. CG-DIQA
- 2. A New Document Image Quality Assessment Method Based on Hast Derivation
- 3. Blind quality assessment metric and degradation classification for degraded document images
- 4. SPAQ
- 5. MetaIQA
- 6. Blindly Assess Image Quality in the Wild Guided by A Self-Adaptive Hyper Network
- 7. Assessing Image Quality Issues for Real-World Problems
- 8. TRIQ
- 方法总结
- 数据集总结
- 评价方式
-
- SROCC(Spearman’s rank order correlation coefficient)
- PLCC(Pearson’s linear correlation coefficient)
- MOS(mean opinion score)
- 参考文献
- 参考文章
- 后续更新
背景介绍
对于图像处理领域来讲,一个首要的目标是去提升处理后的图像的质量,而这个质量应该更符合人类的感知,即:如何去评判一个算法所得到的图像是好是坏?这不应该单单是靠着某个指标来决定的,而是应该依赖于人类的观感。 简而言之,这个图像处理算法所得到的结果图片,只有人类看上去感觉更"好看",我们才说 A 是一个好算法。
那接下来得问题是:不能总是靠人来帮助我们构建好的算法,因为人力资源是很昂贵的,因此我们就需要 图像质量评价 (IQA)算法。
我们希望:一个好的图像质量评价 (IQA) 算法,它可以像人一样给出这个结果图是好是坏。 对于一张结果图来说,人感觉它又美又好看,我们的IQA算法就应该给它高分;人感觉它又丑又难看,我们的IQA算法就应该给它低分。
目前的质量评价方法分为三类:
- 全参考 IQA(Full-Reference IQA):输入两张图,一张清晰的图(即 Ground Truth),称为参考图,一张需要评价的图,称为失真图,通过对比两幅图像的信息量或特征相似度来实现质量评价,是研究比较成熟的方向。
- 半参考 IQA(Reduced-Reference IQA):输入一张图,就是要评价的图,它可能是某个图像复原GAN模型生成的图片等等,称为失真图。 在RR问题中给出了失真图像,没有参考图像,但是给了参考图像的部分信息。比如只有原始图像的部分信息或从参考图像中提取的部分特征,此类方法介于FR-IQA和NR-IQA之间,且任何FR-IQA和NR-IQA方法经过适当加工都可以转换成RR-IQA方法。进一步,NR-IQA类算法还可以细分成两类,一类研究特定类型的图像质量,比如估计模糊、块效应、噪声的严重程度,另一类估计非特定类型的图像质量,也就是一个通用的失真评估。一般在实际应用中无法提供参考图像,所以NR-IQA最有实用价值,也有着广泛的应用,使用起来也非常方便,同时,由于图像内容的千变万化并且无参考,也使得NR-IQA成为较难的研究对象。
- 无参考 IQA(No-Reference IQA):输入有1张图, 就是要评价的图,它可能是某个图像复原GAN模型生成的图片等等,我们叫它失真图。 在NR问题中仅给出了失真图像。NR是最难的图像质量评价方法,是近些年的研究热点,也是IQA中最有挑战的问题。
方法介绍
1. CG-DIQA
论文题目:CG-DIQA: No-reference Document Image Quality Assessment Based on Character Gradient [3]
论文地址:https://arxiv.org/abs/1807.04047

ICPR 2018
无参考的 DIQA 方法(CG-DIQA):把输入图像转换为灰度图像,缩放到一个固定尺寸,然后使用 MSER 方法检测候选字符块,计算候选字符的梯度的标准差,最后估计文档图像的质量分数。
优点:
- 由于使用的是传统图像方法,所以不需要大量的训练集
- 不需要参考图像
缺点:
- 此方法只能评价模糊图像的质量分数,对于光照、遮挡等图像的质量分数无法估计
- 无源码
2. A New Document Image Quality Assessment Method Based on Hast Derivation
论文题目:A New Document Image Quality Assessment Method Based on Hast Derivation [4]
论文地址:https://ieeexplore.ieee.org/document/8978126
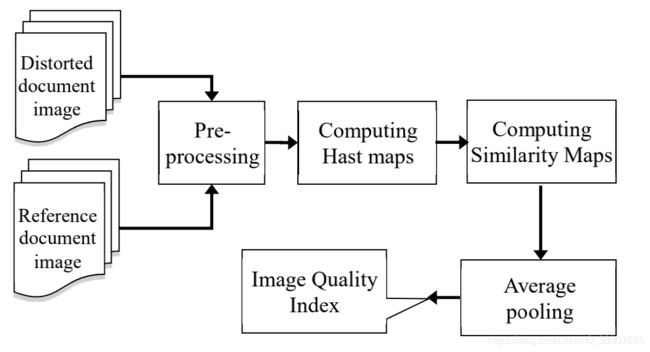
全参考 DIQA 方法(FR-DIQA):首先采用一阶、二阶导数。然后,通过在参考图像和扭曲图像上使用哈斯特过滤器获得的二阶哈斯特衍生图,从而创建一个相似图。最后使用平均池化来获得失真文档图像的质量分数。
优点:
- 传统图像,不需要大量的训练集
缺点:
- 无源码
- 需要参考图像用做参考,才能得到低质量图像的质量分数
