浏览器输入URL后发生了什么?
文章目录
- URL 解析
- DNS域名解析
- 建立TCP连接
- 发送HTTP请求
- 处理并响应HTTP请求
- 浏览器渲染页面
- 关闭TCP连接
URL 解析
URL(Uniform Resource Locator),统一资源定位符,用于定位互联网上资源,俗称网址。
地址格式:scheme://host.domain:port/path/filename
各部分解释如下:
- scheme: 定义因特网服务的类型。常见的协议有 http、https、ftp、file,其中最常见的类型是 http,而 https 则是进行加密的网络传输
- host :定义域主机(http 的默认主机是 www)
- domain :定义因特网域名,比如w3school.com.cn
- port :定义主机上的端口号(http 的默认端口号是 80)
- path :定义服务器上的路径(如果省略,则文档必须位于网站的根目录中)
- filename: 定义文档/资源的名称
这里我们只考虑输入的是一个URL 结构字符串,如果是非 URL 结构的字符串,则会用浏览器默认的搜索引擎搜索该字符串。
DNS域名解析
在浏览器输入网址后,首先要经过域名解析,因为浏览器并不能直接通过域名找到对应的服务器,而是要通过 IP 地址。
IP 地址: 是指互联网协议地址,是 IP Address 的缩写。IP 地址是 IP 协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。IP 地址是一个 32 位的二进制数,比如 127.0.0.1 为本机 IP。
域名:就相当于 IP 地址乔装打扮的伪装者,带着一副面具。它的作用就是便于记忆和沟通的一组服务器的地址。用户通常使用主机名或域名来访问对方的计算机,而不是直接通过 IP 地址访问。
因为与 IP 地址的一组纯数字相比,用字母配合数字的表示形式来指定计算机名更符合人类的记忆习惯。但要让计算机去理解名称,相对而言就变得困难了。因为计算机更擅长处理一长串数字。为了解决上述的问题,DNS 服务应运而生。
域名解析:
DNS 协议提供通过域名查找 IP 地址,或逆向从 IP 地址反查域名的服务。DNS 是一个网络服务器,我们的域名解析简单来说就是在 DNS 上记录一条信息记录。
DNS 服务器是高可用、高并发和分布式的,它是树状结构,如图:
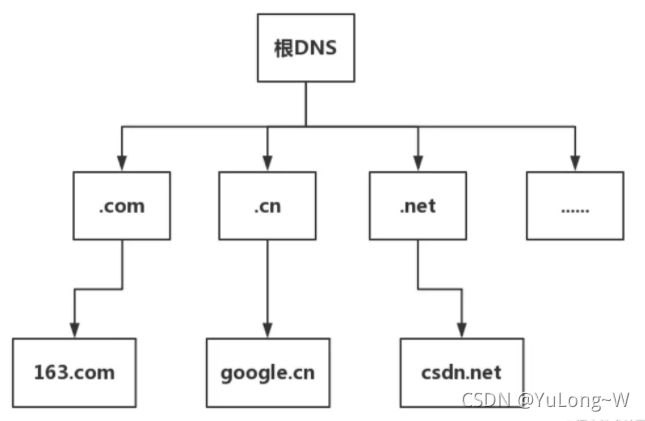
- 根 DNS 服务器 :返回顶级域 DNS 服务器的 IP 地址
- 顶级域 DNS 服务器:返回权威 DNS 服务器的 IP 地址 权威
- DNS 服务器 :返回相应主机的 IP 地址
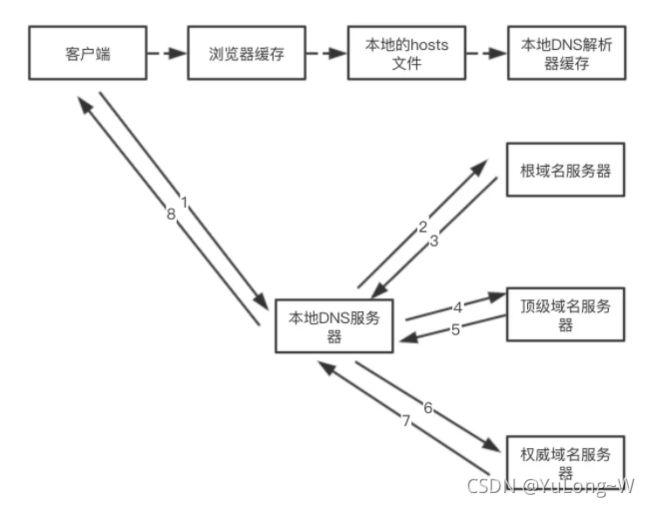
DNS的域名查找,在客户端和浏览器,本地DNS之间的查询方式是递归查询;在本地DNS服务器与根域及其子域之间的查询方式是迭代查询;
- 递归查询:在客户端输入 URL 后,会有一个递归查找的过程,从 浏览器缓存中查找->本地的hosts文件查找->找本地DNS解析器缓存查找->本地DNS服务器查找,这个过程中任何一步找到了都会结束查找流程。
- 迭代查询:如果本地DNS服务器无法查询到,则根据本地DNS服务器设置的转发器进行查询。若未用转发模式,则迭代查找过程
结合的过程:
在查找过程中,有以下优化点:
DNS存在着多级缓存,从离浏览器的距离排序的话,有以下几种: 浏览器缓存,系统缓存,路由器缓存,IPS服务器缓存,根域名服务器缓存,顶级域名服务器缓存,主域名服务器缓存。