3. Blind quality assessment metric and degradation classification for degraded document images
论文题目:Blind quality assessment metric and degradation classification for degraded document images [5]
论文地址:https://www.sciencedirect.com/science/article/abs/pii/S0923596518307501?via%3Dihub
4. SPAQ
论文题目:Perceptual Quality Assessment of Smartphone Photography [1]
论文地址:https://www.sci-hub.ren/10.1109/CVPR42600.2020.00373
代码地址:https://github.com/h4nwei/SPAQ(数据集)
主要介绍了手机照片的数据集 SPAQ ,66 个手机拍的 11125 张图片,都有标注,包括图像质量,图像属性(亮度、色度、对比度、噪声、锐度),场景类别(动物、都市风景、人、风景、内景、夜景、植物、静物、其他)
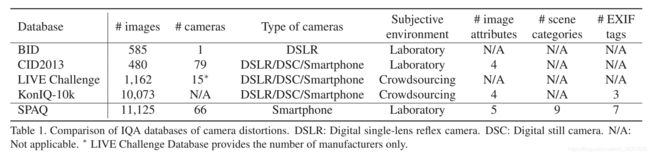
BaseLine:ResNet-50
5. MetaIQA
论文题目:MetaIQA: Deep Meta-learning for No-Reference Image Quality Assessment [6]
论文地址:https://arxiv.org/abs/2004.05508
基于元学习的非参考图像质量评价:可以在各种失真图像上表现良好
利用元学习通过多个特定失真的 NR-IQA 任务查找图像失真的通用规则。通过大量的已知失真类型的 NR-IQA 任务学习一个共享的质量先验,然后用未知的失真类型来微调。
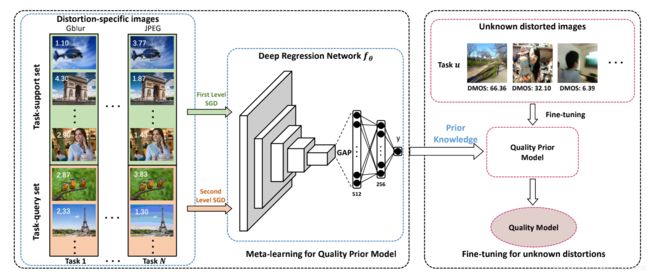
- 利用大量特定失真的 NR-IQA 任务建立一个元训练集(支持集和查询集),使用从支持集到查询集的两级梯度下降方法讯息质量先验模型。
- 在一个目标 NR-IQA 任务上微调质量先验模型,获得质量模型
合成数据集

优点:
- 可以应对几乎所有失真图像
- 需要数据少量
缺点:
- 无源码,训练复杂
6. Blindly Assess Image Quality in the Wild Guided by A Self-Adaptive Hyper Network
论文题目:Blindly Assess Image Quality in the Wild Guided by A Self-Adaptive Hyper Network [7]
论文地址:https://www.sci-hub.ren/10.1109/CVPR42600.2020.00372
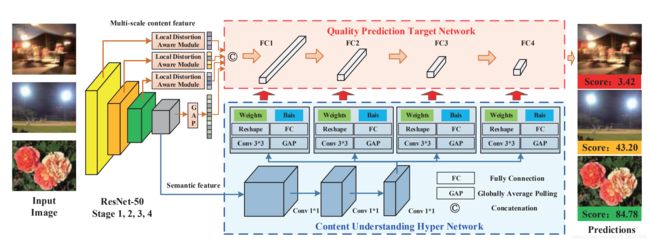
根据图像内容自适应预测图像质量:分为三个部分
- 主干网络:提取语义特征
- 目标网络:预测图像质量
- 超网络:为目标网络生成一系列自适应参数
使用主干网路提取图像语义特征后,通过超网络自适应建立感知线索,然后通过质量预测网络输出质量分数。
数据集:
合成:LIVE、TID2013、CSIQ
真实:LIVE Challenge、KonIQ-10k
优点:
- 根据图像内容预测图像质量,更符合文档图像
- 效果比前边的几个方法都好
- 无参考图像质量评价
缺点:
- 无源码
7. Assessing Image Quality Issues for Real-World Problems
论文名称:Assessing Image Quality Issues for Real-World Problems [2]
论文地址:https://arxiv.org/abs/2003.12511
数据集地址:https://vizwiz.org
介绍了一个大尺度数据集 VizWiz-QualityIssues(39181张图片),与图像质量评价相关联的两个视觉任务:图像字幕和视觉问答。
8. TRIQ
论文题目:Transformer for Image Quality Assessment [14]
论文地址:https://arxiv.org/abs/2101.01097
代码地址:https://github.com/junyongyou/triq

方法总结
传统方法只能针对某一种特定的失真类型做质量评分,不具有泛化性。
深度学习方法比传统图像方法更加泛化,更加鲁棒。经过分析,方法 TRIQ 和 Blindly Assess Image Quality in the Wild Guided by A Self-Adaptive Hyper Network 在公共数据集上的效果比较好。
数据集总结
合成数据集:TID2013[12]、KADID-10K、CSIQ[13]
真实数据集:BID[8]、CID13[9]、LIVE Challenge[10]、KonIQ-10k[11]、SPAQ[1]、VizWiz-QualityIssues[2]
评价方式