在域名和 IP 的映射过程中,给了应用基于域名做负载均衡的机会,可以是简单的负载均衡,也可以根据地址和运营商做全局的负载均衡。
建立TCP连接
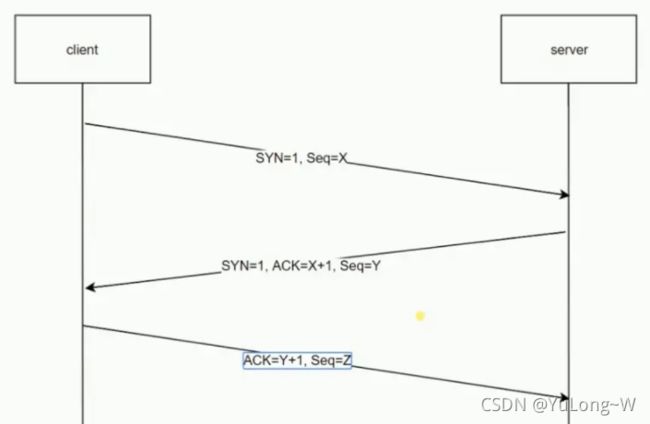
TCP三次握手:
在客户端发送数据之前会发起 TCP 三次握手用以同步客户端和服务端的序列号和确认号,并交换 TCP 窗口大小信息。
TCP 三次握手的过程如下:
- 客户端发送一个带 SYN=1,Seq=X 的数据包到服务器端口(第一次握手,由浏览器发起,告诉服务器我要发送请求了)
- 服务器发回一个带 SYN=1, ACK=X+1, Seq=Y 的响应包以示传达确认信息(第二次握手,由服务器发起,告诉浏览器我准备接受了,你赶紧发送吧)
- 客户端再回传一个带 ACK=Y+1, Seq=Z 的数据包,代表“握手结束”(第三次握手,由浏览器发送,告诉服务器,我马上就发了,准备接受吧)
- ACK:此标志表示应答域有效,就是说前面所说的TCP应答号将会包含在TCP数据包中;有两个取值:0和1,为1的时候表示应答域有效,反之为0。TCP协议规定,只有ACK=1时有效,也规定连接建立后所有发送的报文的ACK必须为1。
- SYN(SYNchronization):在连接建立时用来同步序号。当SYN=1而ACK=0时,表明这是一个连接请求报文。对方若同意建立连接,则应在响应报文中使SYN=1和ACK=1。 因此, SYN置1就表示这是一个连接请求或连接接受报文。
发送HTTP请求
TCP 三次握手结束后,开始发送 HTTP 请求报文。 请求报文由请求行(request line)、请求头(header)、请求体(body) 四个部分组成
1、请求行包含请求方法、URL、协议版本
例如: POST /chapter17/user.html HTTP/1.1
- 请求方法包含 8 种:GET、POST、PUT、DELETE、HEAD、TRACE、CONNECT、OPTIONS
| 请求方法 | 作用 |
|---|---|
| GET | 请求获取URI所标识的资源 |
| POST | 请求URI所标识的资源,并请求服务器接收附加在请求后面的数据,常用于表单提交。 |
| PUT | 请求服务器存储一个资源,并用URI作为其标识 |
| DELETE | 请求服务器删除URI所标识的资源 |
| HEAD | 请求获取由URI所标识的资源的响应消息报头 |
| TRACE | 请求服务器回送收到的请求信息,主要用于测试或诊断 |
| CONNECT | 一般开发中用不到,主要是把服务器作为跳板,用作HTTP代理 |
| OPTIONS | 请求查询服务器的性能,或者查询与资源相关的选项和需求 |
- URL 即请求地址,由<协议>://<主机>:<端口>/<路径>?<参数> 组成
- 协议版本即 http 版本号
2、请求头包含请求的附加信息,由关键字 / 值对组成,每行一对,关键字和值用英文冒号“:”分隔。
请求头部通知服务器有关于客户端请求的信息。它包含许多有关的客户端环境和请求正文的有用信息。其中比如:Host,表示主机名,虚拟主机;Connection,HTTP/1.1 增加的,使用 keepalive,即持久连接,一个连接可以发多个请求;User-Agent,请求发出者,兼容性以及定制化需求。
| 请求头 | 解释 |
|---|---|
| Accept | 指定浏览器或其他客户程序能够处理的MIME类型:request.getHeader(“Accept”); |
| Accept-Charse | 使用的字符集,如ISO-8859-1 |
| Accept-Encoding | 客户端能够处理的编码类型,如gzip或compress |
| Accept-Language | 客户端的首选语言 |
| Authorization | 客户用这个报头来标识自己的身份 |
| Connnection | 标明客户是否能够处理持续性HTTP连接。持续性连接允许客户或者浏览器在单个socket中读取多个文件,从而节省协商几个独立连接所需的开销 |
| Content-Length | 只适用于POST请求,用来给定POST数据的大小,以字节为单位:request.getContentLength |
| Cookie | 向服务器返回cookie,这些cookie是之前由服务器发送给浏览器的:request.getCookies |
| Host | 标明原始URL中给出的主机名和端口号 |
| If-Modified-Since | 仅当页面在指定日期之后发生改变的情况下,客户程序才希望获取该页面。如果没有更新的结果,则服务器发送304报头。这个选项十分有用,因为使用它,浏览器可以缓存文档,只在它们发生改变时才通过网络重新载入它们 |
| Referer | 标明引用Web页面的URL |
| User-Agent | 求的浏览器或者其他客户程序 |
3、请求体,可以承载多个请求参数的数据,包含回车符、换行符和请求数据,并不是所有请求都具有请求数据。
例如:name=tom&password=1234&realName=tomson
处理并响应HTTP请求
接受 TCP 报文后,会对连接进行处理,对HTTP协议进行解析(请求方法、域名、路径等),并且进行一些验证:
- 验证是否配置虚拟主机
- 验证虚拟主机是否接受此方法
- 验证该用户可以使用该方法(根据 IP 地址、身份信息等)
HTTP 响应报文:
响应报文由 响应行(request line)、响应头部(header)、响应主体(body) 三个部分组成
1、响应行包含:协议版本,状态码,状态码描述
状态码规则如下:
| 状态码 | 作用 |
|---|---|
| 1xx | 指示信息–表示请求已接收,继续处理 |
| 2xx | 成功–表示请求已被成功接收、理解、接受 |
| 3xx | 重定向–要完成请求必须进行更进一步的操作 |
| 4xx | 客户端错误–请求有语法错误或请求无法实现 |
| 5xx | 服务器端错误–服务器未能实现合法的请求 |
2、响应头部包含响应报文的附加信息,由 名 / 值对 组成
| 响应头 | 作用 |
|---|---|
| Allow | 指定服务器支持的请求方法(GET,POST等) |
| Cache-Control | 告诉浏览器或者其他客户,什么环境可以安全地缓存文档 |
| Connection | close值,指定浏览器不用使用持续性的HTTP连接 |
| Content-Disposition | 要求浏览器询问客户,将响应存储在磁盘上给定名称的文件中 |
| Content-Encoding | 标明页面在传输过程中所使用的编码方式 |
| Content-Language | 文档使用的语言 |
| Content-Length | 响应中的字节 |
| Content-Type | MIME |