衡量图像质量评估结果的指标有很多,每种指标都有自己的特点,通常比较模型客观值与观测的主观值之间的差异和相关性。常见的 2 种评估指标是Spearman秩相关系数 (Spearman’s Rank Order Correlation Coefficient, SROCC) 和线性相关系数 (Linear Correlation Coefficient, LCC) 。LCC也叫Pearson相关系数 (PLCC) ,描述了主、客观评估之间的线性相关性,定义如下
SROCC(Spearman’s rank order correlation coefficient)
SROCC衡量算法预测的单调性
S R O C C = 1 − 6 ∑ i − 1 N ( v i − p i ) 2 N ( N 2 − 1 ) SROCC = 1 - \frac{6 \sum_{i-1}^N(v_i - p_i)^2}{N(N^2 - 1)} SROCC=1−N(N2−1)6∑i−1N(vi−pi)2
其中 v i v_i vi、 p i p_i pi 分别表示 y i y_i yi、 y ^ i \hat{y}_i y^i 在真实值和预测值序列中的排序位置。
这个指标我们可以这样来理解:假设现在有 N N N 张图片,IQA 算法为它们打分,排名分别是 1 , 2 , . . . , N 1,2,...,N 1,2,...,N。而与此同时人类也为它们来打分,排名分别是 1 , 2 , . . . , N 1,2,...,N 1,2,...,N 。
假设现在如果这个IQA算法很完美,则IQA算法的排名应该是与真人的排名一致,即有: v 1 = p 1 , v 2 = p 2 , . . . , v N = p N v_1=p_1, v_2=p_2, ..., v_N= p_N v1=p1,v2=p2,...,vN=pN,此时带入公式计算得SROCC=1。
假设现在如果这个IQA算法很差劲,则IQA算法的排名应该是与真人的排名刚好完全相反,即人类认为好的图片,IQA算法认为很差,即有: v 1 = p N , v 2 = p N − 1 , . . . , v N = p 1 v_1=p_N, v_2=p_{N-1}, ..., v_N= p_1 v1=pN,v2=pN−1,...,vN=p1,此时带入公式计算得SROCC=-1。
PLCC(Pearson’s linear correlation coefficient)
P L C C = ∑ i = 1 N ( y i − y ˉ ) ( y i ^ − y ^ ˉ ) ∑ i = 1 N ( y i − y ˉ ) 2 ∑ i = 1 N ( y ^ i − y ^ ˉ ) 2 PLCC = \frac{\sum_{i=1}^N(y_i - \bar{y})(\hat{y_i} - \bar{\hat{y}})}{\sqrt{\sum_{i=1}^N(y_i - \bar{y})^2} \sqrt{\sum_{i=1}^N(\hat{y}_i - \bar{\hat{y}})^2} } PLCC=∑i=1N(yi−yˉ)2∑i=1N(y^i−y^ˉ)2∑i=1N(yi−yˉ)(yi^−y^ˉ)
其中 N N N 表示失真图像数, y i y_i yi、 y i ^ \hat{y_i} yi^ 分别是第 i 幅图像真实值和预测分数, y ˉ \bar{y} yˉ、 y ^ ˉ \bar{\hat{y}} y^ˉ 分别表示真实平均值和预测平均值。
PLCC 衡量的其实是 y i − y ˉ y_i - \bar{y} yi−yˉ 和 y i ^ − y ^ ˉ \hat{y_i} - \bar{\hat{y}} yi^−y^ˉ 这两个向量之间的相似性。这两个向量越相似则 PLCC 的值越接近于 1,代表人类平均主观评分和客观IQA模型预测值之间的相关性越高,即我们的IQA模型越好。
MOS(mean opinion score)
M O S = ∑ x ∈ [ 1 , 2 , 3 , 4 , 5 ] x ⋅ p ( x ) MOS = \sum_{x\in[1,2,3,4,5]} x \cdot p(x) MOS=x∈[1,2,3,4,5]∑x⋅p(x)
1=bad, 2 = poor, 3 = fair, 4 = good, 5 = excellent
除此之外,还有Kendall秩相关系数(Kendall Rank Order Correlation Coefficient, KROCC),均方根误差(Root Mean Square Error, RMSE)等评估指标。KROCC的性质和SROCC一样,也衡量了算法预测的单调性。RMSE计算MOS与算法预测值之间的绝对误差,衡量算法预测的准确性。
参考文献
[1] Yuming Fang, Hanwei Zhu, Yan Zeng, Kede Ma, Zhou Wang: Perceptual Quality Assessment of Smartphone Photography. CVPR 2020: 3674-3683 论文地址 代码地址 百度网盘
[2] Tai-Yin Chiu, Yinan Zhao, Danna Gurari: Assessing Image Quality Issues for Real-World Problems. CVPR 2020: 3643-3653 论文地址 数据集地址