| Expires | 规定内容的过期时间,从而不再需要继续缓存:response.setDataHeader(“Expires”, Time) |
| Last-Modified | 标明文件最后的修改时间 |
| Location | 300-399之间的所有响应都应该包括这个报头,它通知浏览器文档的地址 |
| Refresh | 标明浏览器应该多长时间之后请求最新的页面:response.setIntHeader(“Refresh”, 30) |
| Set-Cookie | 指定一个同页面相关的cookie |
3、响应主体包含回车符、换行符和响应返回数据,并不是所有响应报文都有响应数据
浏览器渲染页面
浏览器解析渲染页面分为一下五个步骤:
- 根据 HTML 解析出 DOM 树
- 根据 CSS 解析生成 CSS 规则树
- 结合 DOM 树和 CSS 规则树,生成渲染树
- 根据渲染树计算每一个节点的信息
- 根据计算好的信息绘制页面
1.根据 HTML 解析 DOM 树
- 根据 HTML 的内容,将标签按照结构解析成为 DOM 树,DOM树解析的过程是一个深度优先遍历。即先构建当前节点的所有子节点,再构建下一个兄弟节点。
- 在读取 HTML 文档,构建 DOM 树的过程中,若遇到 script 标签,则 DOM 树的构建会暂停,直至脚本执行完毕。
2.根据 CSS 解析生成 CSS 规则树
- 解析 CSS 规则树时 js 执行将暂停,直至 CSS 规则树就绪。
- 浏览器在 CSS 规则树生成之前不会进行渲染。
3.结合 DOM 树和 CSS 规则树,生成渲染树
- DOM 树和 CSS 规则树全部准备好了以后,浏览器才会开始构建渲染树。
- 精简 CSS 并可以加快 CSS 规则树的构建,从而加快页面相应速度。
4.根据渲染树计算每一个节点的信息(布局)
- 布局:通过渲染树中渲染对象的信息,计算出每一个渲染对象的位置和尺寸
- 回流:在布局完成后,发现了某个部分发生了变化影响了布局,那就需要倒回去重新渲染。
5.根据计算好的信息绘制页面
- 绘制阶段,系统会遍历呈现树,并调用呈现器的“paint”方法,将呈现器的内容显示在屏幕上。
- 重绘:某个元素的背景颜色,文字颜色等,不影响元素周围或内部布局的属性,将只会引起浏览器的重绘。
- 回流:某个元素的尺寸发生了变化,则需重新计算渲染树,重新渲染。
关闭TCP连接
当数据传送完毕,需要断开 TCP 连接,此时发起 TCP 四次挥手。
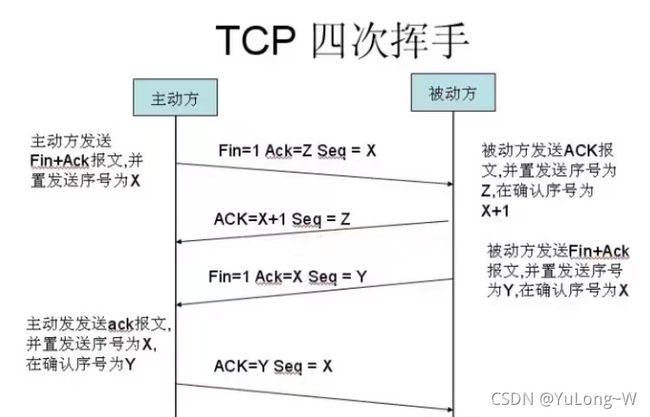
- 发起方向被动方发送报文,Fin、Ack、Seq,表示已经没有数据传输了。并进入 FIN_WAIT_1状态。(第一次挥手:由浏览器发起的,发送给服务器,我请求报文发送完了,你准备关闭吧)
- 被动方发送报文,Ack、Seq,表示同意关闭请求。此时主机发起方进入 FIN_WAIT_2状态。(第二次挥手:由服务器发起的,告诉浏览器,我请求报文接受完了,我准备关闭了,你也准备吧)
- 被动方向发起方发送报文段,Fin、Ack、Seq,请求关闭连接。并进入 LAST_ACK状态。(第三次挥手:由服务器发起,告诉浏览器,我响应报文发送完了,你准备关闭吧)
- 发起方向被动方发送报文段,Ack、Seq。然后进入等待 TIME_WAI 状态。被动方收到发起方的报文段以后关闭连接。发起方等待一定时间未收到回复,则正常关闭。(第四次挥手:由浏览器发起,告诉服务器,我响应报文接受完了,我准备关闭了,你也准备吧)
参考文章:
从URL输入到页面展现到底发生什么?
细说浏览器输入URL后发生了什么