[3] Hongyu Li, Fan Zhu, Junhua Qiu: CG-DIQA: No-Reference Document Image Quality Assessment Based on Character Gradient. ICPR 2018: 3622-3626 论文地址
[4] Alireza Alaei: A New Document Image Quality Assessment Method Based on Hast Derivations. ICDAR 2019: 1244-1249 论文地址
[5] Atena Shahkolaei, Azeddine Beghdadi, Mohamed Cheriet: Blind quality assessment metric and degradation classification for degraded document images. Signal Process. Image Commun. 76: 11-21 (2019) 论文地址
[6] Hancheng Zhu, Leida Li, Jinjian Wu, Weisheng Dong, Guangming Shi: MetaIQA: Deep Meta-Learning for No-Reference Image Quality Assessment. CVPR 2020: 14131-14140 论文地址
[7] Shaolin Su, Qingsen Yan, Yu Zhu, Cheng Zhang, Xin Ge, Jinqiu Sun, Yanning Zhang: Blindly Assess Image Quality in the Wild Guided by a Self-Adaptive Hyper Network. CVPR 2020: 3664-3673 论文地址
[8] A. Ciancio, C. A. Da, S. E. Da, A. Said, R. Samadani, and P. Obrador. No-reference blur assessment of digital pictures based on multifeature classififiers. IEEE Transactions on Image Processing, 20(1):64–75, Jan. 2010. 论文地址
[9] V. Toni, N. Mikko, V. Mikko, O. Pirkko, and H. Jukka. CID2013: A database for evaluating no-reference image quality assessment algorithms. IEEE Transactions on Image Processing, 24(1):390–402, Jan. 2015. 论文地址
[10] D. Ghadiyaram and A. C. Bovik. Massive online crowd sourced study of subjective and objective picture quality. IEEE Transactions on Image Processing, 25(1):372–387, Jan. 2016 论文地址 数据集地址
[11] V. Hosu, H. Lin, T. Sziranyi, and D. Saupe. KonIQ-10k: An ecologically valid database for deep learning of blind image quality assessment. CoRR, abs/1910.06180, 2019. 论文地址 数据集地址
[12] N. Ponomarenko, L. Jin, O. Ieremeiev, V. Lukin, K. Egiazar ian, J. Astola, B. Vozel, K. Chehdi, M. Carli, F. Battisti, and C.-C. J. Kuo. Image database TID2013: Peculiarities, results and perspectives. Signal Processing: Image Communication, 30:57–77, Jan. 2015. 论文地址 数据集地址 百度网盘
[13] E. C. Larson and D. M. Chandler. Most apparent distortion:Full-reference image quality assessment and the role of strategy. SPIE Journal of Electronic Imaging, 19(1):1–21, Jan.2010. 论文地址 数据集地址
[14] Junyong You, Jari Korhonen:Transformer for Image Quality Assessment. CoRR abs/2101.01097 (2021) 论文地址 代码地址
参考文章
搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了(十一)
后续更新
图像质量评价研究综述——从失真的角度